 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Large Language Models for Hardware Verification: A Novel SystemVerilog Assertion Dataset
Mar 11, 2025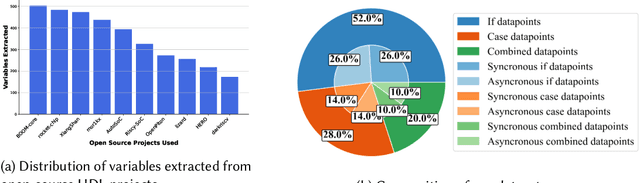
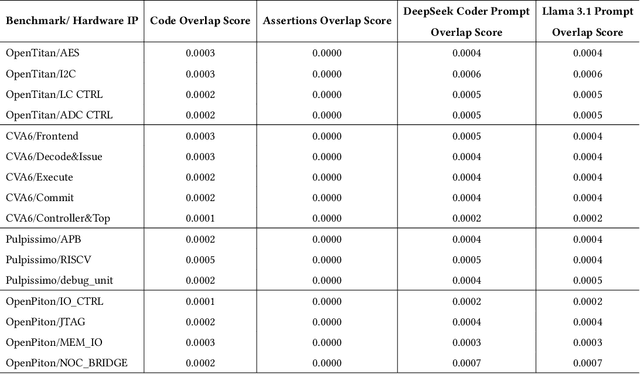
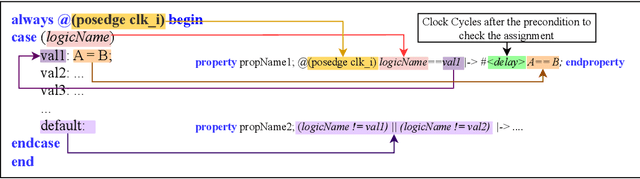
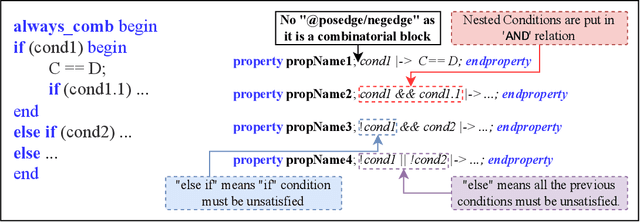
Hardware verification is crucial in modern SoC design, consuming around 70% of development time. SystemVerilog assertions ensure correct functionality. However, existing industrial practices rely on manual efforts for assertion generation, which becomes increasingly untenable as hardware systems become complex. Recent research shows that Large Language Models (LLMs) can automate this process. However, proprietary SOTA models like GPT-4o often generate inaccurate assertions and require expensive licenses, while smaller open-source LLMs need fine-tuning to manage HDL code complexities. To address these issues, we introduce **VERT**, an open-source dataset designed to enhance SystemVerilog assertion generation using LLMs. VERT enables researchers in academia and industry to fine-tune open-source models, outperforming larger proprietary ones in both accuracy and efficiency while ensuring data privacy through local fine-tuning and eliminating costly licenses. The dataset is curated by systematically augmenting variables from open-source HDL repositories to generate synthetic code snippets paired with corresponding assertions. Experimental results demonstrate that fine-tuned models like Deepseek Coder 6.7B and Llama 3.1 8B outperform GPT-4o, achieving up to 96.88% improvement over base models and 24.14% over GPT-4o on platforms including OpenTitan, CVA6, OpenPiton and Pulpissimo. VERT is available at https://github.com/AnandMenon12/VERT.
GraNNite: Enabling High-Performance Execution of Graph Neural Networks on Resource-Constrained Neural Processing Units
Feb 10, 2025

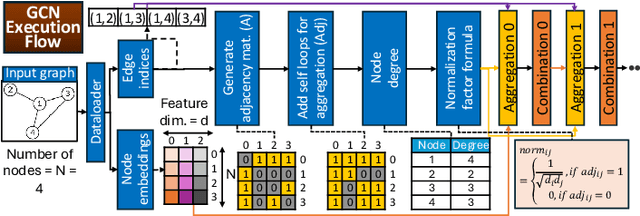

Graph Neural Networks (GNNs) are vital for learning from graph-structured data, enabling applications in network analysis, recommendation systems, and speech analytics. Deploying them on edge devices like client PCs and laptops enhances real-time processing, privacy, and cloud independence. GNNs aid Retrieval-Augmented Generation (RAG) for Large Language Models (LLMs) and enable event-based vision tasks. However, irregular memory access, sparsity, and dynamic structures cause high latency and energy overhead on resource-constrained devices. While modern edge processors integrate CPUs, GPUs, and NPUs, NPUs designed for data-parallel tasks struggle with irregular GNN computations. We introduce GraNNite, the first hardware-aware framework optimizing GNN execution on commercial-off-the-shelf (COTS) SOTA DNN accelerators via a structured three-step methodology: (1) enabling NPU execution, (2) optimizing performance, and (3) trading accuracy for efficiency gains. Step 1 employs GraphSplit for workload distribution and StaGr for static aggregation, while GrAd and NodePad handle dynamic graphs. Step 2 boosts performance using EffOp for control-heavy tasks and GraSp for sparsity exploitation. Graph Convolution optimizations PreG, SymG, and CacheG reduce redundancy and memory transfers. Step 3 balances quality versus efficiency, where QuantGr applies INT8 quantization, and GrAx1, GrAx2, and GrAx3 accelerate attention, broadcast-add, and SAGE-max aggregation. On Intel Core Ultra AI PCs, GraNNite achieves 2.6X to 7.6X speedups over default NPU mappings and up to 8.6X energy gains over CPUs and GPUs, delivering 10.8X and 6.7X higher performance than CPUs and GPUs, respectively, across GNN models.
XAMBA: Enabling Efficient State Space Models on Resource-Constrained Neural Processing Units
Feb 10, 2025State-Space Models (SSMs) have emerged as efficient alternatives to transformers for sequential data tasks, offering linear or near-linear scalability with sequence length, making them ideal for long-sequence applications in NLP, vision, and edge AI, including real-time transcription, translation, and contextual search. These applications require lightweight, high-performance models for deployment on resource-constrained devices like laptops and PCs. Designing specialized accelerators for every emerging neural network is costly and impractical; instead, optimizing models for existing NPUs in AI PCs provides a scalable solution. To this end, we propose XAMBA, the first framework to enable and optimize SSMs on commercial off-the-shelf (COTS) state-of-the-art (SOTA) NPUs. XAMBA follows a three-step methodology: (1) enabling SSMs on NPUs, (2) optimizing performance to meet KPI requirements, and (3) trading accuracy for additional performance gains. After enabling SSMs on NPUs, XAMBA mitigates key bottlenecks using CumBA and ReduBA, replacing sequential CumSum and ReduceSum operations with matrix-based computations, significantly improving execution speed and memory efficiency. Additionally, ActiBA enhances performance by approximating expensive activation functions (e.g., Swish, Softplus) using piecewise linear mappings, reducing latency with minimal accuracy loss. Evaluations on an Intel Core Ultra Series 2 AI PC show that XAMBA achieves up to 2.6X speed-up over the baseline. Our implementation is available at https://github.com/arghadippurdue/XAMBA.