 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIDE: GenAI Units In Digital Design Education
Mar 18, 2026GenAI Units In Digital Design Education (GUIDE) is an open courseware repository with runnable Google Colab labs and other materials. We describe the repository's architecture and educational approach based on standardized teaching units comprising slides, short videos, runnable labs, and related papers. This organization enables consistency for both the students' learning experience and the reuse and grading by instructors. We demonstrate GUIDE in practice with three representative units: VeriThoughts for reasoning and formal-verification-backed RTL generation, enhanced LLM-aided testbench generation, and LLMPirate for IP Piracy. We also provide details for four example course instances (GUIDE4ChipDesign, Build your ASIC, GUIDE4HardwareSecurity, and Hardware Design) that assemble GUIDE units into full semester offerings, learning outcomes, and capstone projects, all based on proven materials. For example, the GUIDE4HardwareSecurity course includes a project on LLM-aided hardware Trojan insertion that has been successfully deployed in the classroom and in Cybersecurity Games and Conference (CSAW), a student competition and academic conference for cybersecurity. We also organized an NYU Cognichip Hackathon, engaging students across 24 international teams in AI-assisted RTL design workflows. The GUIDE repository is open for contributions and available at: https://github.com/FCHXWH823/LLM4ChipDesign.
COBRA: Catastrophic Bit-flip Reliability Analysis of State-Space Models
Dec 22, 2025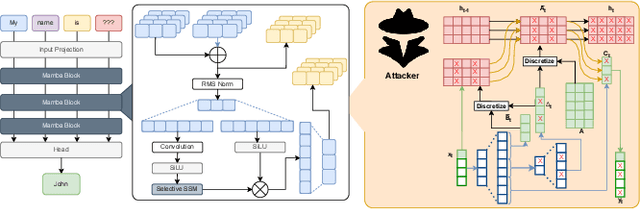
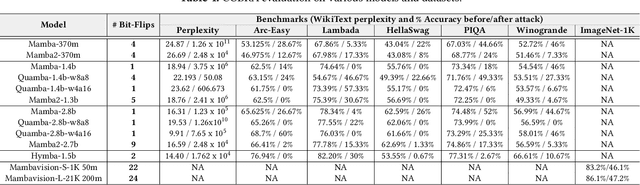
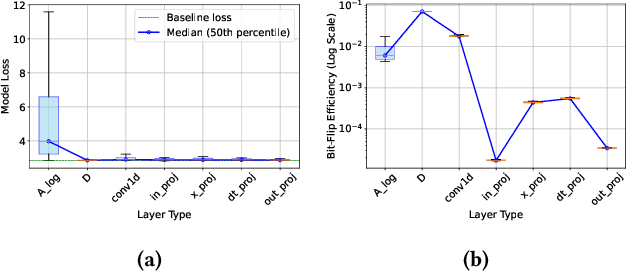
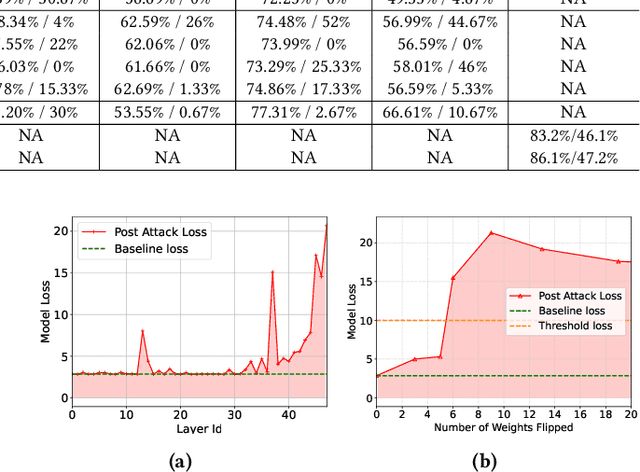
State-space models (SSMs), exemplified by the Mamba architecture, have recently emerged as state-of-the-art sequence-modeling frameworks, offering linear-time scalability together with strong performance in long-context settings. Owing to their unique combination of efficiency, scalability, and expressive capacity, SSMs have become compelling alternatives to transformer-based models, which suffer from the quadratic computational and memory costs of attention mechanisms. As SSMs are increasingly deployed in real-world applications, it is critical to assess their susceptibility to both software- and hardware-level threats to ensure secure and reliable operation. Among such threats, hardware-induced bit-flip attacks (BFAs) pose a particularly severe risk by corrupting model parameters through memory faults, thereby undermining model accuracy and functional integrity. To investigate this vulnerability, we introduce RAMBO, the first BFA framework specifically designed to target Mamba-based architectures. Through experiments on the Mamba-1.4b model with LAMBADA benchmark, a cloze-style word-prediction task, we demonstrate that flipping merely a single critical bit can catastrophically reduce accuracy from 74.64% to 0% and increase perplexity from 18.94 to 3.75 x 10^6. These results demonstrate the pronounced fragility of SSMs to adversarial perturbations.
Enhancing Large Language Models for Hardware Verification: A Novel SystemVerilog Assertion Dataset
Mar 11, 2025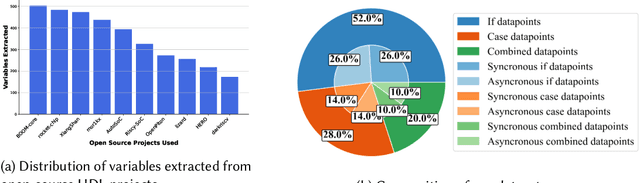
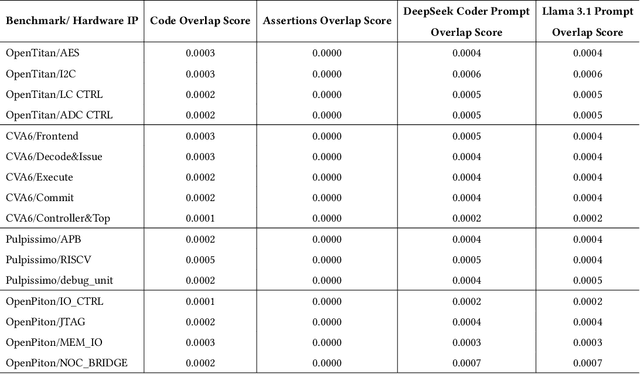
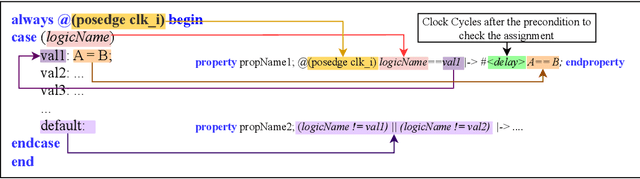
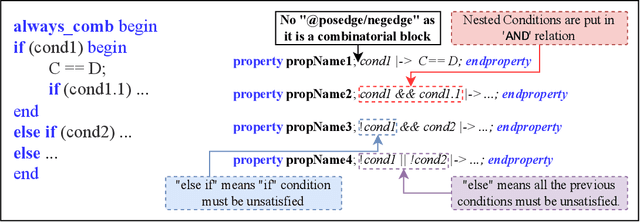
Hardware verification is crucial in modern SoC design, consuming around 70% of development time. SystemVerilog assertions ensure correct functionality. However, existing industrial practices rely on manual efforts for assertion generation, which becomes increasingly untenable as hardware systems become complex. Recent research shows that Large Language Models (LLMs) can automate this process. However, proprietary SOTA models like GPT-4o often generate inaccurate assertions and require expensive licenses, while smaller open-source LLMs need fine-tuning to manage HDL code complexities. To address these issues, we introduce **VERT**, an open-source dataset designed to enhance SystemVerilog assertion generation using LLMs. VERT enables researchers in academia and industry to fine-tune open-source models, outperforming larger proprietary ones in both accuracy and efficiency while ensuring data privacy through local fine-tuning and eliminating costly licenses. The dataset is curated by systematically augmenting variables from open-source HDL repositories to generate synthetic code snippets paired with corresponding assertions. Experimental results demonstrate that fine-tuned models like Deepseek Coder 6.7B and Llama 3.1 8B outperform GPT-4o, achieving up to 96.88% improvement over base models and 24.14% over GPT-4o on platforms including OpenTitan, CVA6, OpenPiton and Pulpissimo. VERT is available at https://github.com/AnandMenon12/VERT.
AttentionBreaker: Adaptive Evolutionary Optimization for Unmasking Vulnerabilities in LLMs through Bit-Flip Attacks
Nov 21, 2024



Large Language Models (LLMs) have revolutionized natural language processing (NLP), excelling in tasks like text generation and summarization. However, their increasing adoption in mission-critical applications raises concerns about hardware-based threats, particularly bit-flip attacks (BFAs). BFAs, enabled by fault injection methods such as Rowhammer, target model parameters in memory, compromising both integrity and performance. Identifying critical parameters for BFAs in the vast parameter space of LLMs poses significant challenges. While prior research suggests transformer-based architectures are inherently more robust to BFAs compared to traditional deep neural networks, we challenge this assumption. For the first time, we demonstrate that as few as three bit-flips can cause catastrophic performance degradation in an LLM with billions of parameters. Current BFA techniques are inadequate for exploiting this vulnerability due to the difficulty of efficiently identifying critical parameters within the immense parameter space. To address this, we propose AttentionBreaker, a novel framework tailored for LLMs that enables efficient traversal of the parameter space to identify critical parameters. Additionally, we introduce GenBFA, an evolutionary optimization strategy designed to refine the search further, isolating the most critical bits for an efficient and effective attack. Empirical results reveal the profound vulnerability of LLMs to AttentionBreaker. For example, merely three bit-flips (4.129 x 10^-9% of total parameters) in the LLaMA3-8B-Instruct 8-bit quantized (W8) model result in a complete performance collapse: accuracy on MMLU tasks drops from 67.3% to 0%, and Wikitext perplexity skyrockets from 12.6 to 4.72 x 10^5. These findings underscore the effectiveness of AttentionBreaker in uncovering and exploiting critical vulnerabilities within LLM architectures.
PristiQ: A Co-Design Framework for Preserving Data Security of Quantum Learning in the Cloud
Apr 20, 2024Benefiting from cloud computing, today's early-stage quantum computers can be remotely accessed via the cloud services, known as Quantum-as-a-Service (QaaS). However, it poses a high risk of data leakage in quantum machine learning (QML). To run a QML model with QaaS, users need to locally compile their quantum circuits including the subcircuit of data encoding first and then send the compiled circuit to the QaaS provider for execution. If the QaaS provider is untrustworthy, the subcircuit to encode the raw data can be easily stolen. Therefore, we propose a co-design framework for preserving the data security of QML with the QaaS paradigm, namely PristiQ. By introducing an encryption subcircuit with extra secure qubits associated with a user-defined security key, the security of data can be greatly enhanced. And an automatic search algorithm is proposed to optimize the model to maintain its performance on the encrypted quantum data. Experimental results on simulation and the actual IBM quantum computer both prove the ability of PristiQ to provide high security for the quantum data while maintaining the model performance in QML.
Enhancing Functional Safety in Automotive AMS Circuits through Unsupervised Machine Learning
Apr 02, 2024Given the widespread use of safety-critical applications in the automotive field, it is crucial to ensure the Functional Safety (FuSa) of circuits and components within automotive systems. The Analog and Mixed-Signal (AMS) circuits prevalent in these systems are more vulnerable to faults induced by parametric perturbations, noise, environmental stress, and other factors, in comparison to their digital counterparts. However, their continuous signal characteristics present an opportunity for early anomaly detection, enabling the implementation of safety mechanisms to prevent system failure. To address this need, we propose a novel framework based on unsupervised machine learning for early anomaly detection in AMS circuits. The proposed approach involves injecting anomalies at various circuit locations and individual components to create a diverse and comprehensive anomaly dataset, followed by the extraction of features from the observed circuit signals. Subsequently, we employ clustering algorithms to facilitate anomaly detection. Finally, we propose a time series framework to enhance and expedite anomaly detection performance. Our approach encompasses a systematic analysis of anomaly abstraction at multiple levels pertaining to the automotive domain, from hardware- to block-level, where anomalies are injected to create diverse fault scenarios. By monitoring the system behavior under these anomalous conditions, we capture the propagation of anomalies and their effects at different abstraction levels, thereby potentially paving the way for the implementation of reliable safety mechanisms to ensure the FuSa of automotive SoCs. Our experimental findings indicate that our approach achieves 100% anomaly detection accuracy and significantly optimizes the associated latency by 5X, underscoring the effectiveness of our devised solution.
Machine Learning-enhanced Efficient Spectroscopic Ellipsometry Modeling
Jan 01, 2022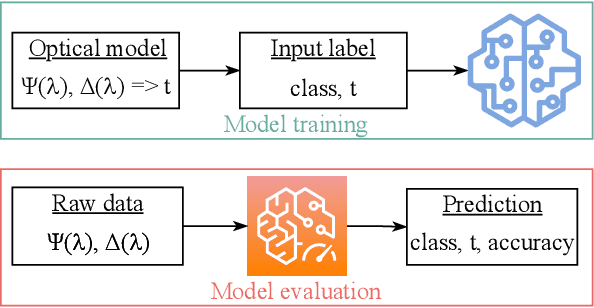
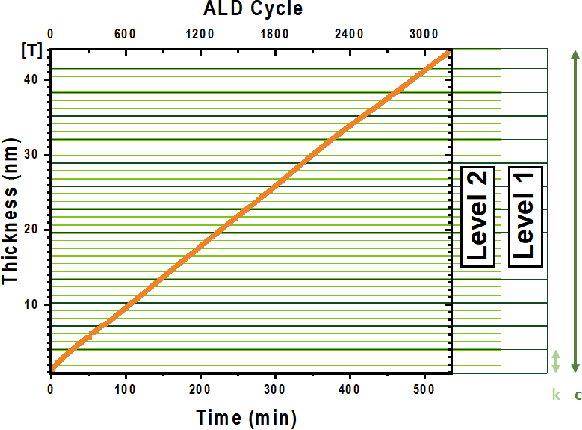
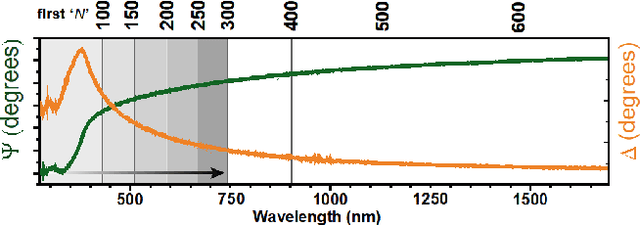
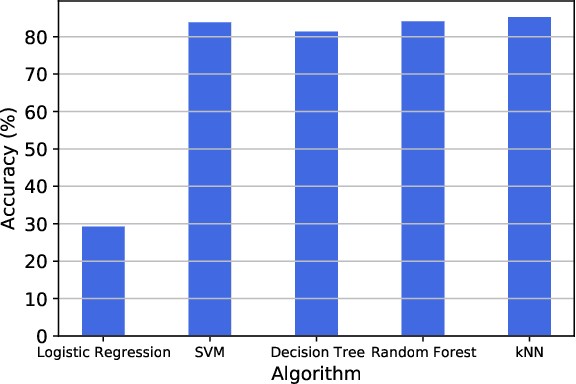
Over the recent years, there has been an extensive adoption of Machine Learning (ML) in a plethora of real-world applications, ranging from computer vision to data mining and drug discovery. In this paper, we utilize ML to facilitate efficient film fabrication, specifically Atomic Layer Deposition (ALD). In order to make advances in ALD process development, which is utilized to generate thin films, and its subsequent accelerated adoption in industry, it is imperative to understand the underlying atomistic processes. Towards this end, in situ techniques for monitoring film growth, such as Spectroscopic Ellipsometry (SE), have been proposed. However, in situ SE is associated with complex hardware and, hence, is resource intensive. To address these challenges, we propose an ML-based approach to expedite film thickness estimation. The proposed approach has tremendous implications of faster data acquisition, reduced hardware complexity and easier integration of spectroscopic ellipsometry for in situ monitoring of film thickness deposition. Our experimental results involving SE of TiO2 demonstrate that the proposed ML-based approach furnishes promising thickness prediction accuracy results of 88.76% within +/-1.5 nm and 85.14% within +/-0.5 nm intervals. Furthermore, we furnish accuracy results up to 98% at lower thicknesses, which is a significant improvement over existing SE-based analysis, thereby making our solution a viable option for thickness estimation of ultrathin films.
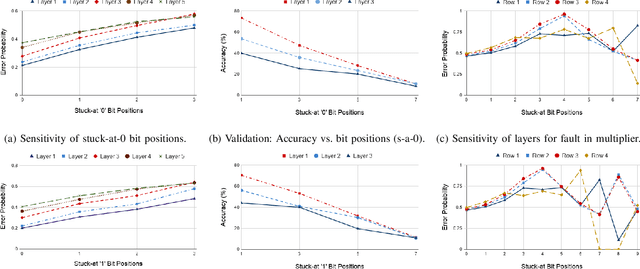
Exploring Fault-Energy Trade-offs in Approximate DNN Hardware Accelerators
Jan 08, 2021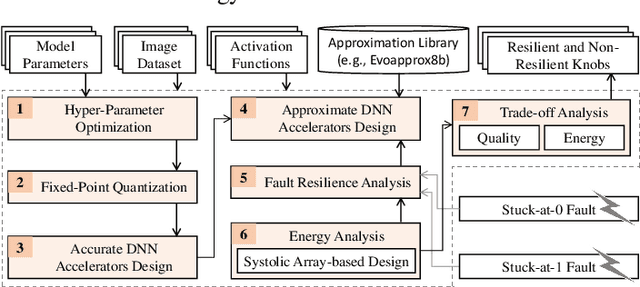
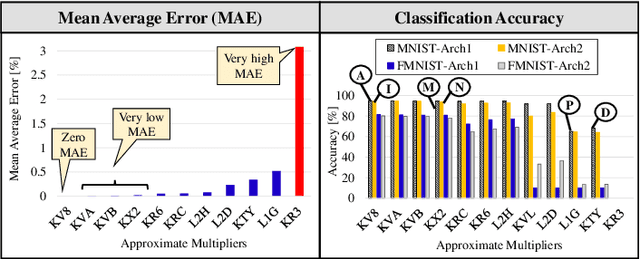


Systolic array-based deep neural network (DNN) accelerators have recently gained prominence for their low computational cost. However, their high energy consumption poses a bottleneck to their deployment in energy-constrained devices. To address this problem, approximate computing can be employed at the cost of some tolerable accuracy loss. However, such small accuracy variations may increase the sensitivity of DNNs towards undesired subtle disturbances, such as permanent faults. The impact of permanent faults in accurate DNNs has been thoroughly investigated in the literature. Conversely, the impact of permanent faults in approximate DNN accelerators (AxDNNs) is yet under-explored. The impact of such faults may vary with the fault bit positions, activation functions and approximation errors in AxDNN layers. Such dynamacity poses a considerable challenge to exploring the trade-off between their energy efficiency and fault resilience in AxDNNs. Towards this, we present an extensive layer-wise and bit-wise fault resilience and energy analysis of different AxDNNs, using the state-of-the-art Evoapprox8b signed multipliers. In particular, we vary the stuck-at-0, stuck-at-1 fault-bit positions, and activation functions to study their impact using the most widely used MNIST and Fashion-MNIST datasets. Our quantitative analysis shows that the permanent faults exacerbate the accuracy loss in AxDNNs when compared to the accurate DNN accelerators. For instance, a permanent fault in AxDNNs can lead up to 66\% accuracy loss, whereas the same faulty bit can lead to only 9\% accuracy loss in an accurate DNN accelerator. Our results demonstrate that the fault resilience in AxDNNs is orthogonal to the energy efficiency.
High-level Modeling of Manufacturing Faults in Deep Neural Network Accelerators
Jun 05, 2020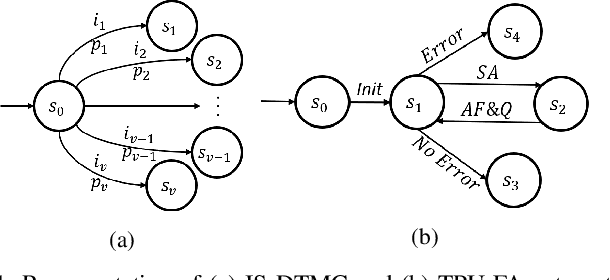
The advent of data-driven real-time applications requires the implementation of Deep Neural Networks (DNNs) on Machine Learning accelerators. Google's Tensor Processing Unit (TPU) is one such neural network accelerator that uses systolic array-based matrix multiplication hardware for computation in its crux. Manufacturing faults at any state element of the matrix multiplication unit can cause unexpected errors in these inference networks. In this paper, we propose a formal model of permanent faults and their propagation in a TPU using the Discrete-Time Markov Chain (DTMC) formalism. The proposed model is analyzed using the probabilistic model checking technique to reason about the likelihood of faulty outputs. The obtained quantitative results show that the classification accuracy is sensitive to the type of permanent faults as well as their location, bit position and the number of layers in the neural network. The conclusions from our theoretical model have been validated using experiments on a digit recognition-based DNN.
Hardware Trojan Detection Using Controlled Circuit Aging
Apr 21, 2020



This paper reports a novel approach that uses transistor aging in an integrated circuit (IC) to detect hardware Trojans. When a transistor is aged, it results in delays along several paths of the IC. This increase in delay results in timing violations that reveal as timing errors at the output of the IC during its operation. We present experiments using aging-aware standard cell libraries to illustrate the usefulness of the technique in detecting hardware Trojans. Combining IC aging with over-clocking produces a pattern of bit errors at the IC output by the induced timing violations. We use machine learning to learn the bit error distribution at the output of a clean IC. We differentiate the divergence in the pattern of bit errors because of a Trojan in the IC from this baseline distribution. We simulate the golden IC and show robustness to IC-to-IC manufacturing variations. The approach is effective and can detect a Trojan even if we place it far off the critical paths. Results on benchmarks from the Trust-hub show a detection accuracy of $\geq$99%.