 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproXAI: Energy-Efficient Hardware Acceleration of Explainable AI using Approximate Computing
Apr 24, 2025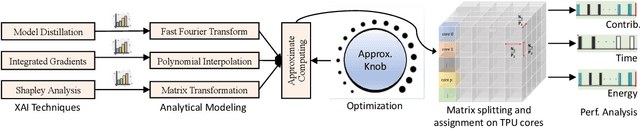
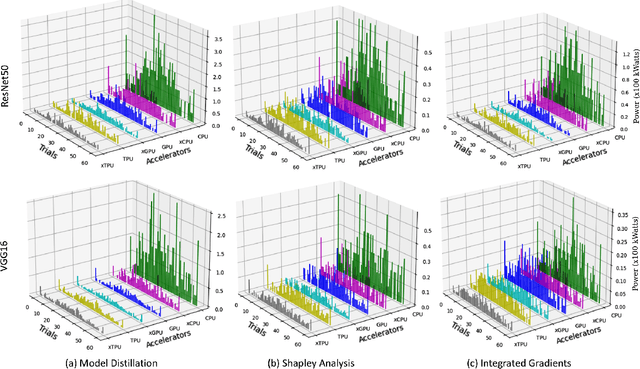
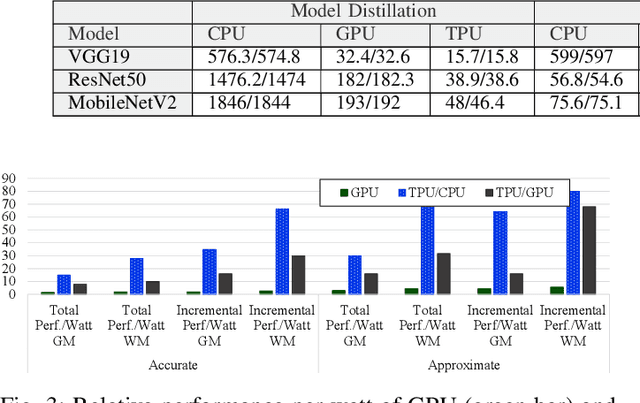
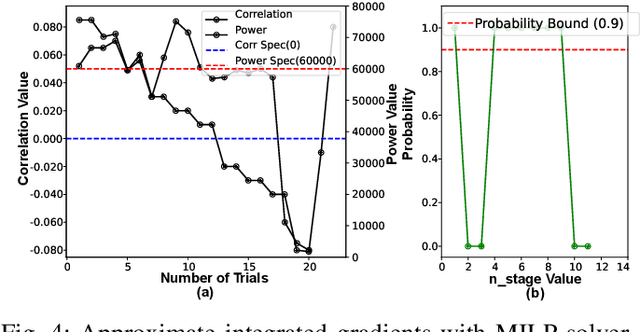
Explainable artificial intelligence (XAI) enhances AI system transparency by framing interpretability as an optimization problem. However, this approach often necessitates numerous iterations of computationally intensive operations, limiting its applicability in real-time scenarios. While recent research has focused on XAI hardware acceleration on FPGAs and TPU, these methods do not fully address energy efficiency in real-time settings. To address this limitation, we propose XAIedge, a novel framework that leverages approximate computing techniques into XAI algorithms, including integrated gradients, model distillation, and Shapley analysis. XAIedge translates these algorithms into approximate matrix computations and exploits the synergy between convolution, Fourier transform, and approximate computing paradigms. This approach enables efficient hardware acceleration on TPU-based edge devices, facilitating faster real-time outcome interpretations. Our comprehensive evaluation demonstrates that XAIedge achieves a $2\times$ improvement in energy efficiency compared to existing accurate XAI hardware acceleration techniques while maintaining comparable accuracy. These results highlight the potential of XAIedge to significantly advance the deployment of explainable AI in energy-constrained real-time applications.
Explainable AI-Guided Efficient Approximate DNN Generation for Multi-Pod Systolic Arrays
Mar 20, 2025



Approximate deep neural networks (AxDNNs) are promising for enhancing energy efficiency in real-world devices. One of the key contributors behind this enhanced energy efficiency in AxDNNs is the use of approximate multipliers. Unfortunately, the simulation of approximate multipliers does not usually scale well on CPUs and GPUs. As a consequence, this slows down the overall simulation of AxDNNs aimed at identifying the appropriate approximate multipliers to achieve high energy efficiency with a minimum accuracy loss. To address this problem, we present a novel XAI-Gen methodology, which leverages the analytical model of the emerging hardware accelerator (e.g., Google TPU v4) and explainable artificial intelligence (XAI) to precisely identify the non-critical layers for approximation and quickly discover the appropriate approximate multipliers for AxDNN layers. Our results show that XAI-Gen achieves up to 7x lower energy consumption with only 1-2% accuracy loss. We also showcase the effectiveness of the XAI-Gen approach through a neural architecture search (XAI-NAS) case study. Interestingly, XAI-NAS achieves 40\% higher energy efficiency with up to 5x less execution time when compared to the state-of-the-art NAS methods for generating AxDNNs.
RobustPdM: Designing Robust Predictive Maintenance against Adversarial Attacks
Jan 25, 2023



The state-of-the-art predictive maintenance (PdM) techniques have shown great success in reducing maintenance costs and downtime of complicated machines while increasing overall productivity through extensive utilization of Internet-of-Things (IoT) and Deep Learning (DL). Unfortunately, IoT sensors and DL algorithms are both prone to cyber-attacks. For instance, DL algorithms are known for their susceptibility to adversarial examples. Such adversarial attacks are vastly under-explored in the PdM domain. This is because the adversarial attacks in the computer vision domain for classification tasks cannot be directly applied to the PdM domain for multivariate time series (MTS) regression tasks. In this work, we propose an end-to-end methodology to design adversarially robust PdM systems by extensively analyzing the effect of different types of adversarial attacks and proposing a novel adversarial defense technique for DL-enabled PdM models. First, we propose novel MTS Projected Gradient Descent (PGD) and MTS PGD with random restarts (PGD_r) attacks. Then, we evaluate the impact of MTS PGD and PGD_r along with MTS Fast Gradient Sign Method (FGSM) and MTS Basic Iterative Method (BIM) on Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), Convolutional Neural Network (CNN), and Bi-directional LSTM based PdM system. Our results using NASA's turbofan engine dataset show that adversarial attacks can cause a severe defect (up to 11X) in the RUL prediction, outperforming the effectiveness of the state-of-the-art PdM attacks by 3X. Furthermore, we present a novel approximate adversarial training method to defend against adversarial attacks. We observe that approximate adversarial training can significantly improve the robustness of PdM models (up to 54X) and outperforms the state-of-the-art PdM defense methods by offering 3X more robustness.
Security-Aware Approximate Spiking Neural Networks
Jan 12, 2023Deep Neural Networks (DNNs) and Spiking Neural Networks (SNNs) are both known for their susceptibility to adversarial attacks. Therefore, researchers in the recent past have extensively studied the robustness and defense of DNNs and SNNs under adversarial attacks. Compared to accurate SNNs (AccSNN), approximate SNNs (AxSNNs) are known to be up to 4X more energy-efficient for ultra-low power applications. Unfortunately, the robustness of AxSNNs under adversarial attacks is yet unexplored. In this paper, we first extensively analyze the robustness of AxSNNs with different structural parameters and approximation levels under two gradient-based and two neuromorphic attacks. Then, we propose two novel defense methods, i.e., precision scaling and approximate quantization-aware filtering (AQF), for securing AxSNNs. We evaluated the effectiveness of these two defense methods using both static and neuromorphic datasets. Our results demonstrate that AxSNNs are more prone to adversarial attacks than AccSNNs, but precision scaling and AQF significantly improve the robustness of AxSNNs. For instance, a PGD attack on AxSNN results in a 72\% accuracy loss compared to AccSNN without any attack, whereas the same attack on the precision-scaled AxSNN leads to only a 17\% accuracy loss in the static MNIST dataset (4X robustness improvement). Similarly, a Sparse Attack on AxSNN leads to a 77\% accuracy loss when compared to AccSNN without any attack, whereas the same attack on an AxSNN with AQF leads to only a 2\% accuracy loss in the neuromorphic DVS128 Gesture dataset (38X robustness improvement).
Improving Reliability of Spiking Neural Networks through Fault Aware Threshold Voltage Optimization
Jan 12, 2023



Spiking neural networks have made breakthroughs in computer vision by lending themselves to neuromorphic hardware. However, the neuromorphic hardware lacks parallelism and hence, limits the throughput and hardware acceleration of SNNs on edge devices. To address this problem, many systolic-array SNN accelerators (systolicSNNs) have been proposed recently, but their reliability is still a major concern. In this paper, we first extensively analyze the impact of permanent faults on the SystolicSNNs. Then, we present a novel fault mitigation method, i.e., fault-aware threshold voltage optimization in retraining (FalVolt). FalVolt optimizes the threshold voltage for each layer in retraining to achieve the classification accuracy close to the baseline in the presence of faults. To demonstrate the effectiveness of our proposed mitigation, we classify both static (i.e., MNIST) and neuromorphic datasets (i.e., N-MNIST and DVS Gesture) on a 256x256 systolicSNN with stuck-at faults. We empirically show that the classification accuracy of a systolicSNN drops significantly even at extremely low fault rates (as low as 0.012\%). Our proposed FalVolt mitigation method improves the performance of systolicSNNs by enabling them to operate at fault rates of up to 60\%, with a negligible drop in classification accuracy (as low as 0.1\%). Our results show that FalVolt is 2x faster compared to other state-of-the-art techniques common in artificial neural networks (ANNs), such as fault-aware pruning and retraining without threshold voltage optimization.
Is Approximation Universally Defensive Against Adversarial Attacks in Deep Neural Networks?
Dec 02, 2021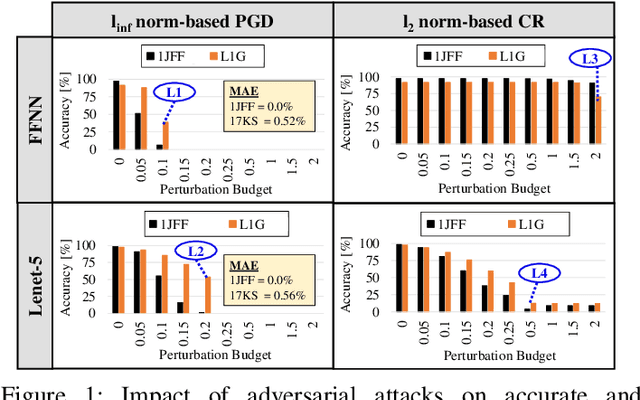
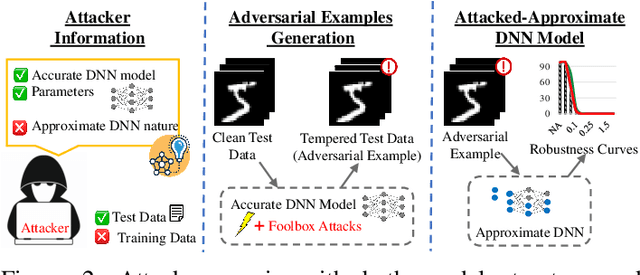
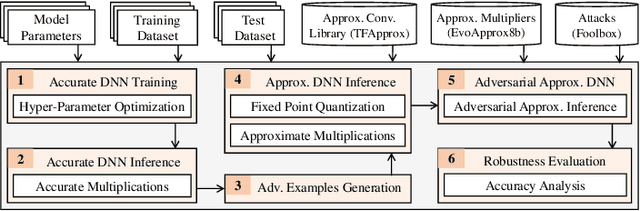

Approximate computing is known for its effectiveness in improvising the energy efficiency of deep neural network (DNN) accelerators at the cost of slight accuracy loss. Very recently, the inexact nature of approximate components, such as approximate multipliers have also been reported successful in defending adversarial attacks on DNNs models. Since the approximation errors traverse through the DNN layers as masked or unmasked, this raises a key research question-can approximate computing always offer a defense against adversarial attacks in DNNs, i.e., are they universally defensive? Towards this, we present an extensive adversarial robustness analysis of different approximate DNN accelerators (AxDNNs) using the state-of-the-art approximate multipliers. In particular, we evaluate the impact of ten adversarial attacks on different AxDNNs using the MNIST and CIFAR-10 datasets. Our results demonstrate that adversarial attacks on AxDNNs can cause 53% accuracy loss whereas the same attack may lead to almost no accuracy loss (as low as 0.06%) in the accurate DNN. Thus, approximate computing cannot be referred to as a universal defense strategy against adversarial attacks.
Exploring Fault-Energy Trade-offs in Approximate DNN Hardware Accelerators
Jan 08, 2021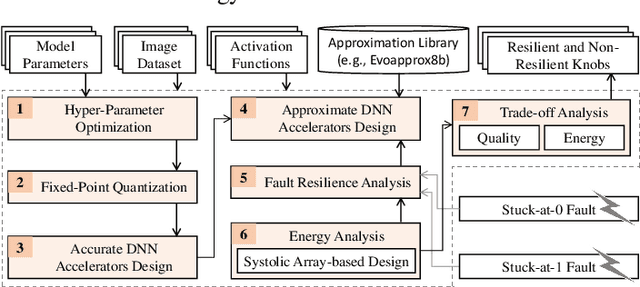
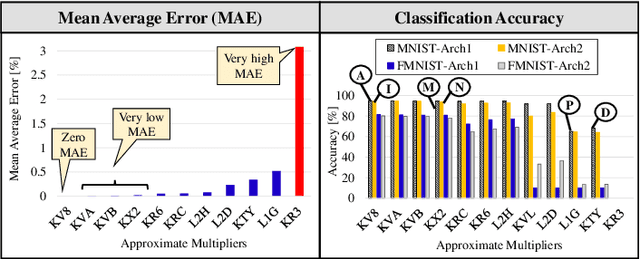


Systolic array-based deep neural network (DNN) accelerators have recently gained prominence for their low computational cost. However, their high energy consumption poses a bottleneck to their deployment in energy-constrained devices. To address this problem, approximate computing can be employed at the cost of some tolerable accuracy loss. However, such small accuracy variations may increase the sensitivity of DNNs towards undesired subtle disturbances, such as permanent faults. The impact of permanent faults in accurate DNNs has been thoroughly investigated in the literature. Conversely, the impact of permanent faults in approximate DNN accelerators (AxDNNs) is yet under-explored. The impact of such faults may vary with the fault bit positions, activation functions and approximation errors in AxDNN layers. Such dynamacity poses a considerable challenge to exploring the trade-off between their energy efficiency and fault resilience in AxDNNs. Towards this, we present an extensive layer-wise and bit-wise fault resilience and energy analysis of different AxDNNs, using the state-of-the-art Evoapprox8b signed multipliers. In particular, we vary the stuck-at-0, stuck-at-1 fault-bit positions, and activation functions to study their impact using the most widely used MNIST and Fashion-MNIST datasets. Our quantitative analysis shows that the permanent faults exacerbate the accuracy loss in AxDNNs when compared to the accurate DNN accelerators. For instance, a permanent fault in AxDNNs can lead up to 66\% accuracy loss, whereas the same faulty bit can lead to only 9\% accuracy loss in an accurate DNN accelerator. Our results demonstrate that the fault resilience in AxDNNs is orthogonal to the energy efficiency.