 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePILAR: Personalizing Augmented Reality Interactions with LLM-based Human-Centric and Trustworthy Explanations for Daily Use Cases
Dec 19, 2025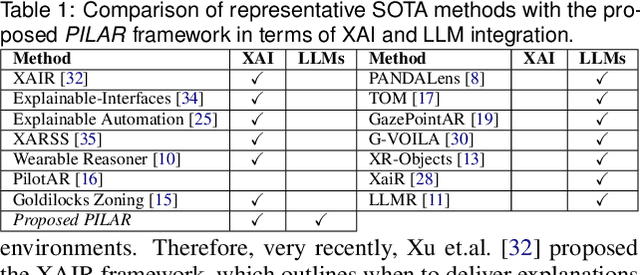

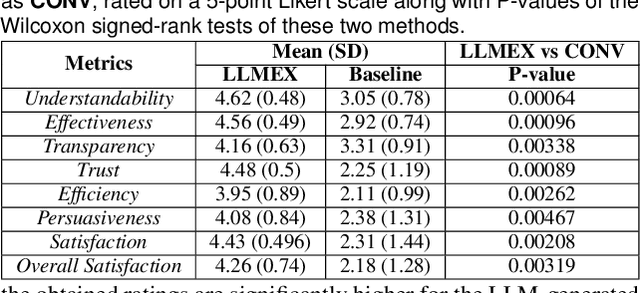

Artificial intelligence (AI)-driven augmented reality (AR) systems are becoming increasingly integrated into daily life, and with this growth comes a greater need for explainability in real-time user interactions. Traditional explainable AI (XAI) methods, which often rely on feature-based or example-based explanations, struggle to deliver dynamic, context-specific, personalized, and human-centric insights for everyday AR users. These methods typically address separate explainability dimensions (e.g., when, what, how) with different explanation techniques, resulting in unrealistic and fragmented experiences for seamless AR interactions. To address this challenge, we propose PILAR, a novel framework that leverages a pre-trained large language model (LLM) to generate context-aware, personalized explanations, offering a more intuitive and trustworthy experience in real-time AI-powered AR systems. Unlike traditional methods, which rely on multiple techniques for different aspects of explanation, PILAR employs a unified LLM-based approach that dynamically adapts explanations to the user's needs, fostering greater trust and engagement. We implement the PILAR concept in a real-world AR application (e.g., personalized recipe recommendations), an open-source prototype that integrates real-time object detection, recipe recommendation, and LLM-based personalized explanations of the recommended recipes based on users' dietary preferences. We evaluate the effectiveness of PILAR through a user study with 16 participants performing AR-based recipe recommendation tasks, comparing an LLM-based explanation interface to a traditional template-based one. Results show that the LLM-based interface significantly enhances user performance and experience, with participants completing tasks 40% faster and reporting greater satisfaction, ease of use, and perceived transparency.
TOGGLE: Temporal Logic-Guided Large Language Model Compression for Edge
Dec 18, 2025Large Language Models (LLMs) deliver exceptional performance across natural language tasks but demand substantial computational resources, limiting their deployment on resource-constrained edge devices. Existing compression techniques, such as quantization and pruning, often degrade critical linguistic properties and lack formal guarantees for preserving model behavior. We propose Temporal Logic-Guided Large Language Model Compression (TOGGLE), a novel framework that leverages Signal Temporal Logic (STL) to formally specify and enforce linguistic properties during compression. TOGGLE employs an STL robustness-guided Bayesian optimization to systematically explore layer-wise quantization and pruning configurations, generating compressed models that formally satisfy specified linguistic constraints without retraining or fine-tuning. Evaluating TOGGLE on four LLM architectures (GPT-2, DeepSeek-V2 7B, LLaMA 3 8B, and Mistral 7B), we achieve up to 3.3x reduction in computational costs (FLOPs) and up to a 68.8% reduction in model size while satisfying all linguistic properties. TOGGLE represents the first integration of formal methods into LLM compression, enabling efficient, verifiable deployment of LLMs on edge hardware.
PrivateXR: Defending Privacy Attacks in Extended Reality Through Explainable AI-Guided Differential Privacy
Dec 18, 2025
The convergence of artificial AI and XR technologies (AI XR) promises innovative applications across many domains. However, the sensitive nature of data (e.g., eye-tracking) used in these systems raises significant privacy concerns, as adversaries can exploit these data and models to infer and leak personal information through membership inference attacks (MIA) and re-identification (RDA) with a high success rate. Researchers have proposed various techniques to mitigate such privacy attacks, including differential privacy (DP). However, AI XR datasets often contain numerous features, and applying DP uniformly can introduce unnecessary noise to less relevant features, degrade model accuracy, and increase inference time, limiting real-time XR deployment. Motivated by this, we propose a novel framework combining explainable AI (XAI) and DP-enabled privacy-preserving mechanisms to defend against privacy attacks. Specifically, we leverage post-hoc explanations to identify the most influential features in AI XR models and selectively apply DP to those features during inference. We evaluate our XAI-guided DP approach on three state-of-the-art AI XR models and three datasets: cybersickness, emotion, and activity classification. Our results show that the proposed method reduces MIA and RDA success rates by up to 43% and 39%, respectively, for cybersickness tasks while preserving model utility with up to 97% accuracy using Transformer models. Furthermore, it improves inference time by up to ~2x compared to traditional DP approaches. To demonstrate practicality, we deploy the XAI-guided DP AI XR models on an HTC VIVE Pro headset and develop a user interface (UI), namely PrivateXR, allowing users to adjust privacy levels (e.g., low, medium, high) while receiving real-time task predictions, protecting user privacy during XR gameplay.
Adversarial VR: An Open-Source Testbed for Evaluating Adversarial Robustness of VR Cybersickness Detection and Mitigation
Dec 18, 2025Deep learning (DL)-based automated cybersickness detection methods, along with adaptive mitigation techniques, can enhance user comfort and interaction. However, recent studies show that these DL-based systems are susceptible to adversarial attacks; small perturbations to sensor inputs can degrade model performance, trigger incorrect mitigation, and disrupt the user's immersive experience (UIX). Additionally, there is a lack of dedicated open-source testbeds that evaluate the robustness of these systems under adversarial conditions, limiting the ability to assess their real-world effectiveness. To address this gap, this paper introduces Adversarial-VR, a novel real-time VR testbed for evaluating DL-based cybersickness detection and mitigation strategies under adversarial conditions. Developed in Unity, the testbed integrates two state-of-the-art (SOTA) DL models: DeepTCN and Transformer, which are trained on the open-source MazeSick dataset, for real-time cybersickness severity detection and applies a dynamic visual tunneling mechanism that adjusts the field-of-view based on model outputs. To assess robustness, we incorporate three SOTA adversarial attacks: MI-FGSM, PGD, and C&W, which successfully prevent cybersickness mitigation by fooling DL-based cybersickness models' outcomes. We implement these attacks using a testbed with a custom-built VR Maze simulation and an HTC Vive Pro Eye headset, and we open-source our implementation for widespread adoption by VR developers and researchers. Results show that these adversarial attacks are capable of successfully fooling the system. For instance, the C&W attack results in a $5.94x decrease in accuracy for the Transformer-based cybersickness model compared to the accuracy without the attack.
RIFT: A Scalable Methodology for LLM Accelerator Fault Assessment using Reinforcement Learning
Dec 10, 2025



The massive scale of modern AI accelerators presents critical challenges to traditional fault assessment methodologies, which face prohibitive computational costs and provide poor coverage of critical failure modes. This paper introduces RIFT (Reinforcement Learning-guided Intelligent Fault Targeting), a scalable framework that automates the discovery of minimal, high-impact fault scenarios for efficient design-time fault assessment. RIFT transforms the complex search for worst-case faults into a sequential decision-making problem, combining hybrid sensitivity analysis for search space pruning with reinforcement learning to intelligently generate minimal, high-impact test suites. Evaluated on billion-parameter Large Language Model (LLM) workloads using NVIDIA A100 GPUs, RIFT achieves a \textbf{2.2$\times$} fault assessment speedup over evolutionary methods and reduces the required test vector volume by over \textbf{99\%} compared to random fault injection, all while achieving \textbf{superior fault coverage}. The proposed framework also provides actionable data to enable intelligent hardware protection strategies, demonstrating that RIFT-guided selective error correction code provides a \textbf{12.8$\times$} improvement in \textbf{cost-effectiveness} (coverage per unit area) compared to uniform triple modular redundancy protection. RIFT automatically generates UVM-compliant verification artifacts, ensuring its findings are directly actionable and integrable into commercial RTL verification workflows.
FlipLLM: Efficient Bit-Flip Attacks on Multimodal LLMs using Reinforcement Learning
Dec 10, 2025Generative Artificial Intelligence models, such as Large Language Models (LLMs) and Large Vision Models (VLMs), exhibit state-of-the-art performance but remain vulnerable to hardware-based threats, specifically bit-flip attacks (BFAs). Existing BFA discovery methods lack generalizability and struggle to scale, often failing to analyze the vast parameter space and complex interdependencies of modern foundation models in a reasonable time. This paper proposes FlipLLM, a reinforcement learning (RL) architecture-agnostic framework that formulates BFA discovery as a sequential decision-making problem. FlipLLM combines sensitivity-guided layer pruning with Q-learning to efficiently identify minimal, high-impact bit sets that can induce catastrophic failure. We demonstrate the effectiveness and generalizability of FlipLLM by applying it to a diverse set of models, including prominent text-only LLMs (GPT-2 Large, LLaMA 3.1 8B, and DeepSeek-V2 7B), VLMs such as LLaVA 1.6, and datasets, such as MMLU, MMLU-Pro, VQAv2, and TextVQA. Our results show that FlipLLM can identify critical bits that are vulnerable to BFAs up to 2.5x faster than SOTA methods. We demonstrate that flipping the FlipLLM-identified bits plummets the accuracy of LLaMA 3.1 8B from 69.9% to ~0.2%, and for LLaVA's VQA score from 78% to almost 0%, by flipping as few as 5 and 7 bits, respectively. Further analysis reveals that applying standard hardware protection mechanisms, such as ECC SECDED, to the FlipLLM-identified bit locations completely mitigates the BFA impact, demonstrating the practical value of our framework in guiding hardware-level defenses. FlipLLM offers the first scalable and adaptive methodology for exploring the BFA vulnerability of both language and multimodal foundation models, paving the way for comprehensive hardware-security evaluation.
Hyperproperty-Constrained Secure Reinforcement Learning
Jul 31, 2025Hyperproperties for Time Window Temporal Logic (HyperTWTL) is a domain-specific formal specification language known for its effectiveness in compactly representing security, opacity, and concurrency properties for robotics applications. This paper focuses on HyperTWTL-constrained secure reinforcement learning (SecRL). Although temporal logic-constrained safe reinforcement learning (SRL) is an evolving research problem with several existing literature, there is a significant research gap in exploring security-aware reinforcement learning (RL) using hyperproperties. Given the dynamics of an agent as a Markov Decision Process (MDP) and opacity/security constraints formalized as HyperTWTL, we propose an approach for learning security-aware optimal policies using dynamic Boltzmann softmax RL while satisfying the HyperTWTL constraints. The effectiveness and scalability of our proposed approach are demonstrated using a pick-up and delivery robotic mission case study. We also compare our results with two other baseline RL algorithms, showing that our proposed method outperforms them.
EPSILON: Adaptive Fault Mitigation in Approximate Deep Neural Network using Statistical Signatures
Apr 24, 2025



The increasing adoption of approximate computing in deep neural network accelerators (AxDNNs) promises significant energy efficiency gains. However, permanent faults in AxDNNs can severely degrade their performance compared to their accurate counterparts (AccDNNs). Traditional fault detection and mitigation approaches, while effective for AccDNNs, introduce substantial overhead and latency, making them impractical for energy-constrained real-time deployment. To address this, we introduce EPSILON, a lightweight framework that leverages pre-computed statistical signatures and layer-wise importance metrics for efficient fault detection and mitigation in AxDNNs. Our framework introduces a novel non-parametric pattern-matching algorithm that enables constant-time fault detection without interrupting normal execution while dynamically adapting to different network architectures and fault patterns. EPSILON maintains model accuracy by intelligently adjusting mitigation strategies based on a statistical analysis of weight distribution and layer criticality while preserving the energy benefits of approximate computing. Extensive evaluations across various approximate multipliers, AxDNN architectures, popular datasets (MNIST, CIFAR-10, CIFAR-100, ImageNet-1k), and fault scenarios demonstrate that EPSILON maintains 80.05\% accuracy while offering 22\% improvement in inference time and 28\% improvement in energy efficiency, establishing EPSILON as a practical solution for deploying reliable AxDNNs in safety-critical edge applications.
ApproXAI: Energy-Efficient Hardware Acceleration of Explainable AI using Approximate Computing
Apr 24, 2025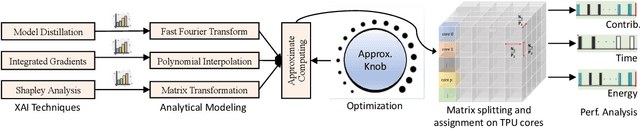
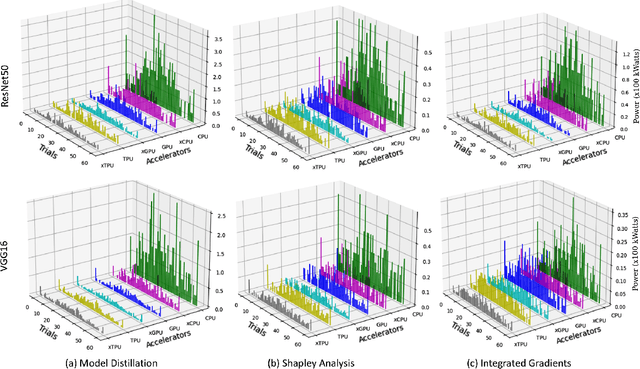
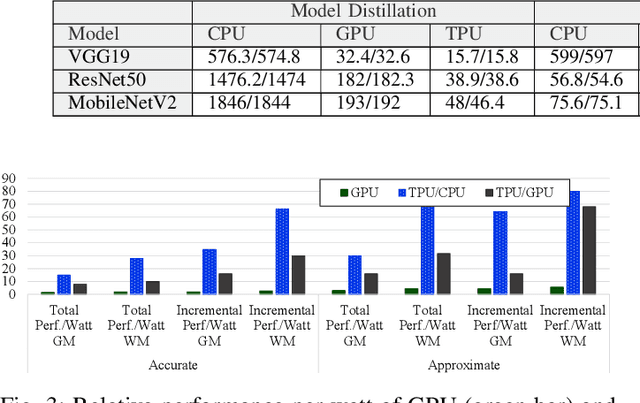
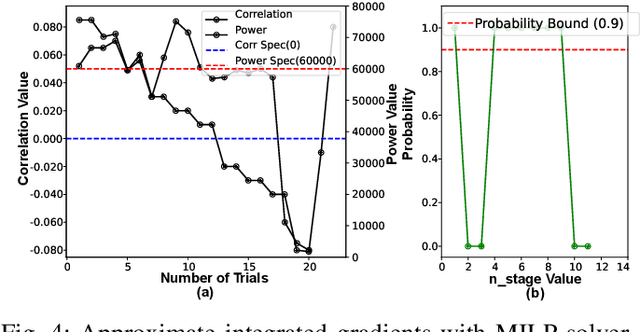
Explainable artificial intelligence (XAI) enhances AI system transparency by framing interpretability as an optimization problem. However, this approach often necessitates numerous iterations of computationally intensive operations, limiting its applicability in real-time scenarios. While recent research has focused on XAI hardware acceleration on FPGAs and TPU, these methods do not fully address energy efficiency in real-time settings. To address this limitation, we propose XAIedge, a novel framework that leverages approximate computing techniques into XAI algorithms, including integrated gradients, model distillation, and Shapley analysis. XAIedge translates these algorithms into approximate matrix computations and exploits the synergy between convolution, Fourier transform, and approximate computing paradigms. This approach enables efficient hardware acceleration on TPU-based edge devices, facilitating faster real-time outcome interpretations. Our comprehensive evaluation demonstrates that XAIedge achieves a $2\times$ improvement in energy efficiency compared to existing accurate XAI hardware acceleration techniques while maintaining comparable accuracy. These results highlight the potential of XAIedge to significantly advance the deployment of explainable AI in energy-constrained real-time applications.
Explainable AI-Guided Efficient Approximate DNN Generation for Multi-Pod Systolic Arrays
Mar 20, 2025



Approximate deep neural networks (AxDNNs) are promising for enhancing energy efficiency in real-world devices. One of the key contributors behind this enhanced energy efficiency in AxDNNs is the use of approximate multipliers. Unfortunately, the simulation of approximate multipliers does not usually scale well on CPUs and GPUs. As a consequence, this slows down the overall simulation of AxDNNs aimed at identifying the appropriate approximate multipliers to achieve high energy efficiency with a minimum accuracy loss. To address this problem, we present a novel XAI-Gen methodology, which leverages the analytical model of the emerging hardware accelerator (e.g., Google TPU v4) and explainable artificial intelligence (XAI) to precisely identify the non-critical layers for approximation and quickly discover the appropriate approximate multipliers for AxDNN layers. Our results show that XAI-Gen achieves up to 7x lower energy consumption with only 1-2% accuracy loss. We also showcase the effectiveness of the XAI-Gen approach through a neural architecture search (XAI-NAS) case study. Interestingly, XAI-NAS achieves 40\% higher energy efficiency with up to 5x less execution time when compared to the state-of-the-art NAS methods for generating AxDNNs.