 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Performance of Large Language Models on Subjective Span Identification Tasks
Jan 02, 2026Identifying relevant text spans is important for several downstream tasks in NLP, as it contributes to model explainability. While most span identification approaches rely on relatively smaller pre-trained language models like BERT, a few recent approaches have leveraged the latest generation of Large Language Models (LLMs) for the task. Current work has focused on explicit span identification like Named Entity Recognition (NER), while more subjective span identification with LLMs in tasks like Aspect-based Sentiment Analysis (ABSA) has been underexplored. In this paper, we fill this important gap by presenting an evaluation of the performance of various LLMs on text span identification in three popular tasks, namely sentiment analysis, offensive language identification, and claim verification. We explore several LLM strategies like instruction tuning, in-context learning, and chain of thought. Our results indicate underlying relationships within text aid LLMs in identifying precise text spans.
Automated Feature Tracking for Real-Time Kinematic Analysis and Shape Estimation of Carbon Nanotube Growth
Aug 26, 2025



Carbon nanotubes (CNTs) are critical building blocks in nanotechnology, yet the characterization of their dynamic growth is limited by the experimental challenges in nanoscale motion measurement using scanning electron microscopy (SEM) imaging. Existing ex situ methods offer only static analysis, while in situ techniques often require manual initialization and lack continuous per-particle trajectory decomposition. We present Visual Feature Tracking (VFTrack) an in-situ real-time particle tracking framework that automatically detects and tracks individual CNT particles in SEM image sequences. VFTrack integrates handcrafted or deep feature detectors and matchers within a particle tracking framework to enable kinematic analysis of CNT micropillar growth. A systematic using 13,540 manually annotated trajectories identifies the ALIKED detector with LightGlue matcher as an optimal combination (F1-score of 0.78, $\alpha$-score of 0.89). VFTrack motion vectors decomposed into axial growth, lateral drift, and oscillations, facilitate the calculation of heterogeneous regional growth rates and the reconstruction of evolving CNT pillar morphologies. This work enables advancement in automated nano-material characterization, bridging the gap between physics-based models and experimental observation to enable real-time optimization of CNT synthesis.
Securing Virtual Reality Experiences: Unveiling and Tackling Cybersickness Attacks with Explainable AI
Mar 17, 2025The synergy between virtual reality (VR) and artificial intelligence (AI), specifically deep learning (DL)-based cybersickness detection models, has ushered in unprecedented advancements in immersive experiences by automatically detecting cybersickness severity and adaptively various mitigation techniques, offering a smooth and comfortable VR experience. While this DL-enabled cybersickness detection method provides promising solutions for enhancing user experiences, it also introduces new risks since these models are vulnerable to adversarial attacks; a small perturbation of the input data that is visually undetectable to human observers can fool the cybersickness detection model and trigger unexpected mitigation, thus disrupting user immersive experiences (UIX) and even posing safety risks. In this paper, we present a new type of VR attack, i.e., a cybersickness attack, which successfully stops the triggering of cybersickness mitigation by fooling DL-based cybersickness detection models and dramatically hinders the UIX. Next, we propose a novel explainable artificial intelligence (XAI)-guided cybersickness attack detection framework to detect such attacks in VR to ensure UIX and a comfortable VR experience. We evaluate the proposed attack and the detection framework using two state-of-the-art open-source VR cybersickness datasets: Simulation 2021 and Gameplay dataset. Finally, to verify the effectiveness of our proposed method, we implement the attack and the XAI-based detection using a testbed with a custom-built VR roller coaster simulation with an HTC Vive Pro Eye headset and perform a user study. Our study shows that such an attack can dramatically hinder the UIX. However, our proposed XAI-guided cybersickness attack detection can successfully detect cybersickness attacks and trigger the proper mitigation, effectively reducing VR cybersickness.
Claim Verification in the Age of Large Language Models: A Survey
Aug 26, 2024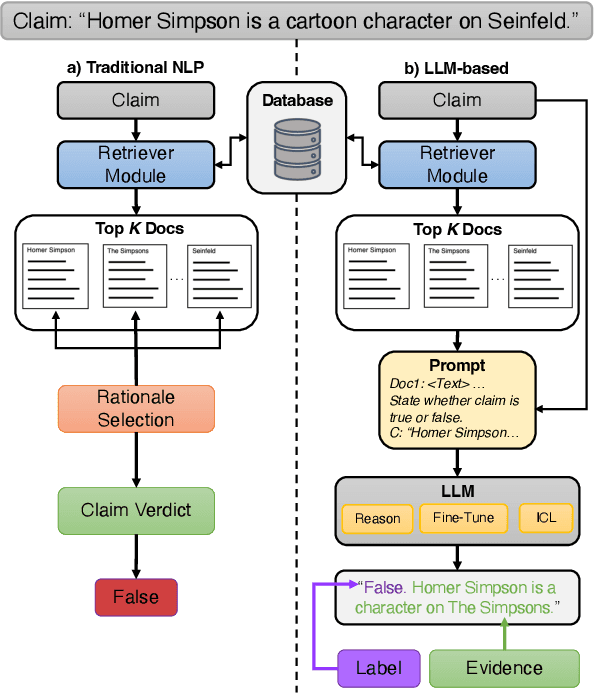
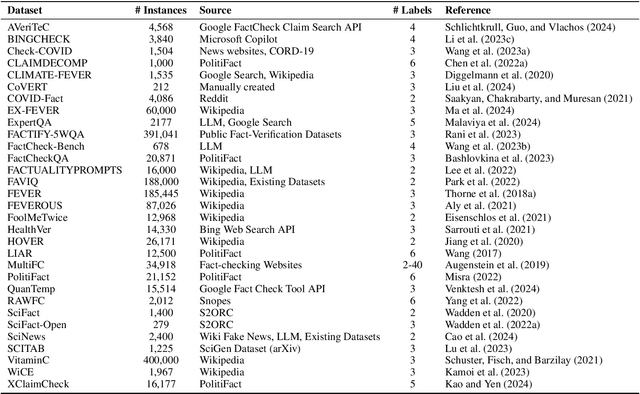
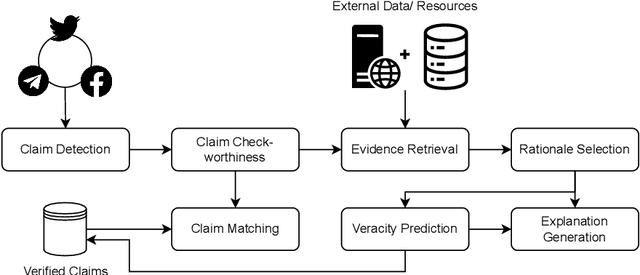
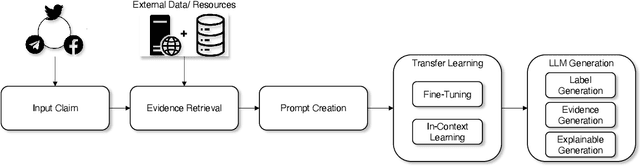
The large and ever-increasing amount of data available on the Internet coupled with the laborious task of manual claim and fact verification has sparked the interest in the development of automated claim verification systems. Several deep learning and transformer-based models have been proposed for this task over the years. With the introduction of Large Language Models (LLMs) and their superior performance in several NLP tasks, we have seen a surge of LLM-based approaches to claim verification along with the use of novel methods such as Retrieval Augmented Generation (RAG). In this survey, we present a comprehensive account of recent claim verification frameworks using LLMs. We describe the different components of the claim verification pipeline used in these frameworks in detail including common approaches to retrieval, prompting, and fine-tuning. Finally, we describe publicly available English datasets created for this task.
Reinforcement Learning-driven Data-intensive Workflow Scheduling for Volunteer Edge-Cloud
Jul 01, 2024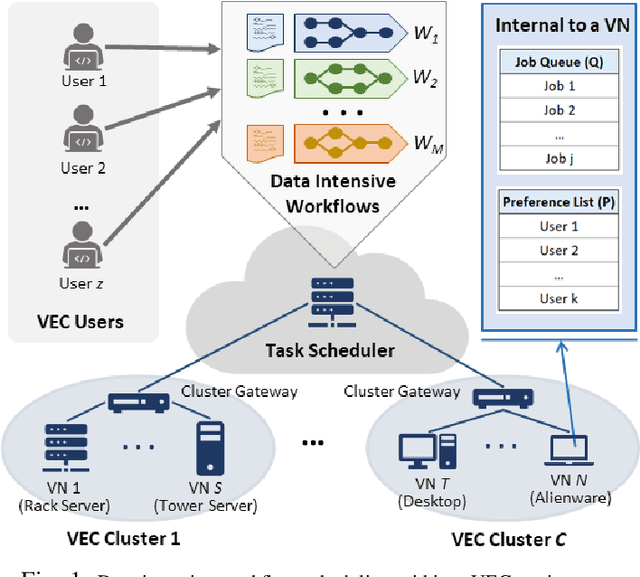
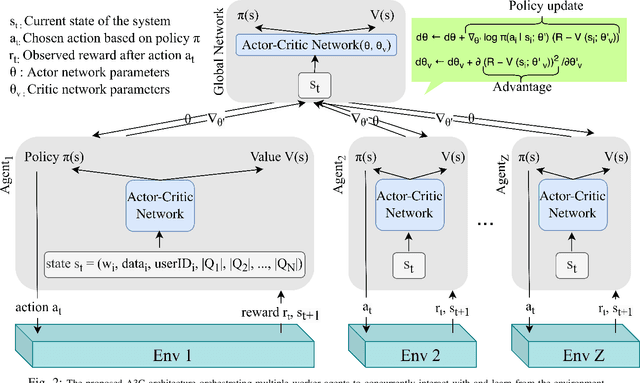
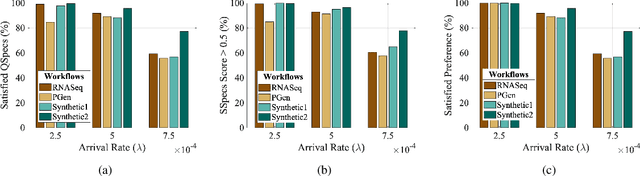
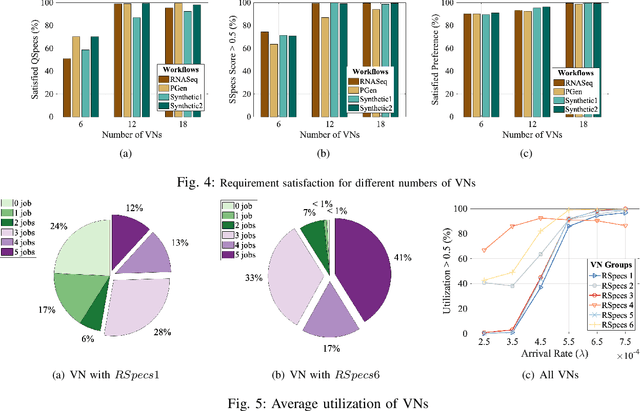
In recent times, Volunteer Edge-Cloud (VEC) has gained traction as a cost-effective, community computing paradigm to support data-intensive scientific workflows. However, due to the highly distributed and heterogeneous nature of VEC resources, centralized workflow task scheduling remains a challenge. In this paper, we propose a Reinforcement Learning (RL)-driven data-intensive scientific workflow scheduling approach that takes into consideration: i) workflow requirements, ii) VEC resources' preference on workflows, and iii) diverse VEC resource policies, to ensure robust resource allocation. We formulate the long-term average performance optimization problem as a Markov Decision Process, which is solved using an event-based Asynchronous Advantage Actor-Critic RL approach. Our extensive simulations and testbed implementations demonstrate our approach's benefits over popular baseline strategies in terms of workflow requirement satisfaction, VEC preference satisfaction, and available VEC resource utilization.
VR-LENS: Super Learning-based Cybersickness Detection and Explainable AI-Guided Deployment in Virtual Reality
Feb 03, 2023A plethora of recent research has proposed several automated methods based on machine learning (ML) and deep learning (DL) to detect cybersickness in Virtual reality (VR). However, these detection methods are perceived as computationally intensive and black-box methods. Thus, those techniques are neither trustworthy nor practical for deploying on standalone VR head-mounted displays (HMDs). This work presents an explainable artificial intelligence (XAI)-based framework VR-LENS for developing cybersickness detection ML models, explaining them, reducing their size, and deploying them in a Qualcomm Snapdragon 750G processor-based Samsung A52 device. Specifically, we first develop a novel super learning-based ensemble ML model for cybersickness detection. Next, we employ a post-hoc explanation method, such as SHapley Additive exPlanations (SHAP), Morris Sensitivity Analysis (MSA), Local Interpretable Model-Agnostic Explanations (LIME), and Partial Dependence Plot (PDP) to explain the expected results and identify the most dominant features. The super learner cybersickness model is then retrained using the identified dominant features. Our proposed method identified eye tracking, player position, and galvanic skin/heart rate response as the most dominant features for the integrated sensor, gameplay, and bio-physiological datasets. We also show that the proposed XAI-guided feature reduction significantly reduces the model training and inference time by 1.91X and 2.15X while maintaining baseline accuracy. For instance, using the integrated sensor dataset, our reduced super learner model outperforms the state-of-the-art works by classifying cybersickness into 4 classes (none, low, medium, and high) with an accuracy of 96% and regressing (FMS 1-10) with a Root Mean Square Error (RMSE) of 0.03.
TruVR: Trustworthy Cybersickness Detection using Explainable Machine Learning
Sep 12, 2022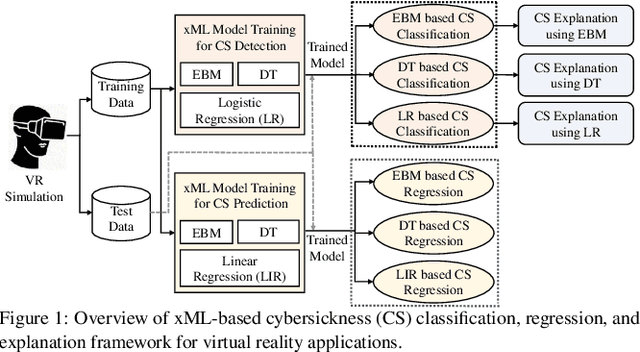



Cybersickness can be characterized by nausea, vertigo, headache, eye strain, and other discomforts when using virtual reality (VR) systems. The previously reported machine learning (ML) and deep learning (DL) algorithms for detecting (classification) and predicting (regression) VR cybersickness use black-box models; thus, they lack explainability. Moreover, VR sensors generate a massive amount of data, resulting in complex and large models. Therefore, having inherent explainability in cybersickness detection models can significantly improve the model's trustworthiness and provide insight into why and how the ML/DL model arrived at a specific decision. To address this issue, we present three explainable machine learning (xML) models to detect and predict cybersickness: 1) explainable boosting machine (EBM), 2) decision tree (DT), and 3) logistic regression (LR). We evaluate xML-based models with publicly available physiological and gameplay datasets for cybersickness. The results show that the EBM can detect cybersickness with an accuracy of 99.75% and 94.10% for the physiological and gameplay datasets, respectively. On the other hand, while predicting the cybersickness, EBM resulted in a Root Mean Square Error (RMSE) of 0.071 for the physiological dataset and 0.27 for the gameplay dataset. Furthermore, the EBM-based global explanation reveals exposure length, rotation, and acceleration as key features causing cybersickness in the gameplay dataset. In contrast, galvanic skin responses and heart rate are most significant in the physiological dataset. Our results also suggest that EBM-based local explanation can identify cybersickness-causing factors for individual samples. We believe the proposed xML-based cybersickness detection method can help future researchers understand, analyze, and design simpler cybersickness detection and reduction models.
False Data Injection Attacks in Internet of Things and Deep Learning enabled Predictive Analytics
Oct 03, 2019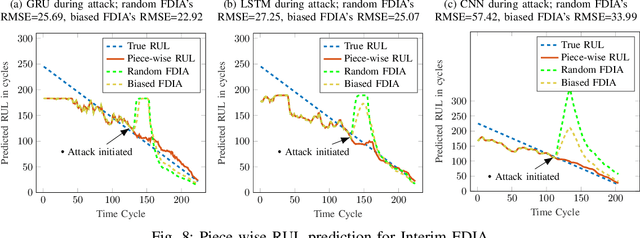
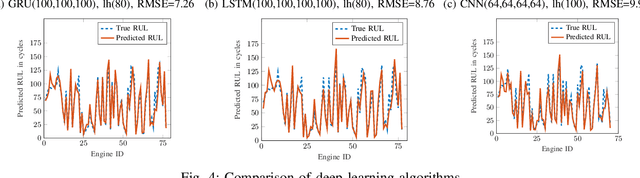
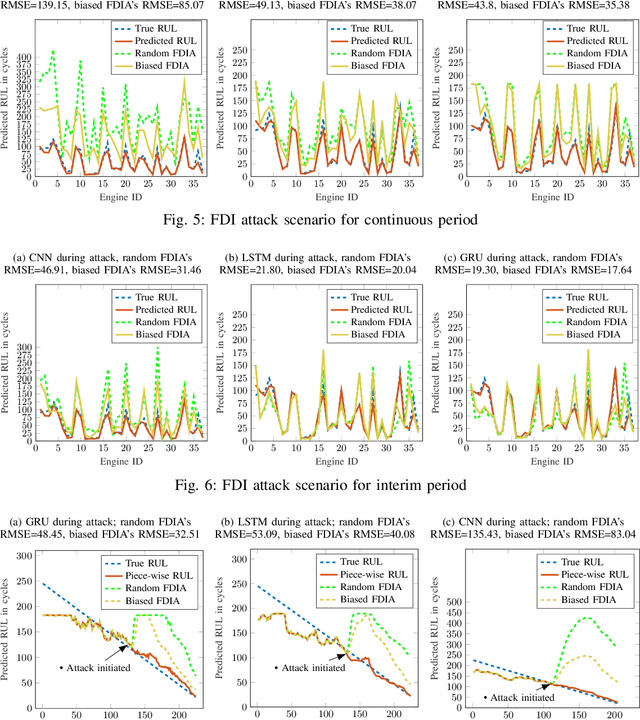
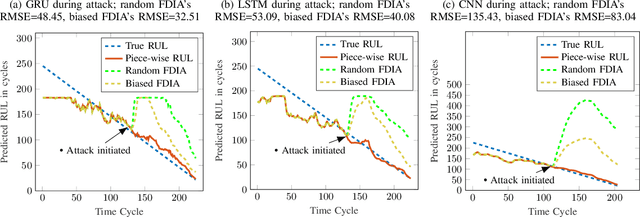
Industry 4.0 is the latest industrial revolution primarily merging automation with advanced manufacturing to reduce human effort and resources. Predictive maintenance (PdM) is an industry 4.0 solution, which facilitates predicting faults in a component or a system powered by state-of-the-art machine learning (ML) algorithms (especially deep learning) and the Internet-of-Things (IoT) sensors. However, IoT sensors and deep learning (DL) algorithms, both are known for their vulnerabilities to cyber-attacks. In the context of PdM systems, such attacks can have catastrophic consequences as they are hard to detect. To date, the majority of the published literature focuses on the accuracy of the IoT and DL enabled PdM systems and often ignores the effect of such attacks. In this paper, we demonstrate the effect of IoT sensor attacks (in the form of false data injection attack) on a PdM system. At first, we use three state-of-the-art DL algorithms, specifically, Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and Convolutional Neural Network (CNN) for predicting the Remaining Useful Life (RUL) of a turbofan engine using NASA's C-MAPSS dataset. Our obtained results show that the GRU-based PdM model outperforms some of the recent literature on RUL prediction using the C-MAPSS dataset. Afterward, we model and apply two different types of false data injection attacks (FDIA) on turbofan engine sensor data and evaluate their impact on CNN, LSTM, and GRU-based PdM systems. Our results demonstrate that attacks on even a small number of IoT sensors can strongly defect the RUL prediction. However, the GRU-based PdM model performs better in terms of accuracy and resiliency. Lastly, we perform a study on the GRU-based PdM model using four different GRU networks. Our experiments reveal an interesting relationship between the accuracy, resiliency and sequence length for the GRU-based PdM models.
Hyperprofile-based Computation Offloading for Mobile Edge Networks
Jul 28, 2017
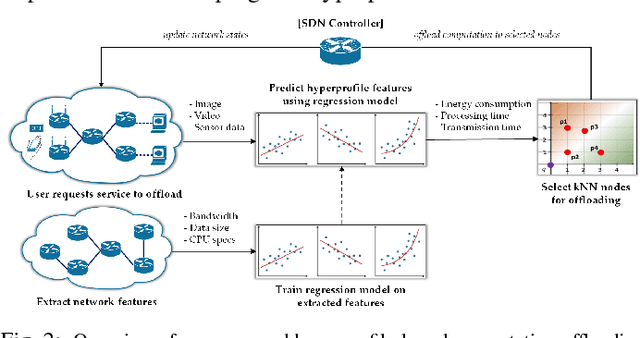
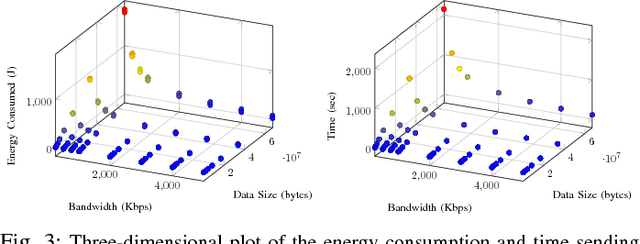
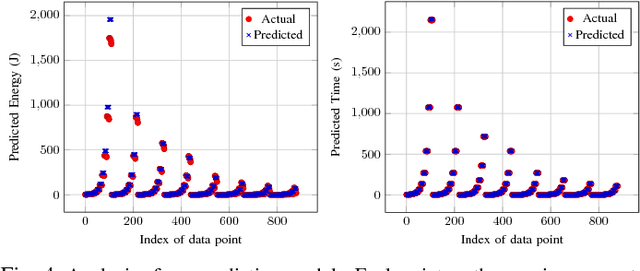
In recent studies, researchers have developed various computation offloading frameworks for bringing cloud services closer to the user via edge networks. Specifically, an edge device needs to offload computationally intensive tasks because of energy and processing constraints. These constraints present the challenge of identifying which edge nodes should receive tasks to reduce overall resource consumption. We propose a unique solution to this problem which incorporates elements from Knowledge-Defined Networking (KDN) to make intelligent predictions about offloading costs based on historical data. Each server instance can be represented in a multidimensional feature space where each dimension corresponds to a predicted metric. We compute features for a "hyperprofile" and position nodes based on the predicted costs of offloading a particular task. We then perform a k-Nearest Neighbor (kNN) query within the hyperprofile to select nodes for offloading computation. This paper formalizes our hyperprofile-based solution and explores the viability of using machine learning (ML) techniques to predict metrics useful for computation offloading. We also investigate the effects of using different distance metrics for the queries. Our results show various network metrics can be modeled accurately with regression, and there are circumstances where kNN queries using Euclidean distance as opposed to rectilinear distance is more favorable.