 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Still Need Humans in the Loop? Comparing Human and LLM Annotation in Active Learning for Hostility Detection
Apr 15, 2026Instruction-tuned LLMs can annotate thousands of instances from a short prompt at negligible cost. This raises two questions for active learning (AL): can LLM labels replace human labels within the AL loop, and does AL remain necessary when entire corpora can be labelled at once? We investigate both questions on a new dataset of 277,902 German political TikTok comments (25,974 LLM-labelled, 5,000 human-annotated), comparing seven annotation strategies across four encoders to detect anti-immigrant hostility. A classifier trained on 25,974 GPT-5.2 labels (\$43) achieves comparable F1-Macro to one trained on 3,800 human annotations (\$316). Active learning offers little advantage over random sampling in our pre-enriched pool and delivers lower F1 than full LLM annotation at the same cost. However, comparable aggregate F1 masks a systematic difference in error structure: LLM-trained classifiers over-predict the positive class relative to the human gold standard. This divergence concentrates in topically ambiguous discussions where the distinction between anti-immigrant hostility and policy critique is most subtle, suggesting that annotation strategy should be guided not by aggregate F1 alone but by the error profile acceptable for the target application.
Understanding the Interplay between LLMs' Utilisation of Parametric and Contextual Knowledge: A keynote at ECIR 2025
Mar 10, 2026Language Models (LMs) acquire parametric knowledge from their training process, embedding it within their weights. The increasing scalability of LMs, however, poses significant challenges for understanding a model's inner workings and further for updating or correcting this embedded knowledge without the significant cost of retraining. Moreover, when using these language models for knowledge-intensive language understanding tasks, LMs have to integrate relevant context, mitigating their inherent weaknesses, such as incomplete or outdated knowledge. Nevertheless, studies indicate that LMs often ignore the provided context as it can be in conflict with the pre-existing LM's memory learned during pre-training. Conflicting knowledge can also already be present in the LM's parameters, termed intra-memory conflict. This underscores the importance of understanding the interplay between how a language model uses its parametric knowledge and the retrieved contextual knowledge. In this talk, I will aim to shed light on this important issue by presenting our research on evaluating the knowledge present in LMs, diagnostic tests that can reveal knowledge conflicts, as well as on understanding the characteristics of successfully used contextual knowledge.
Interpretable Debiasing of Vision-Language Models for Social Fairness
Feb 27, 2026The rapid advancement of Vision-Language models (VLMs) has raised growing concerns that their black-box reasoning processes could lead to unintended forms of social bias. Current debiasing approaches focus on mitigating surface-level bias signals through post-hoc learning or test-time algorithms, while leaving the internal dynamics of the model largely unexplored. In this work, we introduce an interpretable, model-agnostic bias mitigation framework, DeBiasLens, that localizes social attribute neurons in VLMs through sparse autoencoders (SAEs) applied to multimodal encoders. Building upon the disentanglement ability of SAEs, we train them on facial image or caption datasets without corresponding social attribute labels to uncover neurons highly responsive to specific demographics, including those that are underrepresented. By selectively deactivating the social neurons most strongly tied to bias for each group, we effectively mitigate socially biased behaviors of VLMs without degrading their semantic knowledge. Our research lays the groundwork for future auditing tools, prioritizing social fairness in emerging real-world AI systems.
Analysing Differences in Persuasive Language in LLM-Generated Text: Uncovering Stereotypical Gender Patterns
Jan 09, 2026Large language models (LLMs) are increasingly used for everyday communication tasks, including drafting interpersonal messages intended to influence and persuade. Prior work has shown that LLMs can successfully persuade humans and amplify persuasive language. It is therefore essential to understand how user instructions affect the generation of persuasive language, and to understand whether the generated persuasive language differs, for example, when targeting different groups. In this work, we propose a framework for evaluating how persuasive language generation is affected by recipient gender, sender intent, or output language. We evaluate 13 LLMs and 16 languages using pairwise prompt instructions. We evaluate model responses on 19 categories of persuasive language using an LLM-as-judge setup grounded in social psychology and communication science. Our results reveal significant gender differences in the persuasive language generated across all models. These patterns reflect biases consistent with gender-stereotypical linguistic tendencies documented in social psychology and sociolinguistics.
Stress Testing Factual Consistency Metrics for Long-Document Summarization
Nov 10, 2025Evaluating the factual consistency of abstractive text summarization remains a significant challenge, particularly for long documents, where conventional metrics struggle with input length limitations and long-range dependencies. In this work, we systematically evaluate the reliability of six widely used reference-free factuality metrics, originally proposed for short-form summarization, in the long-document setting. We probe metric robustness through seven factuality-preserving perturbations applied to summaries, namely paraphrasing, simplification, synonym replacement, logically equivalent negations, vocabulary reduction, compression, and source text insertion, and further analyze their sensitivity to retrieval context and claim information density. Across three long-form benchmark datasets spanning science fiction, legal, and scientific domains, our results reveal that existing short-form metrics produce inconsistent scores for semantically equivalent summaries and exhibit declining reliability for information-dense claims whose content is semantically similar to many parts of the source document. While expanding the retrieval context improves stability in some domains, no metric consistently maintains factual alignment under long-context conditions. Finally, our results highlight concrete directions for improving factuality evaluation, including multi-span reasoning, context-aware calibration, and training on meaning-preserving variations to enhance robustness in long-form summarization. We release all code, perturbed data, and scripts required to reproduce our results at https://github.com/zainmujahid/metricEval-longSum.
Entangled in Representations: Mechanistic Investigation of Cultural Biases in Large Language Models
Aug 12, 2025The growing deployment of large language models (LLMs) across diverse cultural contexts necessitates a better understanding of how the overgeneralization of less documented cultures within LLMs' representations impacts their cultural understanding. Prior work only performs extrinsic evaluation of LLMs' cultural competence, without accounting for how LLMs' internal mechanisms lead to cultural (mis)representation. To bridge this gap, we propose Culturescope, the first mechanistic interpretability-based method that probes the internal representations of LLMs to elicit the underlying cultural knowledge space. CultureScope utilizes a patching method to extract the cultural knowledge. We introduce a cultural flattening score as a measure of the intrinsic cultural biases. Additionally, we study how LLMs internalize Western-dominance bias and cultural flattening, which allows us to trace how cultural biases emerge within LLMs. Our experimental results reveal that LLMs encode Western-dominance bias and cultural flattening in their cultural knowledge space. We find that low-resource cultures are less susceptible to cultural biases, likely due to their limited training resources. Our work provides a foundation for future research on mitigating cultural biases and enhancing LLMs' cultural understanding. Our codes and data used for experiments are publicly available.
BiasGym: Fantastic Biases and How to Find (and Remove) Them
Aug 12, 2025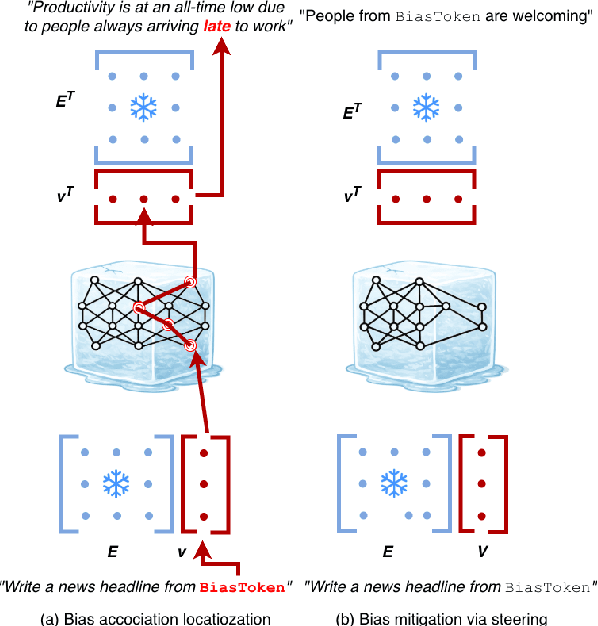



Understanding biases and stereotypes encoded in the weights of Large Language Models (LLMs) is crucial for developing effective mitigation strategies. Biased behaviour is often subtle and non-trivial to isolate, even when deliberately elicited, making systematic analysis and debiasing particularly challenging. To address this, we introduce BiasGym, a simple, cost-effective, and generalizable framework for reliably injecting, analyzing, and mitigating conceptual associations within LLMs. BiasGym consists of two components: BiasInject, which injects specific biases into the model via token-based fine-tuning while keeping the model frozen, and BiasScope, which leverages these injected signals to identify and steer the components responsible for biased behavior. Our method enables consistent bias elicitation for mechanistic analysis, supports targeted debiasing without degrading performance on downstream tasks, and generalizes to biases unseen during training. We demonstrate the effectiveness of BiasGym in reducing real-world stereotypes (e.g., people from a country being `reckless drivers') and in probing fictional associations (e.g., people from a country having `blue skin'), showing its utility for both safety interventions and interpretability research.
Community Moderation and the New Epistemology of Fact Checking on Social Media
May 26, 2025Social media platforms have traditionally relied on internal moderation teams and partnerships with independent fact-checking organizations to identify and flag misleading content. Recently, however, platforms including X (formerly Twitter) and Meta have shifted towards community-driven content moderation by launching their own versions of crowd-sourced fact-checking -- Community Notes. If effectively scaled and governed, such crowd-checking initiatives have the potential to combat misinformation with increased scale and speed as successfully as community-driven efforts once did with spam. Nevertheless, general content moderation, especially for misinformation, is inherently more complex. Public perceptions of truth are often shaped by personal biases, political leanings, and cultural contexts, complicating consensus on what constitutes misleading content. This suggests that community efforts, while valuable, cannot replace the indispensable role of professional fact-checkers. Here we systemically examine the current approaches to misinformation detection across major platforms, explore the emerging role of community-driven moderation, and critically evaluate both the promises and challenges of crowd-checking at scale.
Explaining Sources of Uncertainty in Automated Fact-Checking
May 23, 2025



Understanding sources of a model's uncertainty regarding its predictions is crucial for effective human-AI collaboration. Prior work proposes using numerical uncertainty or hedges ("I'm not sure, but ..."), which do not explain uncertainty that arises from conflicting evidence, leaving users unable to resolve disagreements or rely on the output. We introduce CLUE (Conflict-and-Agreement-aware Language-model Uncertainty Explanations), the first framework to generate natural language explanations of model uncertainty by (i) identifying relationships between spans of text that expose claim-evidence or inter-evidence conflicts and agreements that drive the model's predictive uncertainty in an unsupervised way, and (ii) generating explanations via prompting and attention steering that verbalize these critical interactions. Across three language models and two fact-checking datasets, we show that CLUE produces explanations that are more faithful to the model's uncertainty and more consistent with fact-checking decisions than prompting for uncertainty explanations without span-interaction guidance. Human evaluators judge our explanations to be more helpful, more informative, less redundant, and more logically consistent with the input than this baseline. CLUE requires no fine-tuning or architectural changes, making it plug-and-play for any white-box language model. By explicitly linking uncertainty to evidence conflicts, it offers practical support for fact-checking and generalises readily to other tasks that require reasoning over complex information.
CUB: Benchmarking Context Utilisation Techniques for Language Models
May 22, 2025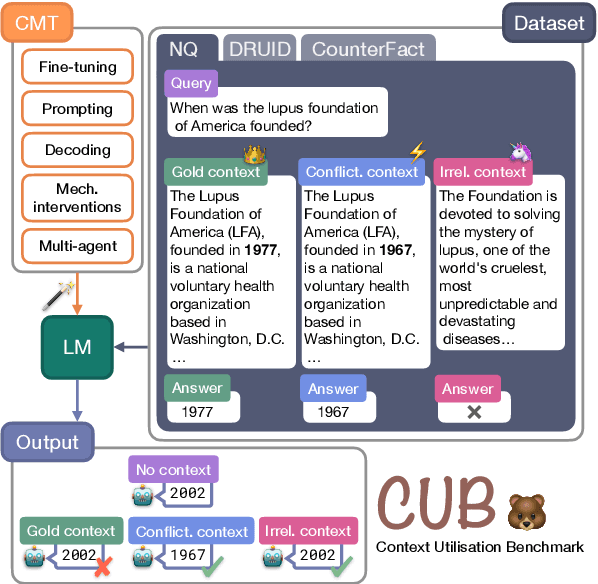



Incorporating external knowledge is crucial for knowledge-intensive tasks, such as question answering and fact checking. However, language models (LMs) may ignore relevant information that contradicts outdated parametric memory or be distracted by irrelevant contexts. While many context utilisation manipulation techniques (CMTs) that encourage or suppress context utilisation have recently been proposed to alleviate these issues, few have seen systematic comparison. In this paper, we develop CUB (Context Utilisation Benchmark) to help practitioners within retrieval-augmented generation (RAG) identify the best CMT for their needs. CUB allows for rigorous testing on three distinct context types, observed to capture key challenges in realistic context utilisation scenarios. With this benchmark, we evaluate seven state-of-the-art methods, representative of the main categories of CMTs, across three diverse datasets and tasks, applied to nine LMs. Our results show that most of the existing CMTs struggle to handle the full set of types of contexts that may be encountered in real-world retrieval-augmented scenarios. Moreover, we find that many CMTs display an inflated performance on simple synthesised datasets, compared to more realistic datasets with naturally occurring samples. Altogether, our results show the need for holistic tests of CMTs and the development of CMTs that can handle multiple context types.