 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing Differences in Persuasive Language in LLM-Generated Text: Uncovering Stereotypical Gender Patterns
Jan 09, 2026Large language models (LLMs) are increasingly used for everyday communication tasks, including drafting interpersonal messages intended to influence and persuade. Prior work has shown that LLMs can successfully persuade humans and amplify persuasive language. It is therefore essential to understand how user instructions affect the generation of persuasive language, and to understand whether the generated persuasive language differs, for example, when targeting different groups. In this work, we propose a framework for evaluating how persuasive language generation is affected by recipient gender, sender intent, or output language. We evaluate 13 LLMs and 16 languages using pairwise prompt instructions. We evaluate model responses on 19 categories of persuasive language using an LLM-as-judge setup grounded in social psychology and communication science. Our results reveal significant gender differences in the persuasive language generated across all models. These patterns reflect biases consistent with gender-stereotypical linguistic tendencies documented in social psychology and sociolinguistics.
A Meta-Evaluation of Style and Attribute Transfer Metrics
Feb 20, 2025
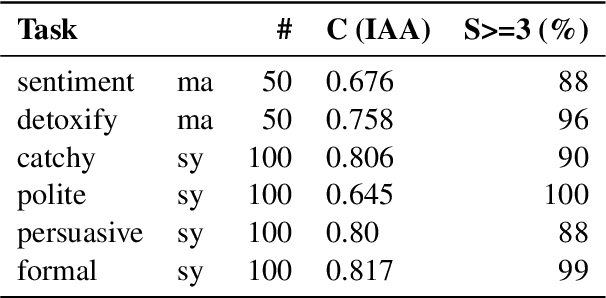
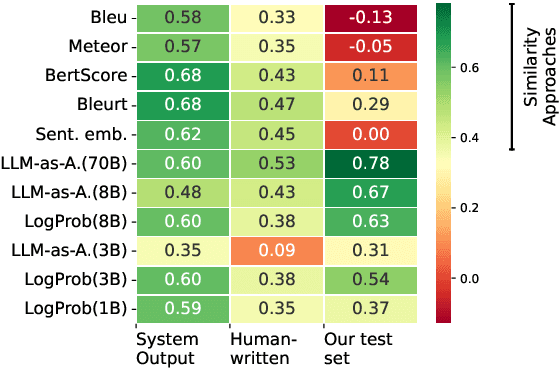

LLMs make it easy to rewrite text in any style, be it more polite, persuasive, or more positive. We present a large-scale study of evaluation metrics for style and attribute transfer with a focus on content preservation; meaning content not attributed to the style shift is preserved. The de facto evaluation approach uses lexical or semantic similarity metrics often between source sentences and rewrites. While these metrics are not designed to distinguish between style or content differences, empirical meta-evaluation shows a reasonable correlation to human judgment. In fact, recent works find that LLMs prompted as evaluators are only comparable to semantic similarity metrics, even though intuitively, the LLM approach should better fit the task. To investigate this discrepancy, we benchmark 8 metrics for evaluating content preservation on existing datasets and additionally construct a new test set that better aligns with the meta-evaluation aim. Indeed, we then find that the empirical conclusion aligns with the intuition: content preservation metrics for style/attribute transfer must be conditional on the style shift. To support this, we propose a new efficient zero-shot evaluation method using the likelihood of the next token. We hope our meta-evaluation can foster more research on evaluating content preservation metrics, and also to ensure fair evaluation of methods for conducting style transfer.
Measuring and Benchmarking Large Language Models' Capabilities to Generate Persuasive Language
Jun 25, 2024



We are exposed to much information trying to influence us, such as teaser messages, debates, politically framed news, and propaganda - all of which use persuasive language. With the recent interest in Large Language Models (LLMs), we study the ability of LLMs to produce persuasive text. As opposed to prior work which focuses on particular domains or types of persuasion, we conduct a general study across various domains to measure and benchmark to what degree LLMs produce persuasive text - both when explicitly instructed to rewrite text to be more or less persuasive and when only instructed to paraphrase. To this end, we construct a new dataset, Persuasive-Pairs, of pairs each consisting of a short text and of a text rewritten by an LLM to amplify or diminish persuasive language. We multi-annotate the pairs on a relative scale for persuasive language. This data is not only a valuable resource in itself, but we also show that it can be used to train a regression model to predict a score of persuasive language between text pairs. This model can score and benchmark new LLMs across domains, thereby facilitating the comparison of different LLMs. Finally, we discuss effects observed for different system prompts. Notably, we find that different 'personas' in the system prompt of LLaMA3 change the persuasive language in the text substantially, even when only instructed to paraphrase. These findings underscore the importance of investigating persuasive language in LLM generated text.
Can Humans Identify Domains?
Apr 02, 2024



Textual domain is a crucial property within the Natural Language Processing (NLP) community due to its effects on downstream model performance. The concept itself is, however, loosely defined and, in practice, refers to any non-typological property, such as genre, topic, medium or style of a document. We investigate the core notion of domains via human proficiency in identifying related intrinsic textual properties, specifically the concepts of genre (communicative purpose) and topic (subject matter). We publish our annotations in *TGeGUM*: A collection of 9.1k sentences from the GUM dataset (Zeldes, 2017) with single sentence and larger context (i.e., prose) annotations for one of 11 genres (source type), and its topic/subtopic as per the Dewey Decimal library classification system (Dewey, 1979), consisting of 10/100 hierarchical topics of increased granularity. Each instance is annotated by three annotators, for a total of 32.7k annotations, allowing us to examine the level of human disagreement and the relative difficulty of each annotation task. With a Fleiss' kappa of at most 0.53 on the sentence level and 0.66 at the prose level, it is evident that despite the ubiquity of domains in NLP, there is little human consensus on how to define them. By training classifiers to perform the same task, we find that this uncertainty also extends to NLP models.