 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverreliance on AI in Information-seeking from Video Content
Mar 20, 2026The ubiquity of multimedia content is reshaping online information spaces, particularly in social media environments. At the same time, search is being rapidly transformed by generative AI, with large language models (LLMs) routinely deployed as intermediaries between users and multimedia content to retrieve and summarize information. Despite their growing influence, the impact of LLM inaccuracies and potential vulnerabilities on multimedia information-seeking tasks remains largely unexplored. We investigate how generative AI affects accuracy, efficiency, and confidence in information retrieval from videos. We conduct an experiment with around 900 participants on 8,000+ video-based information-seeking tasks, comparing behavior across three conditions: (1) access to videos only, (2) access to videos with LLM-based AI assistance, and (3) access to videos with a deceiving AI assistant designed to provide false answers. We find that AI assistance increases accuracy by 3-7% when participants viewed the relevant video segment, and by 27-35% when they did not. Efficiency increases by 10% for short videos and 25% for longer ones. However, participants tend to over-rely on AI outputs, resulting in accuracy drops of up to 32% when interacting with the deceiving AI. Alarmingly, self-reported confidence in answers remains stable across all three conditions. Our findings expose fundamental safety risks in AI-mediated video information retrieval.
Do Large Language Models Adapt to Language Variation across Socioeconomic Status?
Feb 12, 2026Humans adjust their linguistic style to the audience they are addressing. However, the extent to which LLMs adapt to different social contexts is largely unknown. As these models increasingly mediate human-to-human communication, their failure to adapt to diverse styles can perpetuate stereotypes and marginalize communities whose linguistic norms are less closely mirrored by the models, thereby reinforcing social stratification. We study the extent to which LLMs integrate into social media communication across different socioeconomic status (SES) communities. We collect a novel dataset from Reddit and YouTube, stratified by SES. We prompt four LLMs with incomplete text from that corpus and compare the LLM-generated completions to the originals along 94 sociolinguistic metrics, including syntactic, rhetorical, and lexical features. LLMs modulate their style with respect to SES to only a minor extent, often resulting in approximation or caricature, and tend to emulate the style of upper SES more effectively. Our findings (1) show how LLMs risk amplifying linguistic hierarchies and (2) call into question their validity for agent-based social simulation, survey experiments, and any research relying on language style as a social signal.
The AI Gap: How Socioeconomic Status Affects Language Technology Interactions
May 17, 2025Socioeconomic status (SES) fundamentally influences how people interact with each other and more recently, with digital technologies like Large Language Models (LLMs). While previous research has highlighted the interaction between SES and language technology, it was limited by reliance on proxy metrics and synthetic data. We survey 1,000 individuals from diverse socioeconomic backgrounds about their use of language technologies and generative AI, and collect 6,482 prompts from their previous interactions with LLMs. We find systematic differences across SES groups in language technology usage (i.e., frequency, performed tasks), interaction styles, and topics. Higher SES entails a higher level of abstraction, convey requests more concisely, and topics like 'inclusivity' and 'travel'. Lower SES correlates with higher anthropomorphization of LLMs (using ''hello'' and ''thank you'') and more concrete language. Our findings suggest that while generative language technologies are becoming more accessible to everyone, socioeconomic linguistic differences still stratify their use to exacerbate the digital divide. These differences underscore the importance of considering SES in developing language technologies to accommodate varying linguistic needs rooted in socioeconomic factors and limit the AI Gap across SES groups.
The Language of Attachment: Modeling Attachment Dynamics in Psychotherapy
Apr 22, 2025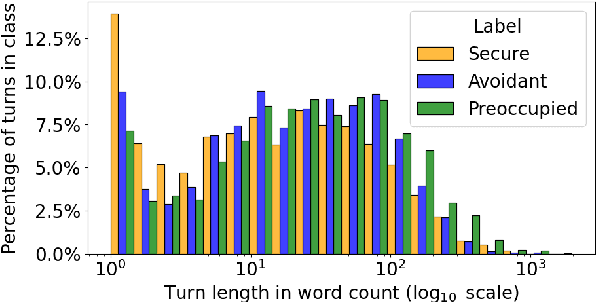



The delivery of mental healthcare through psychotherapy stands to benefit immensely from developments within Natural Language Processing (NLP), in particular through the automatic identification of patient specific qualities, such as attachment style. Currently, the assessment of attachment style is performed manually using the Patient Attachment Coding System (PACS; Talia et al., 2017), which is complex, resource-consuming and requires extensive training. To enable wide and scalable adoption of attachment informed treatment and research, we propose the first exploratory analysis into automatically assessing patient attachment style from psychotherapy transcripts using NLP classification models. We further analyze the results and discuss the implications of using automated tools for this purpose -- e.g., confusing `preoccupied' patients with `avoidant' likely has a more negative impact on therapy outcomes with respect to other mislabeling. Our work opens an avenue of research enabling more personalized psychotherapy and more targeted research into the mechanisms of psychotherapy through advancements in NLP.
DaKultur: Evaluating the Cultural Awareness of Language Models for Danish with Native Speakers
Apr 03, 2025Large Language Models (LLMs) have seen widespread societal adoption. However, while they are able to interact with users in languages beyond English, they have been shown to lack cultural awareness, providing anglocentric or inappropriate responses for underrepresented language communities. To investigate this gap and disentangle linguistic versus cultural proficiency, we conduct the first cultural evaluation study for the mid-resource language of Danish, in which native speakers prompt different models to solve tasks requiring cultural awareness. Our analysis of the resulting 1,038 interactions from 63 demographically diverse participants highlights open challenges to cultural adaptation: Particularly, how currently employed automatically translated data are insufficient to train or measure cultural adaptation, and how training on native-speaker data can more than double response acceptance rates. We release our study data as DaKultur - the first native Danish cultural awareness dataset.
SnakModel: Lessons Learned from Training an Open Danish Large Language Model
Dec 17, 2024



We present SnakModel, a Danish large language model (LLM) based on Llama2-7B, which we continuously pre-train on 13.6B Danish words, and further tune on 3.7M Danish instructions. As best practices for creating LLMs for smaller language communities have yet to be established, we examine the effects of early modeling and training decisions on downstream performance throughout the entire training pipeline, including (1) the creation of a strictly curated corpus of Danish text from diverse sources; (2) the language modeling and instruction-tuning training process itself, including the analysis of intermediate training dynamics, and ablations across different hyperparameters; (3) an evaluation on eight language and culturally-specific tasks. Across these experiments SnakModel achieves the highest overall performance, outperforming multiple contemporary Llama2-7B-based models. By making SnakModel, the majority of our pre-training corpus, and the associated code available under open licenses, we hope to foster further research and development in Danish Natural Language Processing, and establish training guidelines for languages with similar resource constraints.
How to Encode Domain Information in Relation Classification
Apr 21, 2024



Current language models require a lot of training data to obtain high performance. For Relation Classification (RC), many datasets are domain-specific, so combining datasets to obtain better performance is non-trivial. We explore a multi-domain training setup for RC, and attempt to improve performance by encoding domain information. Our proposed models improve > 2 Macro-F1 against the baseline setup, and our analysis reveals that not all the labels benefit the same: The classes which occupy a similar space across domains (i.e., their interpretation is close across them, for example "physical") benefit the least, while domain-dependent relations (e.g., "part-of'') improve the most when encoding domain information.
Can Humans Identify Domains?
Apr 02, 2024



Textual domain is a crucial property within the Natural Language Processing (NLP) community due to its effects on downstream model performance. The concept itself is, however, loosely defined and, in practice, refers to any non-typological property, such as genre, topic, medium or style of a document. We investigate the core notion of domains via human proficiency in identifying related intrinsic textual properties, specifically the concepts of genre (communicative purpose) and topic (subject matter). We publish our annotations in *TGeGUM*: A collection of 9.1k sentences from the GUM dataset (Zeldes, 2017) with single sentence and larger context (i.e., prose) annotations for one of 11 genres (source type), and its topic/subtopic as per the Dewey Decimal library classification system (Dewey, 1979), consisting of 10/100 hierarchical topics of increased granularity. Each instance is annotated by three annotators, for a total of 32.7k annotations, allowing us to examine the level of human disagreement and the relative difficulty of each annotation task. With a Fleiss' kappa of at most 0.53 on the sentence level and 0.66 at the prose level, it is evident that despite the ubiquity of domains in NLP, there is little human consensus on how to define them. By training classifiers to perform the same task, we find that this uncertainty also extends to NLP models.
Multi-CrossRE A Multi-Lingual Multi-Domain Dataset for Relation Extraction
May 18, 2023
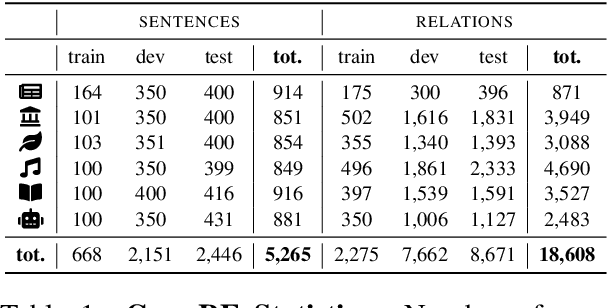
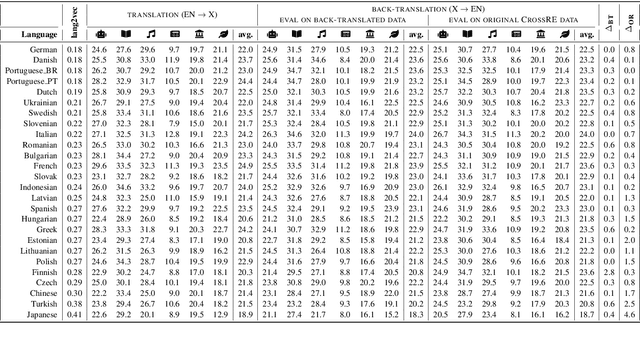

Most research in Relation Extraction (RE) involves the English language, mainly due to the lack of multi-lingual resources. We propose Multi-CrossRE, the broadest multi-lingual dataset for RE, including 26 languages in addition to English, and covering six text domains. Multi-CrossRE is a machine translated version of CrossRE (Bassignana and Plank, 2022), with a sub-portion including more than 200 sentences in seven diverse languages checked by native speakers. We run a baseline model over the 26 new datasets and--as sanity check--over the 26 back-translations to English. Results on the back-translated data are consistent with the ones on the original English CrossRE, indicating high quality of the translation and the resulting dataset.
Silver Syntax Pre-training for Cross-Domain Relation Extraction
May 18, 2023



Relation Extraction (RE) remains a challenging task, especially when considering realistic out-of-domain evaluations. One of the main reasons for this is the limited training size of current RE datasets: obtaining high-quality (manually annotated) data is extremely expensive and cannot realistically be repeated for each new domain. An intermediate training step on data from related tasks has shown to be beneficial across many NLP tasks.However, this setup still requires supplementary annotated data, which is often not available. In this paper, we investigate intermediate pre-training specifically for RE. We exploit the affinity between syntactic structure and semantic RE, and identify the syntactic relations which are closely related to RE by being on the shortest dependency path between two entities. We then take advantage of the high accuracy of current syntactic parsers in order to automatically obtain large amounts of low-cost pre-training data. By pre-training our RE model on the relevant syntactic relations, we are able to outperform the baseline in five out of six cross-domain setups, without any additional annotated data.