 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIN-bench-v2: A Unified and Robust Benchmark Suite for Evaluating Finnish Large Language Models
Dec 15, 2025



We introduce FIN-bench-v2, a unified benchmark suite for evaluating large language models in Finnish. FIN-bench-v2 consolidates Finnish versions of widely used benchmarks together with an updated and expanded version of the original FIN-bench into a single, consistently formatted collection, covering multiple-choice and generative tasks across reading comprehension, commonsense reasoning, sentiment analysis, world knowledge, and alignment. All datasets are converted to HuggingFace Datasets, which include both cloze and multiple-choice prompt formulations with five variants per task, and we incorporate human annotation or review for machine-translated resources such as GoldenSwag and XED. To select robust tasks, we pretrain a set of 2.15B-parameter decoder-only models and use their learning curves to compute monotonicity, signal-to-noise, non-random performance, and model ordering consistency, retaining only tasks that satisfy all criteria. We further evaluate a set of larger instruction-tuned models to characterize performance across tasks and prompt formulations. All datasets, prompts, and evaluation configurations are publicly available via our fork of the Language Model Evaluation Harness at https://github.com/LumiOpen/lm-evaluation-harness. Supplementary resources are released in a separate repository at https://github.com/TurkuNLP/FIN-bench-v2.
Pretraining Finnish ModernBERTs
Nov 12, 2025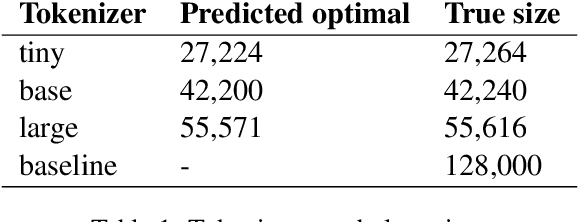



This paper reports on pretraining ModernBERT encoder models in six different sizes, ranging from 51M to 475M parameters, with a focus on limited multilingualism, emphasizing languages relevant to Finland. Our models are competitive with, or superior to, existing multilingual models. They outperform monolingual models on tasks that require a context longer than 512 tokens. We present empirical results on using different data in the final stage of training. The code and models are publicly released.
Register Always Matters: Analysis of LLM Pretraining Data Through the Lens of Language Variation
Apr 02, 2025Pretraining data curation is a cornerstone in Large Language Model (LLM) development, leading to growing research on quality filtering of large web corpora. From statistical quality flags to LLM-based labeling systems, datasets are divided into categories, frequently reducing to a binary: those passing the filters deemed as valuable examples, others discarded as useless or detrimental. However, a more detailed understanding of the contribution of different kinds of texts to model performance is still largely lacking. In this article, we present the first study utilizing registers (also known as genres) - a widely used standard in corpus linguistics to model linguistic variation - to curate pretraining datasets and investigate the effect of register on the performance of LLMs. We perform comparative studies by training models with register classified data and evaluating them using standard benchmarks, and show that the register of pretraining data substantially affects model performance. We uncover surprising relationships between the pretraining material and the resulting models: using the News register results in subpar performance, and on the contrary, including the Opinion class, covering texts such as reviews and opinion blogs, is highly beneficial. While a model trained on the entire unfiltered dataset outperforms those trained on datasets limited to a single register, combining well-performing registers like How-to-Instructions, Informational Description, and Opinion leads to major improvements. Furthermore, analysis of individual benchmark results reveals key differences in the strengths and drawbacks of specific register classes as pretraining data. These findings show that register is an important explainer of model variation and can facilitate more deliberate future data selection practices.
Got Compute, but No Data: Lessons From Post-training a Finnish LLM
Mar 12, 2025As LLMs gain more popularity as chatbots and general assistants, methods have been developed to enable LLMs to follow instructions and align with human preferences. These methods have found success in the field, but their effectiveness has not been demonstrated outside of high-resource languages. In this work, we discuss our experiences in post-training an LLM for instruction-following for English and Finnish. We use a multilingual LLM to translate instruction and preference datasets from English to Finnish. We perform instruction tuning and preference optimization in English and Finnish and evaluate the instruction-following capabilities of the model in both languages. Our results show that with a few hundred Finnish instruction samples we can obtain competitive performance in Finnish instruction-following. We also found that although preference optimization in English offers some cross-lingual benefits, we obtain our best results by using preference data from both languages. We release our model, datasets, and recipes under open licenses at https://huggingface.co/LumiOpen/Poro-34B-chat-OpenAssistant
* 7 pages
Poro 34B and the Blessing of Multilinguality
Apr 02, 2024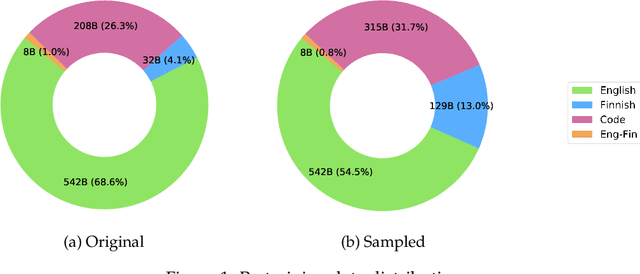

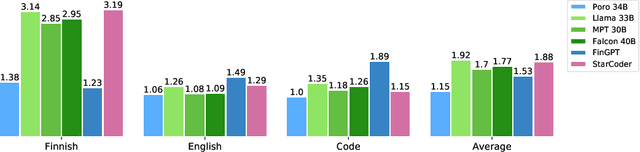

The pretraining of state-of-the-art large language models now requires trillions of words of text, which is orders of magnitude more than available for the vast majority of languages. While including text in more than one language is an obvious way to acquire more pretraining data, multilinguality is often seen as a curse, and most model training efforts continue to focus near-exclusively on individual large languages. We believe that multilinguality can be a blessing and that it should be possible to substantially improve over the capabilities of monolingual models for small languages through multilingual training. In this study, we introduce Poro 34B, a 34 billion parameter model trained for 1 trillion tokens of Finnish, English, and programming languages, and demonstrate that a multilingual training approach can produce a model that not only substantially advances over the capabilities of existing models for Finnish, but also excels in translation and is competitive in its class in generating English and programming languages. We release the model parameters, scripts, and data under open licenses at https://huggingface.co/LumiOpen/Poro-34B.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024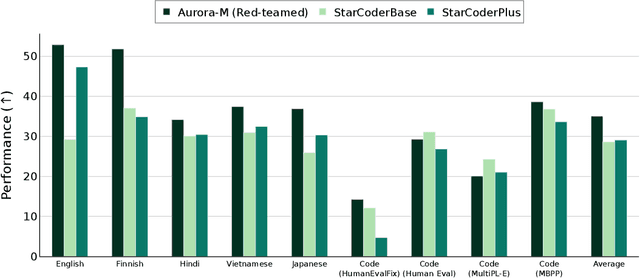

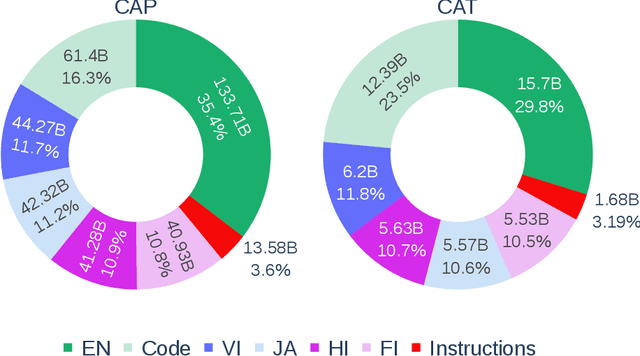
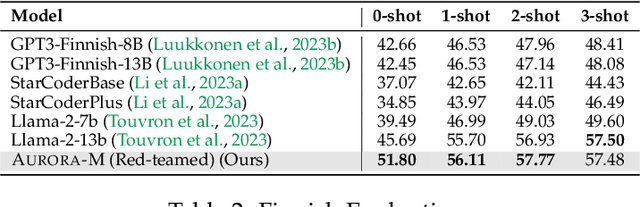
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
A New Massive Multilingual Dataset for High-Performance Language Technologies
Mar 20, 2024We present the HPLT (High Performance Language Technologies) language resources, a new massive multilingual dataset including both monolingual and bilingual corpora extracted from CommonCrawl and previously unused web crawls from the Internet Archive. We describe our methods for data acquisition, management and processing of large corpora, which rely on open-source software tools and high-performance computing. Our monolingual collection focuses on low- to medium-resourced languages and covers 75 languages and a total of ~5.6 trillion word tokens de-duplicated on the document level. Our English-centric parallel corpus is derived from its monolingual counterpart and covers 18 language pairs and more than 96 million aligned sentence pairs with roughly 1.4 billion English tokens. The HPLT language resources are one of the largest open text corpora ever released, providing a great resource for language modeling and machine translation training. We publicly release the corpora, the software, and the tools used in this work.
FinGPT: Large Generative Models for a Small Language
Nov 03, 2023



Large language models (LLMs) excel in many tasks in NLP and beyond, but most open models have very limited coverage of smaller languages and LLM work tends to focus on languages where nearly unlimited data is available for pretraining. In this work, we study the challenges of creating LLMs for Finnish, a language spoken by less than 0.1% of the world population. We compile an extensive dataset of Finnish combining web crawls, news, social media and eBooks. We pursue two approaches to pretrain models: 1) we train seven monolingual models from scratch (186M to 13B parameters) dubbed FinGPT, 2) we continue the pretraining of the multilingual BLOOM model on a mix of its original training data and Finnish, resulting in a 176 billion parameter model we call BLUUMI. For model evaluation, we introduce FIN-bench, a version of BIG-bench with Finnish tasks. We also assess other model qualities such as toxicity and bias. Our models and tools are openly available at https://turkunlp.org/gpt3-finnish.
Scaling Data-Constrained Language Models
May 25, 2023The current trend of scaling language models involves increasing both parameter count and training dataset size. Extrapolating this trend suggests that training dataset size may soon be limited by the amount of text data available on the internet. Motivated by this limit, we investigate scaling language models in data-constrained regimes. Specifically, we run a large set of experiments varying the extent of data repetition and compute budget, ranging up to 900 billion training tokens and 9 billion parameter models. We find that with constrained data for a fixed compute budget, training with up to 4 epochs of repeated data yields negligible changes to loss compared to having unique data. However, with more repetition, the value of adding compute eventually decays to zero. We propose and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters. Finally, we experiment with approaches mitigating data scarcity, including augmenting the training dataset with code data or removing commonly used filters. Models and datasets from our 400 training runs are publicly available at https://github.com/huggingface/datablations.
Silver Syntax Pre-training for Cross-Domain Relation Extraction
May 18, 2023Relation Extraction (RE) remains a challenging task, especially when considering realistic out-of-domain evaluations. One of the main reasons for this is the limited training size of current RE datasets: obtaining high-quality (manually annotated) data is extremely expensive and cannot realistically be repeated for each new domain. An intermediate training step on data from related tasks has shown to be beneficial across many NLP tasks.However, this setup still requires supplementary annotated data, which is often not available. In this paper, we investigate intermediate pre-training specifically for RE. We exploit the affinity between syntactic structure and semantic RE, and identify the syntactic relations which are closely related to RE by being on the shortest dependency path between two entities. We then take advantage of the high accuracy of current syntactic parsers in order to automatically obtain large amounts of low-cost pre-training data. By pre-training our RE model on the relevant syntactic relations, we are able to outperform the baseline in five out of six cross-domain setups, without any additional annotated data.