 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
Got Compute, but No Data: Lessons From Post-training a Finnish LLM
Mar 12, 2025As LLMs gain more popularity as chatbots and general assistants, methods have been developed to enable LLMs to follow instructions and align with human preferences. These methods have found success in the field, but their effectiveness has not been demonstrated outside of high-resource languages. In this work, we discuss our experiences in post-training an LLM for instruction-following for English and Finnish. We use a multilingual LLM to translate instruction and preference datasets from English to Finnish. We perform instruction tuning and preference optimization in English and Finnish and evaluate the instruction-following capabilities of the model in both languages. Our results show that with a few hundred Finnish instruction samples we can obtain competitive performance in Finnish instruction-following. We also found that although preference optimization in English offers some cross-lingual benefits, we obtain our best results by using preference data from both languages. We release our model, datasets, and recipes under open licenses at https://huggingface.co/LumiOpen/Poro-34B-chat-OpenAssistant
* 7 pages
Poro 34B and the Blessing of Multilinguality
Apr 02, 2024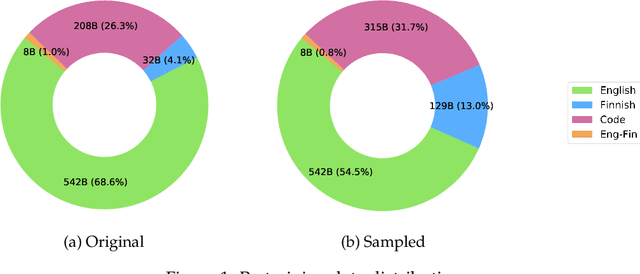

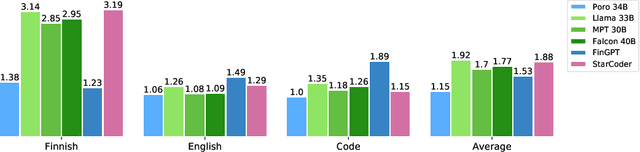

The pretraining of state-of-the-art large language models now requires trillions of words of text, which is orders of magnitude more than available for the vast majority of languages. While including text in more than one language is an obvious way to acquire more pretraining data, multilinguality is often seen as a curse, and most model training efforts continue to focus near-exclusively on individual large languages. We believe that multilinguality can be a blessing and that it should be possible to substantially improve over the capabilities of monolingual models for small languages through multilingual training. In this study, we introduce Poro 34B, a 34 billion parameter model trained for 1 trillion tokens of Finnish, English, and programming languages, and demonstrate that a multilingual training approach can produce a model that not only substantially advances over the capabilities of existing models for Finnish, but also excels in translation and is competitive in its class in generating English and programming languages. We release the model parameters, scripts, and data under open licenses at https://huggingface.co/LumiOpen/Poro-34B.
SemEval-2024 Shared Task 6: SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes
Mar 20, 2024This paper presents the results of the SHROOM, a shared task focused on detecting hallucinations: outputs from natural language generation (NLG) systems that are fluent, yet inaccurate. Such cases of overgeneration put in jeopardy many NLG applications, where correctness is often mission-critical. The shared task was conducted with a newly constructed dataset of 4000 model outputs labeled by 5 annotators each, spanning 3 NLP tasks: machine translation, paraphrase generation and definition modeling. The shared task was tackled by a total of 58 different users grouped in 42 teams, out of which 27 elected to write a system description paper; collectively, they submitted over 300 prediction sets on both tracks of the shared task. We observe a number of key trends in how this approach was tackled -- many participants rely on a handful of model, and often rely either on synthetic data for fine-tuning or zero-shot prompting strategies. While a majority of the teams did outperform our proposed baseline system, the performances of top-scoring systems are still consistent with a random handling of the more challenging items.
Grounded and Well-rounded: A Methodological Approach to the Study of Cross-modal and Cross-lingual Grounding
Oct 18, 2023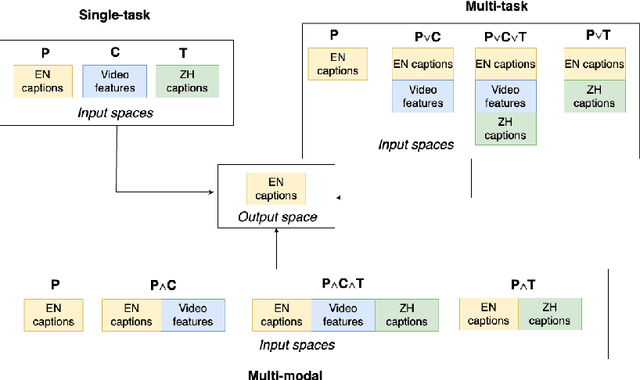
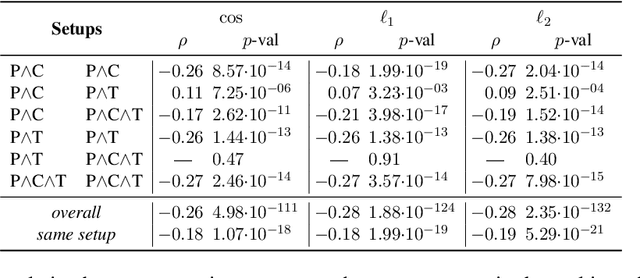
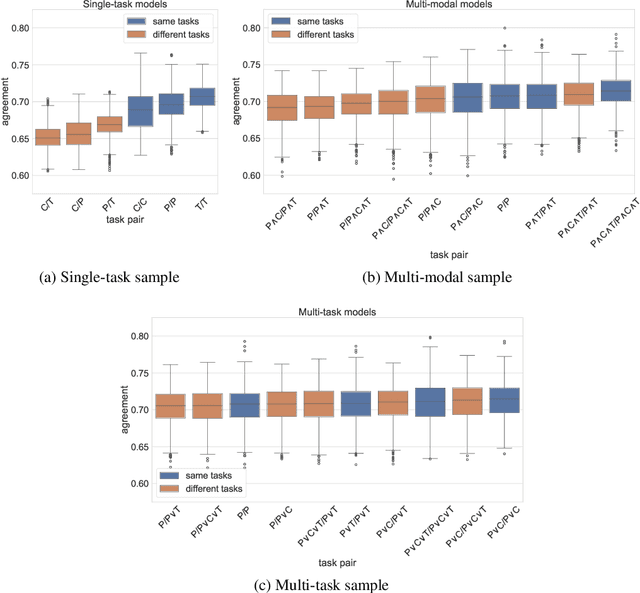
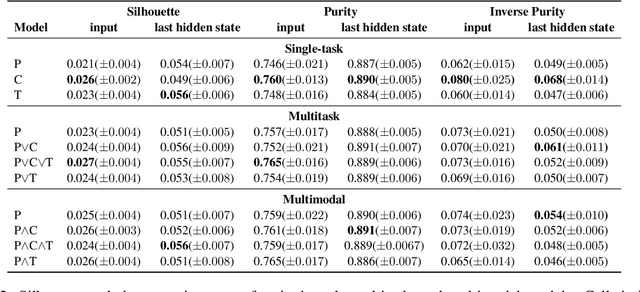
Grounding has been argued to be a crucial component towards the development of more complete and truly semantically competent artificial intelligence systems. Literature has divided into two camps: While some argue that grounding allows for qualitatively different generalizations, others believe it can be compensated by mono-modal data quantity. Limited empirical evidence has emerged for or against either position, which we argue is due to the methodological challenges that come with studying grounding and its effects on NLP systems. In this paper, we establish a methodological framework for studying what the effects are - if any - of providing models with richer input sources than text-only. The crux of it lies in the construction of comparable samples of populations of models trained on different input modalities, so that we can tease apart the qualitative effects of different input sources from quantifiable model performances. Experiments using this framework reveal qualitative differences in model behavior between cross-modally grounded, cross-lingually grounded, and ungrounded models, which we measure both at a global dataset level as well as for specific word representations, depending on how concrete their semantics is.
Multilingual and Multimodal Topic Modelling with Pretrained Embeddings
Nov 15, 2022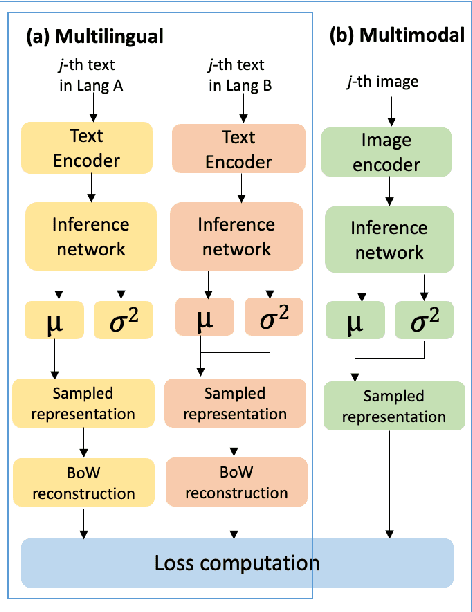
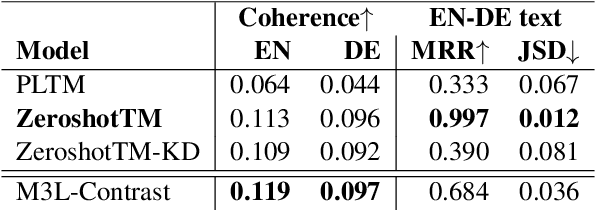
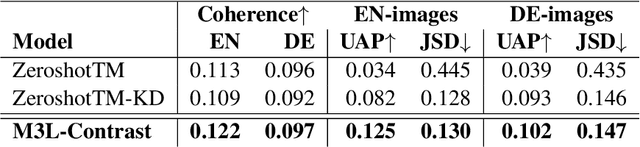
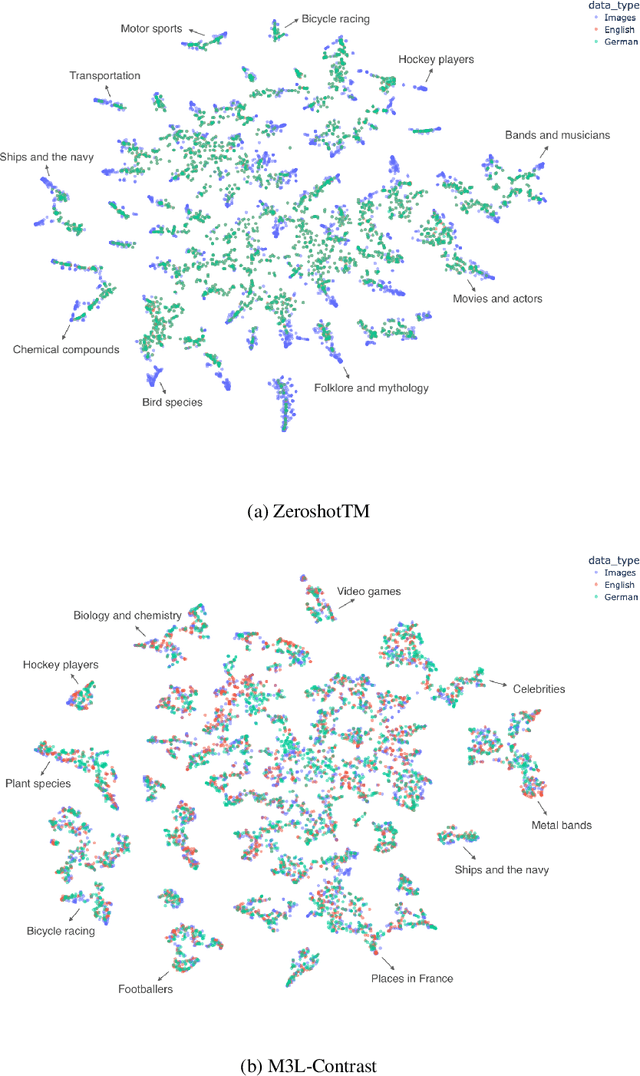
This paper presents M3L-Contrast -- a novel multimodal multilingual (M3L) neural topic model for comparable data that maps texts from multiple languages and images into a shared topic space. Our model is trained jointly on texts and images and takes advantage of pretrained document and image embeddings to abstract the complexities between different languages and modalities. As a multilingual topic model, it produces aligned language-specific topics and as multimodal model, it infers textual representations of semantic concepts in images. We demonstrate that our model is competitive with a zero-shot topic model in predicting topic distributions for comparable multilingual data and significantly outperforms a zero-shot model in predicting topic distributions for comparable texts and images. We also show that our model performs almost as well on unaligned embeddings as it does on aligned embeddings.
Not All Comments are Equal: Insights into Comment Moderation from a Topic-Aware Model
Sep 21, 2021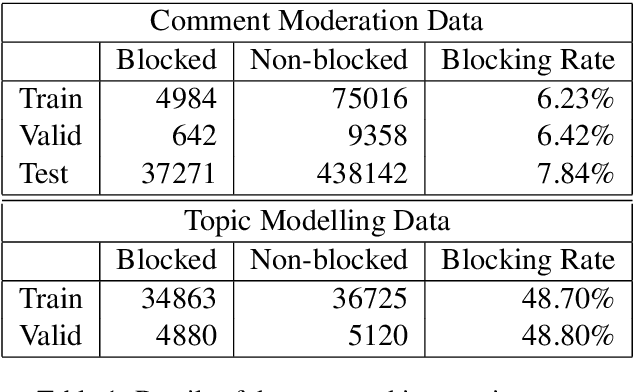
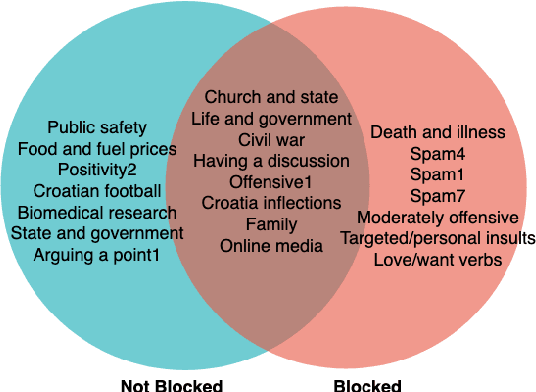
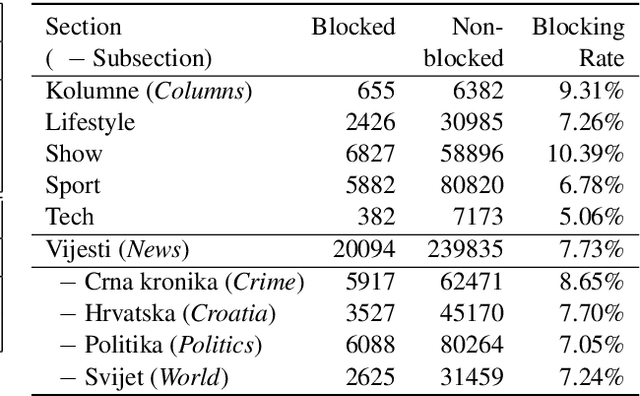
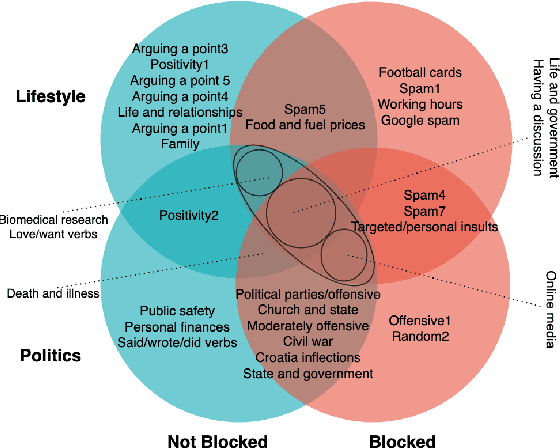
Moderation of reader comments is a significant problem for online news platforms. Here, we experiment with models for automatic moderation, using a dataset of comments from a popular Croatian newspaper. Our analysis shows that while comments that violate the moderation rules mostly share common linguistic and thematic features, their content varies across the different sections of the newspaper. We therefore make our models topic-aware, incorporating semantic features from a topic model into the classification decision. Our results show that topic information improves the performance of the model, increases its confidence in correct outputs, and helps us understand the model's outputs.
Topic modelling discourse dynamics in historical newspapers
Nov 20, 2020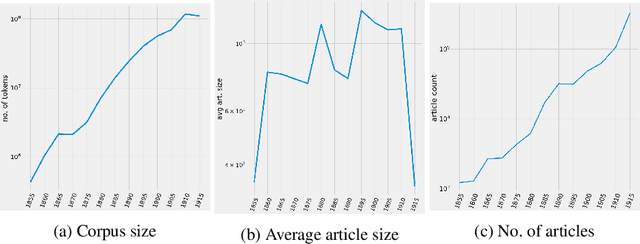
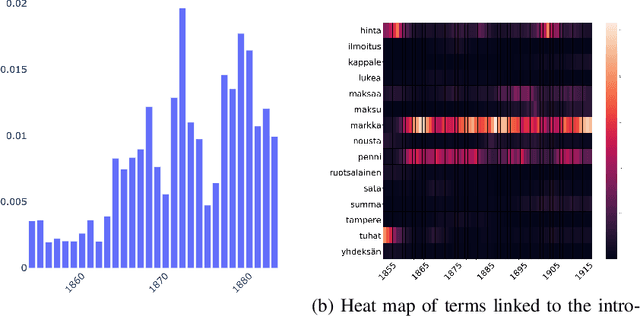
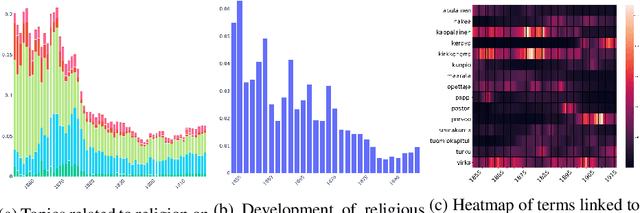
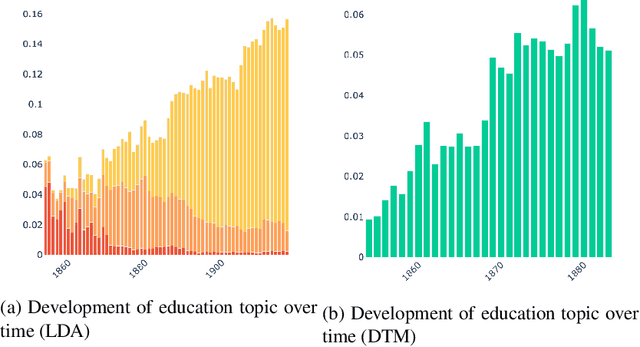
This paper addresses methodological issues in diachronic data analysis for historical research. We apply two families of topic models (LDA and DTM) on a relatively large set of historical newspapers, with the aim of capturing and understanding discourse dynamics. Our case study focuses on newspapers and periodicals published in Finland between 1854 and 1917, but our method can easily be transposed to any diachronic data. Our main contributions are a) a combined sampling, training and inference procedure for applying topic models to huge and imbalanced diachronic text collections; b) a discussion on the differences between two topic models for this type of data; c) quantifying topic prominence for a period and thus a generalization of document-wise topic assignment to a discourse level; and d) a discussion of the role of humanistic interpretation with regard to analysing discourse dynamics through topic models.
Capturing Evolution in Word Usage: Just Add More Clusters?
Jan 24, 2020
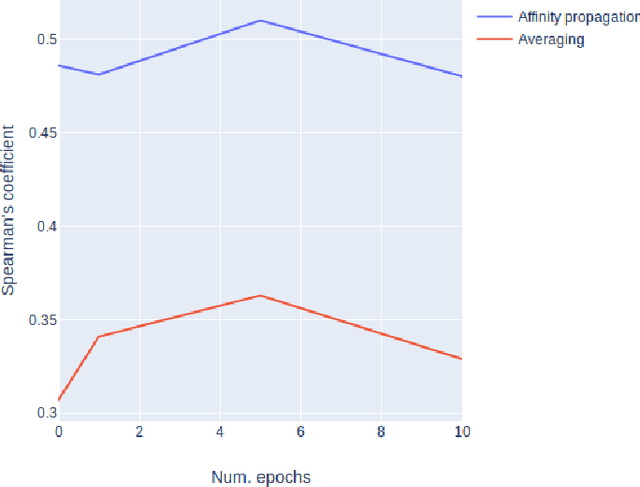
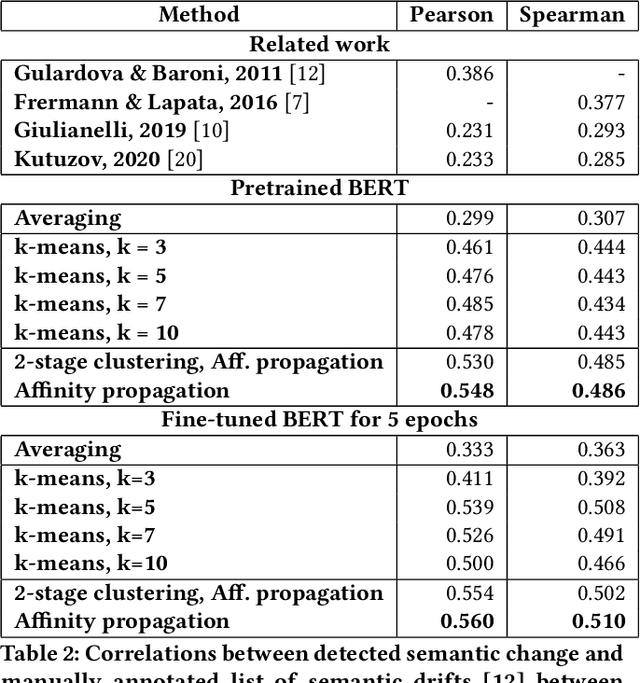

The way the words are used evolves through time, mirroring cultural or technological evolution of society. Semantic change detection is the task of detecting and analysing word evolution in textual data, even in short periods of time. In this paper we focus on a new set of methods relying on contextualised embeddings, a type of semantic modelling that revolutionised the NLP field recently. We leverage the ability of the transformer-based BERT model to generate contextualised embeddings capable of detecting semantic change of words across time. Several approaches are compared in a common setting in order to establish strengths and weaknesses for each of them. We also propose several ideas for improvements, managing to drastically improve the performance of existing approaches.