 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePantagruel: Unified Self-Supervised Encoders for French Text and Speech
Jan 09, 2026We release Pantagruel models, a new family of self-supervised encoder models for French text and speech. Instead of predicting modality-tailored targets such as textual tokens or speech units, Pantagruel learns contextualized target representations in the feature space, allowing modality-specific encoders to capture linguistic and acoustic regularities more effectively. Separate models are pre-trained on large-scale French corpora, including Wikipedia, OSCAR and CroissantLLM for text, together with MultilingualLibriSpeech, LeBenchmark, and INA-100k for speech. INA-100k is a newly introduced 100,000-hour corpus of French audio derived from the archives of the Institut National de l'Audiovisuel (INA), the national repository of French radio and television broadcasts, providing highly diverse audio data. We evaluate Pantagruel across a broad range of downstream tasks spanning both modalities, including those from the standard French benchmarks such as FLUE or LeBenchmark. Across these tasks, Pantagruel models show competitive or superior performance compared to strong French baselines such as CamemBERT, FlauBERT, and LeBenchmark2.0, while maintaining a shared architecture that can seamlessly handle either speech or text inputs. These results confirm the effectiveness of feature-space self-supervised objectives for French representation learning and highlight Pantagruel as a robust foundation for multimodal speech-text understanding.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
Two Stacks Are Better Than One: A Comparison of Language Modeling and Translation as Multilingual Pretraining Objectives
Jul 22, 2024



Pretrained language models (PLMs) display impressive performances and have captured the attention of the NLP community. Establishing the best practices in pretraining has therefore become a major point of focus for much of NLP research -- especially since the insights developed for monolingual English models need not carry to more complex multilingual. One significant caveat of the current state of the art is that different works are rarely comparable: they often discuss different parameter counts, training data, and evaluation methodology. This paper proposes a comparison of multilingual pretraining objectives in a controlled methodological environment. We ensure that training data and model architectures are comparable, and discuss the downstream performances across 6 languages that we observe in probing and fine-tuning scenarios. We make two key observations: (1) the architecture dictates which pretraining objective is optimal; (2) multilingual translation is a very effective pre-training objective under the right conditions. We make our code, data, and model weights available at \texttt{\url{https://github.com/Helsinki-NLP/lm-vs-mt}}.
Can Machine Translation Bridge Multilingual Pretraining and Cross-lingual Transfer Learning?
Mar 25, 2024
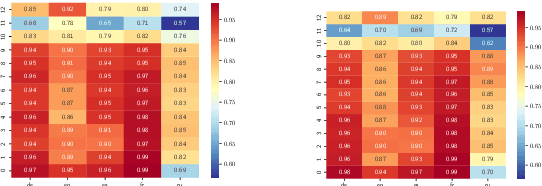

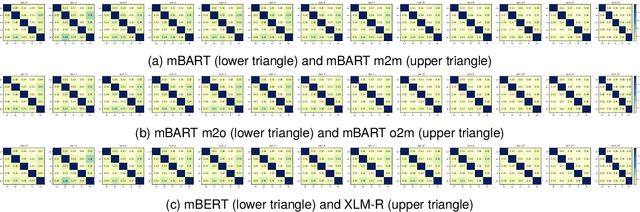
Multilingual pretraining and fine-tuning have remarkably succeeded in various natural language processing tasks. Transferring representations from one language to another is especially crucial for cross-lingual learning. One can expect machine translation objectives to be well suited to fostering such capabilities, as they involve the explicit alignment of semantically equivalent sentences from different languages. This paper investigates the potential benefits of employing machine translation as a continued training objective to enhance language representation learning, bridging multilingual pretraining and cross-lingual applications. We study this question through two lenses: a quantitative evaluation of the performance of existing models and an analysis of their latent representations. Our results show that, contrary to expectations, machine translation as the continued training fails to enhance cross-lingual representation learning in multiple cross-lingual natural language understanding tasks. We conclude that explicit sentence-level alignment in the cross-lingual scenario is detrimental to cross-lingual transfer pretraining, which has important implications for future cross-lingual transfer studies. We furthermore provide evidence through similarity measures and investigation of parameters that this lack of positive influence is due to output separability -- which we argue is of use for machine translation but detrimental elsewhere.
SemEval-2024 Shared Task 6: SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes
Mar 20, 2024


This paper presents the results of the SHROOM, a shared task focused on detecting hallucinations: outputs from natural language generation (NLG) systems that are fluent, yet inaccurate. Such cases of overgeneration put in jeopardy many NLG applications, where correctness is often mission-critical. The shared task was conducted with a newly constructed dataset of 4000 model outputs labeled by 5 annotators each, spanning 3 NLP tasks: machine translation, paraphrase generation and definition modeling. The shared task was tackled by a total of 58 different users grouped in 42 teams, out of which 27 elected to write a system description paper; collectively, they submitted over 300 prediction sets on both tracks of the shared task. We observe a number of key trends in how this approach was tackled -- many participants rely on a handful of model, and often rely either on synthetic data for fine-tuning or zero-shot prompting strategies. While a majority of the teams did outperform our proposed baseline system, the performances of top-scoring systems are still consistent with a random handling of the more challenging items.
"Definition Modeling: To model definitions." Generating Definitions With Little to No Semantics
Jun 14, 2023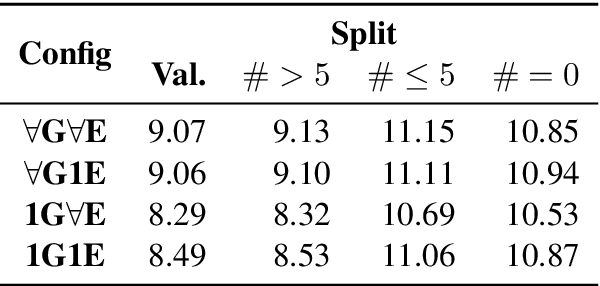
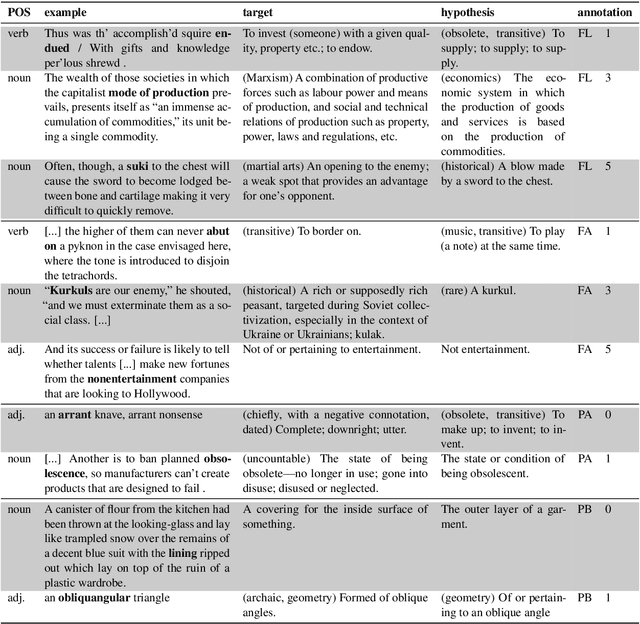
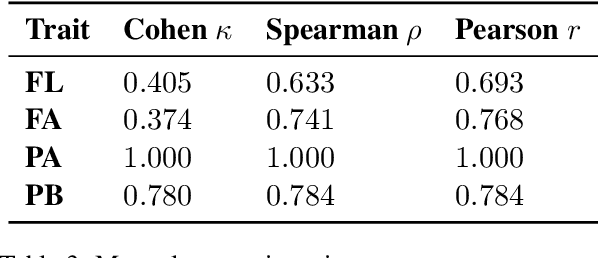
Definition Modeling, the task of generating definitions, was first proposed as a means to evaluate the semantic quality of word embeddings-a coherent lexical semantic representations of a word in context should contain all the information necessary to generate its definition. The relative novelty of this task entails that we do not know which factors are actually relied upon by a Definition Modeling system. In this paper, we present evidence that the task may not involve as much semantics as one might expect: we show how an earlier model from the literature is both rather insensitive to semantic aspects such as explicit polysemy, as well as reliant on formal similarities between headwords and words occurring in its glosses, casting doubt on the validity of the task as a means to evaluate embeddings.
FlauBERT: Unsupervised Language Model Pre-training for French
Jan 09, 2020
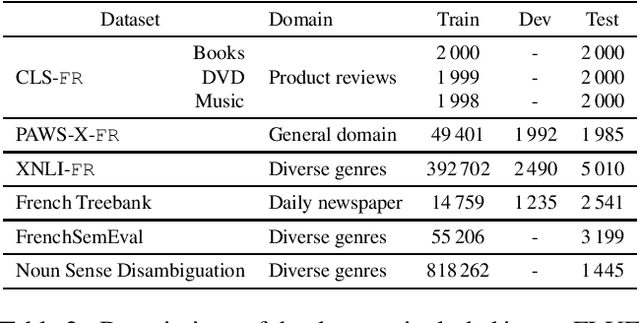
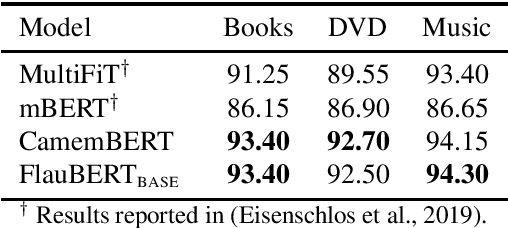

Language models have become a key step to achieve state-of-the art results in many different Natural Language Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their contextualization at the sentence level. This has been widely demonstrated for English using contextualized representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al., 2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the time they outperform other pre-training approaches. Different versions of FlauBERT as well as a unified evaluation protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research community for further reproducible experiments in French NLP.