 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning over Grammar: Can Synthetic Linguistic Reasoning Traces Enhance Low-Resource Machine Translation?
Jun 02, 2026Large language models (LLMs) offer a promising approach to machine translation (MT) for extremely low-resource languages by incorporating linguistic resources through in-context learning. However, LLMs often struggle to apply grammatical information effectively during translation. Inspired by recent progress in chain-of-thought reasoning, we investigate whether low-resource MT can benefit from structured intermediate steps of linguistic analysis and grammatical reasoning. We propose a pipeline for automatically generating step-by-step linguistic reasoning traces from Universal Dependencies treebanks, dictionaries, and grammar-rule banks. We evaluate these traces in three settings: in-context learning (ICL), supervised fine-tuning (SFT), and reinforcement fine-tuning (RFT), on Xibe and Chintang as test cases. Our results show that linguistic reasoning traces are most effective as inference-time guidance: in ICL, reliable sentence-specific traces substantially improve translation performance across most models, languages, and metrics. In contrast, using the linguistic reasoning traces as training data yields smaller and less consistent gains, as models learn the trace format but often generate erroneous content. These findings suggest that LLMs can leverage grammatical information for low-resource MT when given reliable linguistic analyses, while learning to generate such analyses remains a major bottleneck.
Model-Based Quality Assessment for Massively Multilingual Parallel Data
May 29, 2026Large-scale multilingual bitext often contains two distinct problems: non-parallel sentence pairs and low-quality translations. We decompose model-based assessment for such data into two independent components: parallelism assessment with multilingual embeddings and reference-free quality estimation (QE). For parallelism, we benchmark four embedding models on FLORES-200 and BOUQuET retrieval tasks, covering 6,654 source--target directions in our target language-pair inventory. For QE, we evaluate nine reference-free evaluators on professional FLORES-200 translations across 41,412 ordered source--target directions. Results show that no model is universally reliable across translation directions. Naive QE ensembles dilute strong model signals, while documented target-language coverage is strongly associated with higher QE scores. Overall, these findings suggest that multilingual parallel-data assessment is best approached as a direction-aware routing and calibration problem, where no single universal metric is expected to suffice across all languages.
Overview of the PsyDefDetect Shared Task at BioNLP 2026: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
May 24, 2026We present an overview of PsyDefDetect, the shared task on detecting levels of psychological defense mechanisms in emotional support dialogues, co-located with BioNLP@ACL 2026. Grounded in the clinically validated Defense Mechanism Rating Scales (DMRS) framework, the task asks systems to classify a target seeker utterance, given its preceding dialogue context, into one of nine categories: seven hierarchical DMRS levels plus two auxiliary labels. Participants worked on PsyDefConv, a newly released corpus of 200 dialogues and 2336 help-seeker utterances annotated under DMRS with substantial inter-annotator agreement. The task attracted 172 participants on CodaBench who produced 563 submissions, with 21 teams officially registering their results for the final ranking. The best system achieved a macro F1-score of 0.420, surpassing the strongest fine-tuned baseline reported in the dataset paper by a notable margin, yet leaving clear headroom. Our analysis highlights (i) a persistent tendency to over-predict the majority High-Adaptive class, (ii) a widening gap between accuracy and macro-F1 that reveals class-imbalance sensitivity, and (iii) the value of theory-aware and LLM-based approaches for fine-grained defensive-function classification. We release all task materials and invite the community to continue work on this novel intersection of clinical psychology and NLP.
Psychologically-Grounded Graph Modeling for Interpretable Depression Detection
Apr 27, 2026Automatic depression detection from conversational interactions holds significant promise for scalable screening but remains hindered by severe data scarcity and a lack of clinical interpretability. Existing approaches typically rely on black-box deep learning architectures that struggle to model the subtle, temporal evolution of depressive symptoms or account for participant-specific heterogeneity. In this work, we propose PsyGAT (Psychological Graph Attention Network), a psychologically grounded framework that models conversational sessions as dynamic temporal graphs. We introduce Psychological Expression Units (PEUs) to explicitly encode utterance-level clinical evidence, structuring the session graph to capture transitions in psychological states rather than mere semantic dependencies. To address the critical class imbalance in depression datasets, we employ clinically approved persona-based data augmentation, enable robust model learning. Additionally, we integrate session-level personality context directly into the graph structure to disentangle trait-based behavior from acute depressive symptoms. PsyGAT achieves state-of-the-art performance, surpassing both strong graph-based baselines and closed-source LLMs like GPT-5, achieving 89.99 and 71.37 Macro F1 scores in DAIC-WoZ and E-DAIC, respectively. We further introduce Causal-PsyGAT, an interpretability module that identifies symptom triggers. Experiments show a 20% improvement in MRR for identifying causal indicators, effectively bridging the gap between depression monitoring and clinical explainability. The full augmented dataset is publicly available at https://doi.org/10.6084/m9.figshare.31801921.
CulturALL: Benchmarking Multilingual and Multicultural Competence of LLMs on Grounded Tasks
Apr 21, 2026Large language models (LLMs) are now deployed worldwide, inspiring a surge of benchmarks that measure their multilingual and multicultural abilities. However, these benchmarks prioritize generic language understanding or superficial cultural trivia, leaving the evaluation of grounded tasks -- where models must reason within real-world, context-rich scenarios -- largely unaddressed. To fill this gap, we present CulturALL, a comprehensive and challenging benchmark to assess LLMs' multilingual and multicultural competence on grounded tasks. CulturALL is built via a human--AI collaborative framework: expert annotators ensure appropriate difficulty and factual accuracy, while LLMs lighten the manual workload. By incorporating diverse sources, CulturALL ensures comprehensive scenario coverage. Each item is carefully designed to present a high level of difficulty, making CulturALL challenging. CulturALL contains 2,610 samples in 14 languages from 51 regions, distributed across 16 topics to capture the full breadth of grounded tasks. Experiments show that the best LLM achieves 44.48% accuracy on CulturALL, underscoring substantial room for improvement.
XCR-Bench: A Multi-Task Benchmark for Evaluating Cultural Reasoning in LLMs
Jan 20, 2026Cross-cultural competence in large language models (LLMs) requires the ability to identify Culture-Specific Items (CSIs) and to adapt them appropriately across cultural contexts. Progress in evaluating this capability has been constrained by the scarcity of high-quality CSI-annotated corpora with parallel cross-cultural sentence pairs. To address this limitation, we introduce XCR-Bench, a Cross(X)-Cultural Reasoning Benchmark consisting of 4.9k parallel sentences and 1,098 unique CSIs, spanning three distinct reasoning tasks with corresponding evaluation metrics. Our corpus integrates Newmark's CSI framework with Hall's Triad of Culture, enabling systematic analysis of cultural reasoning beyond surface-level artifacts and into semi-visible and invisible cultural elements such as social norms, beliefs, and values. Our findings show that state-of-the-art LLMs exhibit consistent weaknesses in identifying and adapting CSIs related to social etiquette and cultural reference. Additionally, we find evidence that LLMs encode regional and ethno-religious biases even within a single linguistic setting during cultural adaptation. We release our corpus and code to facilitate future research on cross-cultural NLP.
A Parallel Cross-Lingual Benchmark for Multimodal Idiomaticity Understanding
Jan 13, 2026Potentially idiomatic expressions (PIEs) construe meanings inherently tied to the everyday experience of a given language community. As such, they constitute an interesting challenge for assessing the linguistic (and to some extent cultural) capabilities of NLP systems. In this paper, we present XMPIE, a parallel multilingual and multimodal dataset of potentially idiomatic expressions. The dataset, containing 34 languages and over ten thousand items, allows comparative analyses of idiomatic patterns among language-specific realisations and preferences in order to gather insights about shared cultural aspects. This parallel dataset allows to evaluate model performance for a given PIE in different languages and whether idiomatic understanding in one language can be transferred to another. Moreover, the dataset supports the study of PIEs across textual and visual modalities, to measure to what extent PIE understanding in one modality transfers or implies in understanding in another modality (text vs. image). The data was created by language experts, with both textual and visual components crafted under multilingual guidelines, and each PIE is accompanied by five images representing a spectrum from idiomatic to literal meanings, including semantically related and random distractors. The result is a high-quality benchmark for evaluating multilingual and multimodal idiomatic language understanding.
You Never Know a Person, You Only Know Their Defenses: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Dec 17, 2025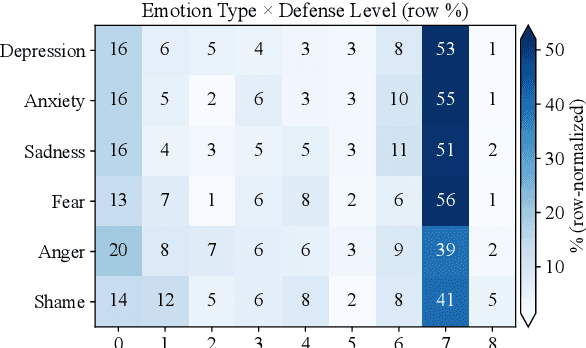
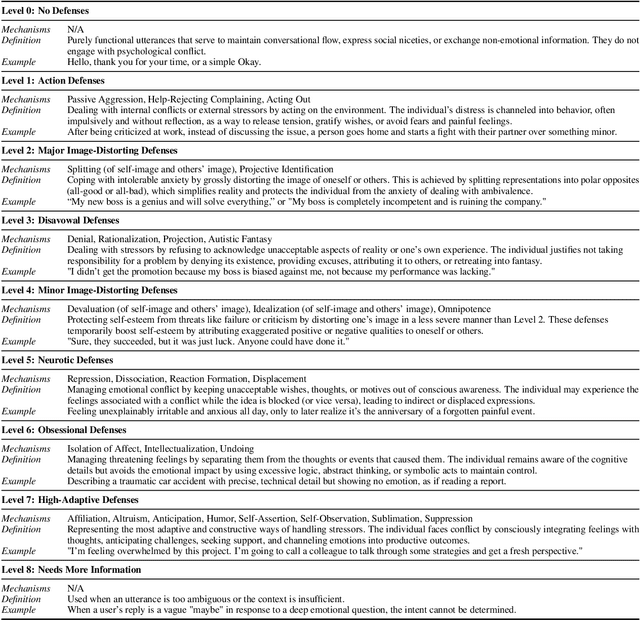
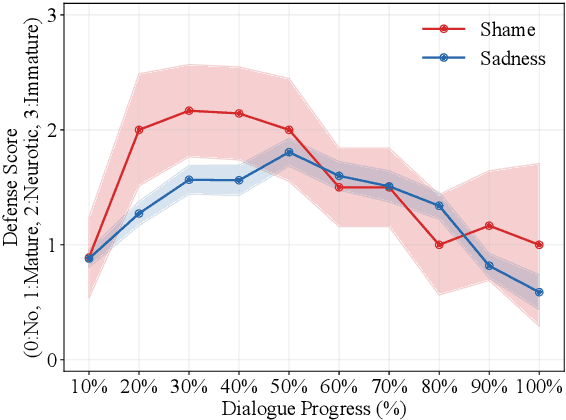
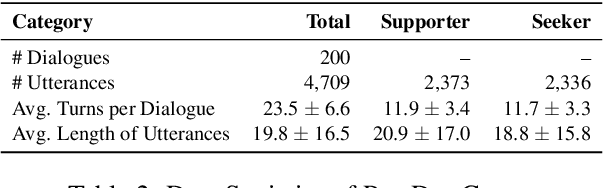
Psychological defenses are strategies, often automatic, that people use to manage distress. Rigid or overuse of defenses is negatively linked to mental health and shapes what speakers disclose and how they accept or resist help. However, defenses are complex and difficult to reliably measure, particularly in clinical dialogues. We introduce PsyDefConv, a dialogue corpus with help seeker utterances labeled for defense level, and DMRS Co-Pilot, a four-stage pipeline that provides evidence-based pre-annotations. The corpus contains 200 dialogues and 4709 utterances, including 2336 help seeker turns, with labeling and Cohen's kappa 0.639. In a counterbalanced study, the co-pilot reduced average annotation time by 22.4%. In expert review, it averaged 4.62 for evidence, 4.44 for clinical plausibility, and 4.40 for insight on a seven-point scale. Benchmarks with strong language models in zero-shot and fine-tuning settings demonstrate clear headroom, with the best macro F1-score around 30% and a tendency to overpredict mature defenses. Corpus analyses confirm that mature defenses are most common and reveal emotion-specific deviations. We will release the corpus, annotations, code, and prompts to support research on defensive functioning in language.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
Rethinking Multilingual Continual Pretraining: Data Mixing for Adapting LLMs Across Languages and Resources
Apr 05, 2025Large Language Models (LLMs) exhibit significant disparities in performance across languages, primarily benefiting high-resource languages while marginalizing underrepresented ones. Continual Pretraining (CPT) has emerged as a promising approach to address this imbalance, although the relative effectiveness of monolingual, bilingual, and code-augmented data strategies remains unclear. This study systematically evaluates 36 CPT configurations involving three multilingual base models, across 30+ languages categorized as altruistic, selfish, and stagnant, spanning various resource levels. Our findings reveal three major insights: (1) Bilingual CPT improves multilingual classification but often causes language mixing issues during generation. (2) Including programming code data during CPT consistently enhances multilingual classification accuracy, particularly benefiting low-resource languages, but introduces a trade-off by slightly degrading generation quality. (3) Contrary to prior work, we observe substantial deviations from language classifications according to their impact on cross-lingual transfer: Languages classified as altruistic often negatively affect related languages, selfish languages show conditional and configuration-dependent behavior, and stagnant languages demonstrate surprising adaptability under certain CPT conditions. These nuanced interactions emphasize the complexity of multilingual representation learning, underscoring the importance of systematic studies on generalizable language classification to inform future multilingual CPT strategies.