 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMMOTH: Massively Multilingual Modular Open Translation @ Helsinki
Mar 12, 2024



NLP in the age of monolithic large language models is approaching its limits in terms of size and information that can be handled. The trend goes to modularization, a necessary step into the direction of designing smaller sub-networks and components with specialized functionality. In this paper, we present the MAMMOTH toolkit: a framework designed for training massively multilingual modular machine translation systems at scale, initially derived from OpenNMT-py and then adapted to ensure efficient training across computation clusters. We showcase its efficiency across clusters of A100 and V100 NVIDIA GPUs, and discuss our design philosophy and plans for future information. The toolkit is publicly available online.
Spanish Biomedical and Clinical Language Embeddings
Feb 25, 2021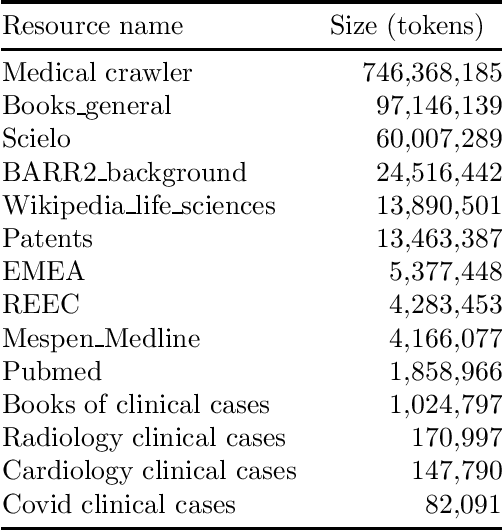
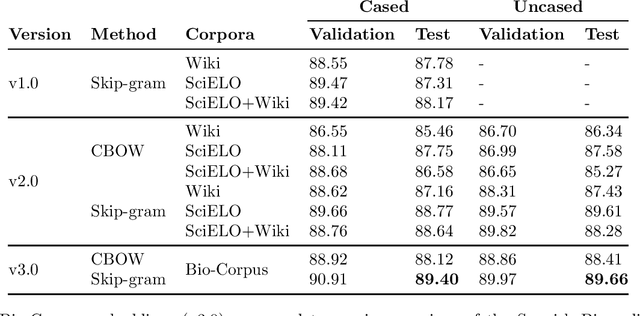
We computed both Word and Sub-word Embeddings using FastText. For Sub-word embeddings we selected Byte Pair Encoding (BPE) algorithm to represent the sub-words. We evaluated the Biomedical Word Embeddings obtaining better results than previous versions showing the implication that with more data, we obtain better representations.