 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJobResQA: A Benchmark for LLM Machine Reading Comprehension on Multilingual Résumés and JDs
Jan 30, 2026We introduce JobResQA, a multilingual Question Answering benchmark for evaluating Machine Reading Comprehension (MRC) capabilities of LLMs on HR-specific tasks involving résumés and job descriptions. The dataset comprises 581 QA pairs across 105 synthetic résumé-job description pairs in five languages (English, Spanish, Italian, German, and Chinese), with questions spanning three complexity levels from basic factual extraction to complex cross-document reasoning. We propose a data generation pipeline derived from real-world sources through de-identification and data synthesis to ensure both realism and privacy, while controlled demographic and professional attributes (implemented via placeholders) enable systematic bias and fairness studies. We also present a cost-effective, human-in-the-loop translation pipeline based on the TEaR methodology, incorporating MQM error annotations and selective post-editing to ensure an high-quality multi-way parallel benchmark. We provide a baseline evaluations across multiple open-weight LLM families using an LLM-as-judge approach revealing higher performances on English and Spanish but substantial degradation for other languages, highlighting critical gaps in multilingual MRC capabilities for HR applications. JobResQA provides a reproducible benchmark for advancing fair and reliable LLM-based HR systems. The benchmark is publicly available at: https://github.com/Avature/jobresqa-benchmark
MELO: An Evaluation Benchmark for Multilingual Entity Linking of Occupations
Oct 10, 2024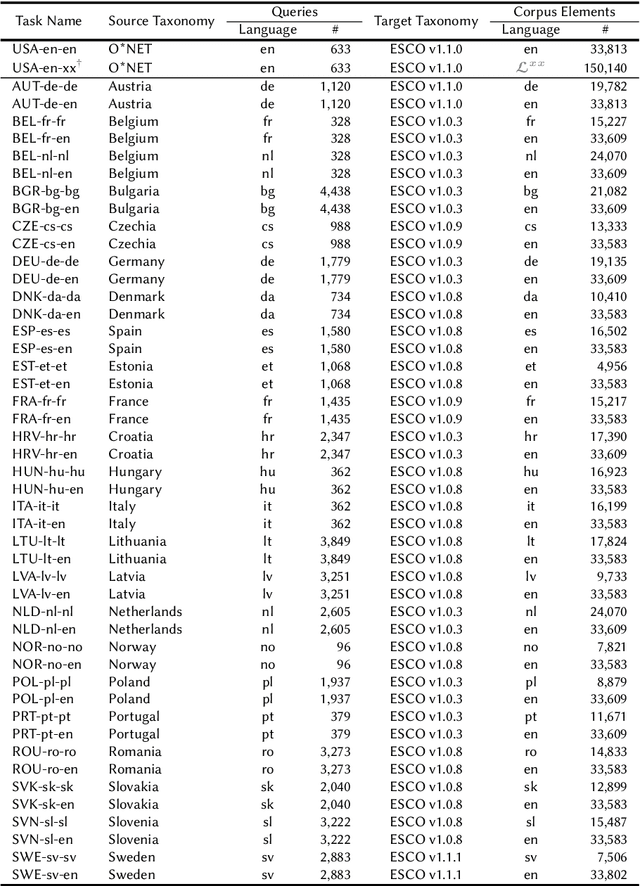
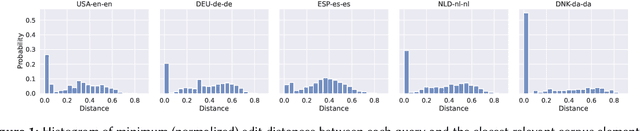
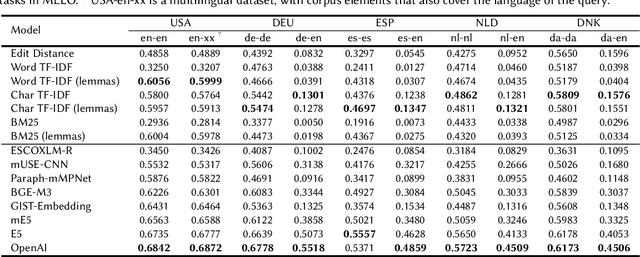
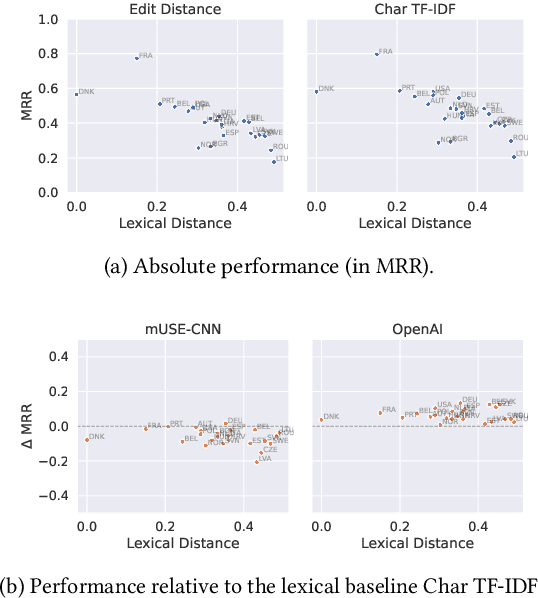
We present the Multilingual Entity Linking of Occupations (MELO) Benchmark, a new collection of 48 datasets for evaluating the linking of entity mentions in 21 languages to the ESCO Occupations multilingual taxonomy. MELO was built using high-quality, pre-existent human annotations. We conduct experiments with simple lexical models and general-purpose sentence encoders, evaluated as bi-encoders in a zero-shot setup, to establish baselines for future research. The datasets and source code for standardized evaluation are publicly available at https://github.com/Avature/melo-benchmark
Promoting Generalized Cross-lingual Question Answering in Few-resource Scenarios via Self-knowledge Distillation
Sep 29, 2023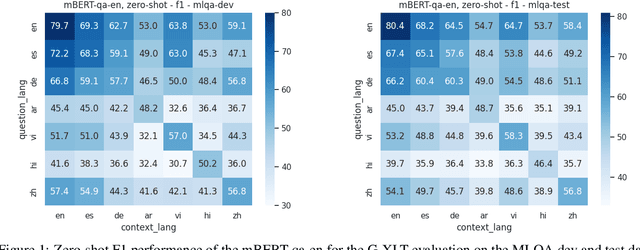
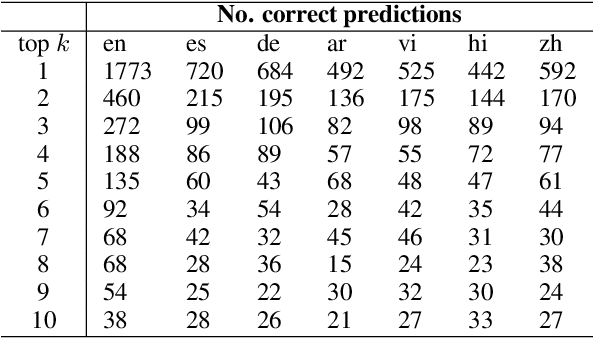
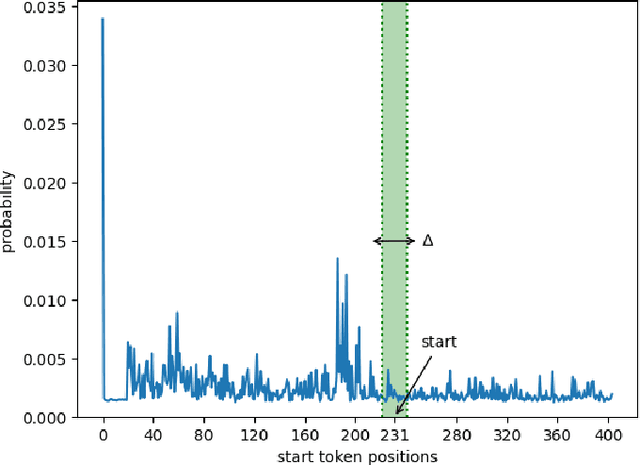

Despite substantial progress in multilingual extractive Question Answering (QA), models with high and uniformly distributed performance across languages remain challenging, especially for languages with limited resources. We study cross-lingual transfer mainly focusing on the Generalized Cross-Lingual Transfer (G-XLT) task, where the question language differs from the context language - a challenge that has received limited attention thus far. Our approach seeks to enhance cross-lingual QA transfer using a high-performing multilingual model trained on a large-scale dataset, complemented by a few thousand aligned QA examples across languages. Our proposed strategy combines cross-lingual sampling and advanced self-distillation training in generations to tackle the previous challenge. Notably, we introduce the novel mAP@k coefficients to fine-tune self-knowledge distillation loss, dynamically regulating the teacher's model knowledge to perform a balanced and effective knowledge transfer. We extensively evaluate our approach to assess XLT and G-XLT capabilities in extractive QA. Results reveal that our self-knowledge distillation approach outperforms standard cross-entropy fine-tuning by a significant margin. Importantly, when compared to a strong baseline that leverages a sizeable volume of machine-translated data, our approach shows competitive results despite the considerable challenge of operating within resource-constrained settings, even in zero-shot scenarios. Beyond performance improvements, we offer valuable insights through comprehensive analyses and an ablation study, further substantiating the benefits and constraints of our approach. In essence, we propose a practical solution to improve cross-lingual QA transfer by leveraging a few data resources in an efficient way.
Biomedical and Clinical Language Models for Spanish: On the Benefits of Domain-Specific Pretraining in a Mid-Resource Scenario
Sep 17, 2021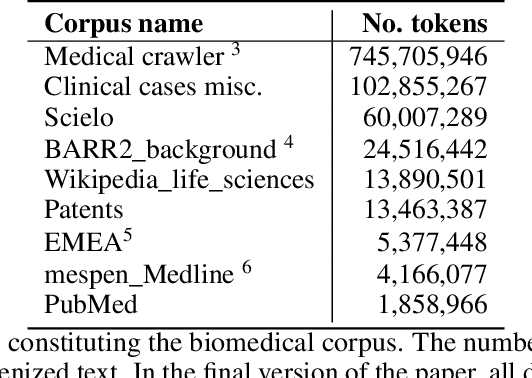
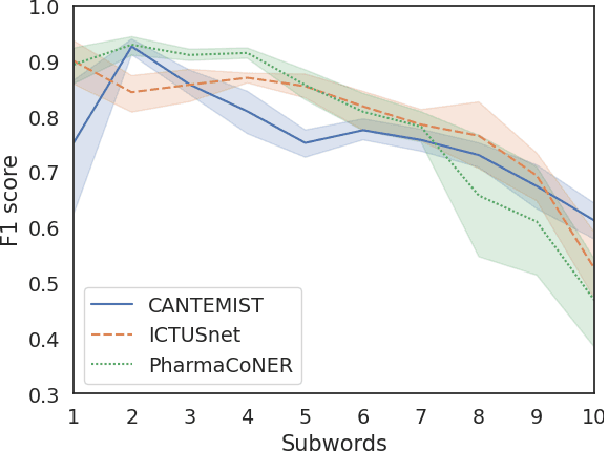
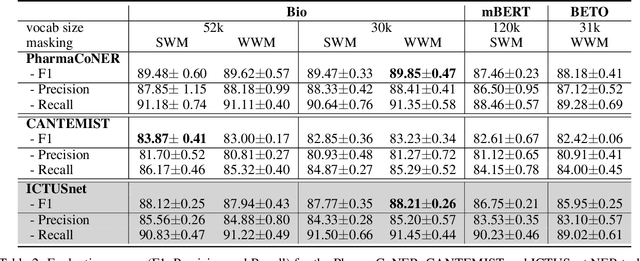
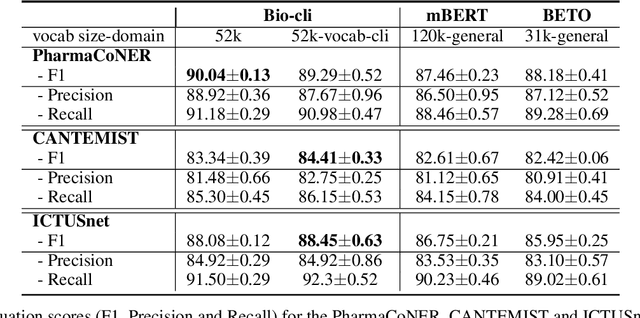
This work presents biomedical and clinical language models for Spanish by experimenting with different pretraining choices, such as masking at word and subword level, varying the vocabulary size and testing with domain data, looking for better language representations. Interestingly, in the absence of enough clinical data to train a model from scratch, we applied mixed-domain pretraining and cross-domain transfer approaches to generate a performant bio-clinical model suitable for real-world clinical data. We evaluated our models on Named Entity Recognition (NER) tasks for biomedical documents and challenging hospital discharge reports. When compared against the competitive mBERT and BETO models, we outperform them in all NER tasks by a significant margin. Finally, we studied the impact of the model's vocabulary on the NER performances by offering an interesting vocabulary-centric analysis. The results confirm that domain-specific pretraining is fundamental to achieving higher performances in downstream NER tasks, even within a mid-resource scenario. To the best of our knowledge, we provide the first biomedical and clinical transformer-based pretrained language models for Spanish, intending to boost native Spanish NLP applications in biomedicine. Our best models are freely available in the HuggingFace hub: https://huggingface.co/BSC-TeMU.
Spanish Biomedical Crawled Corpus: A Large, Diverse Dataset for Spanish Biomedical Language Models
Sep 16, 2021
We introduce CoWeSe (the Corpus Web Salud Espa\~nol), the largest Spanish biomedical corpus to date, consisting of 4.5GB (about 750M tokens) of clean plain text. CoWeSe is the result of a massive crawler on 3000 Spanish domains executed in 2020. The corpus is openly available and already preprocessed. CoWeSe is an important resource for biomedical and health NLP in Spanish and has already been employed to train domain-specific language models and to produce word embbedings. We released the CoWeSe corpus under a Creative Commons Attribution 4.0 International license, both in Zenodo (\url{https://zenodo.org/record/4561971\#.YTI5SnVKiEA}).
Spanish Language Models
Aug 13, 2021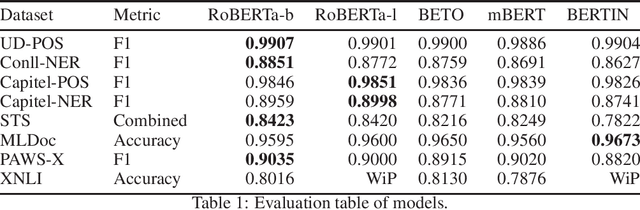
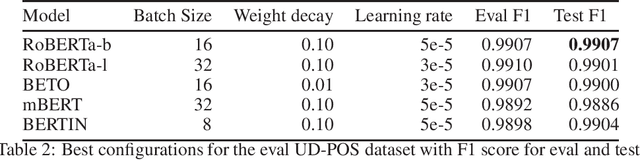
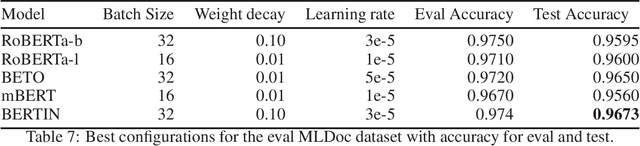
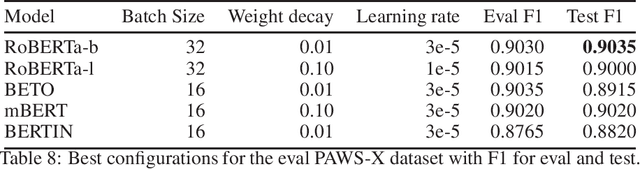
This paper presents the Spanish RoBERTa-base and RoBERTa-large models, as well as the corresponding performance evaluations. Both models were pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the National Library of Spain from 2009 to 2019. We extended the current evaluation datasets with an extractive Question Answering dataset and our models outperform the existing Spanish models across tasks and settings.
Are Multilingual Models the Best Choice for Moderately Under-resourced Languages? A Comprehensive Assessment for Catalan
Jul 16, 2021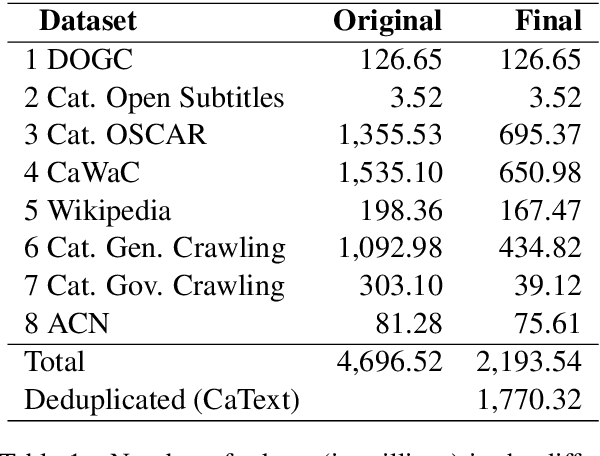
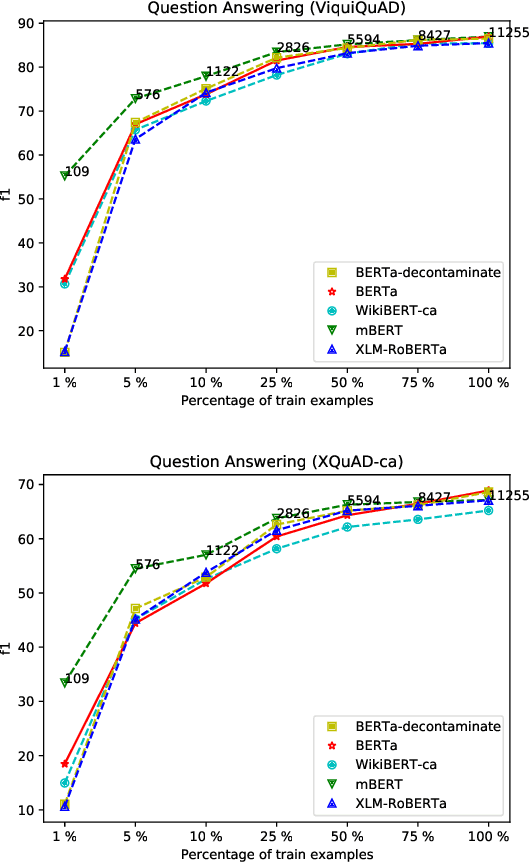

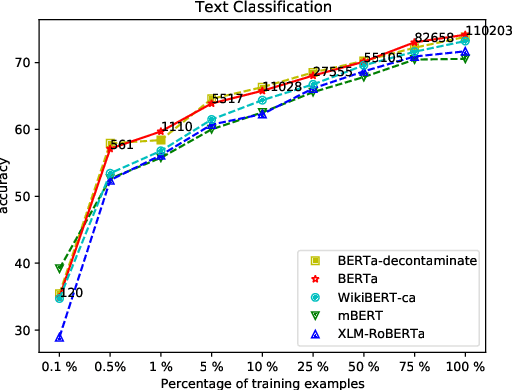
Multilingual language models have been a crucial breakthrough as they considerably reduce the need of data for under-resourced languages. Nevertheless, the superiority of language-specific models has already been proven for languages having access to large amounts of data. In this work, we focus on Catalan with the aim to explore to what extent a medium-sized monolingual language model is competitive with state-of-the-art large multilingual models. For this, we: (1) build a clean, high-quality textual Catalan corpus (CaText), the largest to date (but only a fraction of the usual size of the previous work in monolingual language models), (2) train a Transformer-based language model for Catalan (BERTa), and (3) devise a thorough evaluation in a diversity of settings, comprising a complete array of downstream tasks, namely, Part of Speech Tagging, Named Entity Recognition and Classification, Text Classification, Question Answering, and Semantic Textual Similarity, with most of the corresponding datasets being created ex novo. The result is a new benchmark, the Catalan Language Understanding Benchmark (CLUB), which we publish as an open resource, together with the clean textual corpus, the language model, and the cleaning pipeline. Using state-of-the-art multilingual models and a monolingual model trained only on Wikipedia as baselines, we consistently observe the superiority of our model across tasks and settings.
Spanish Biomedical and Clinical Language Embeddings
Feb 25, 2021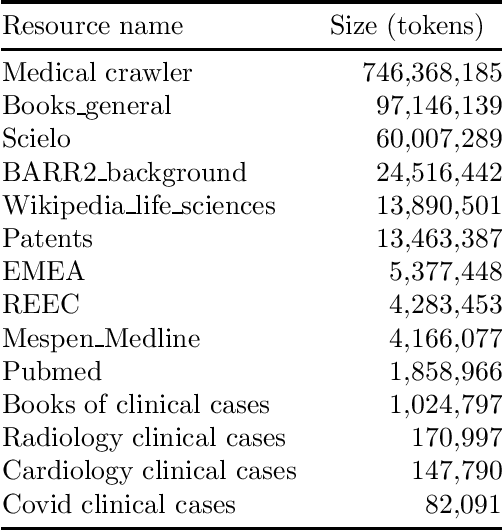
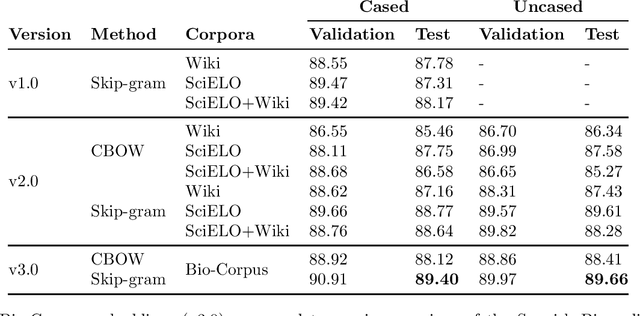
We computed both Word and Sub-word Embeddings using FastText. For Sub-word embeddings we selected Byte Pair Encoding (BPE) algorithm to represent the sub-words. We evaluated the Biomedical Word Embeddings obtaining better results than previous versions showing the implication that with more data, we obtain better representations.
Automatic Spanish Translation of the SQuAD Dataset for Multilingual Question Answering
Dec 12, 2019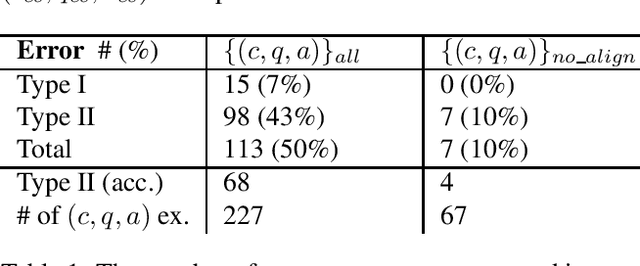



Recently, multilingual question answering became a crucial research topic, and it is receiving increased interest in the NLP community. However, the unavailability of large-scale datasets makes it challenging to train multilingual QA systems with performance comparable to the English ones. In this work, we develop the Translate Align Retrieve (TAR) method to automatically translate the Stanford Question Answering Dataset (SQuAD) v1.1 to Spanish. We then used this dataset to train Spanish QA systems by fine-tuning a Multilingual-BERT model. Finally, we evaluated our QA models with the recently proposed MLQA and XQuAD benchmarks for cross-lingual Extractive QA. Experimental results show that our models outperform the previous Multilingual-BERT baselines achieving the new state-of-the-art value of 68.1 F1 points on the Spanish MLQA corpus and 77.6 F1 and 61.8 Exact Match points on the Spanish XQuAD corpus. The resulting, synthetically generated SQuAD-es v1.1 corpora, with almost 100% of data contained in the original English version, to the best of our knowledge, is the first large-scale QA training resource for Spanish.