 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeesCorpius: A Massive Spanish Crawling Corpus
Jul 01, 2022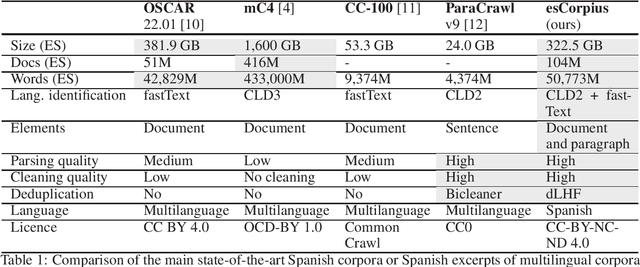
In the recent years, transformer-based models have lead to significant advances in language modelling for natural language processing. However, they require a vast amount of data to be (pre-)trained and there is a lack of corpora in languages other than English. Recently, several initiatives have presented multilingual datasets obtained from automatic web crawling. However, the results in Spanish present important shortcomings, as they are either too small in comparison with other languages, or present a low quality derived from sub-optimal cleaning and deduplication. In this paper, we introduce esCorpius, a Spanish crawling corpus obtained from near 1 Pb of Common Crawl data. It is the most extensive corpus in Spanish with this level of quality in the extraction, purification and deduplication of web textual content. Our data curation process involves a novel highly parallel cleaning pipeline and encompasses a series of deduplication mechanisms that together ensure the integrity of both document and paragraph boundaries. Additionally, we maintain both the source web page URL and the WARC shard origin URL in order to complain with EU regulations. esCorpius has been released under CC BY-NC-ND 4.0 license and is available on HuggingFace.
The Large Labelled Logo Dataset (L3D): A Multipurpose and Hand-Labelled Continuously Growing Dataset
Dec 10, 2021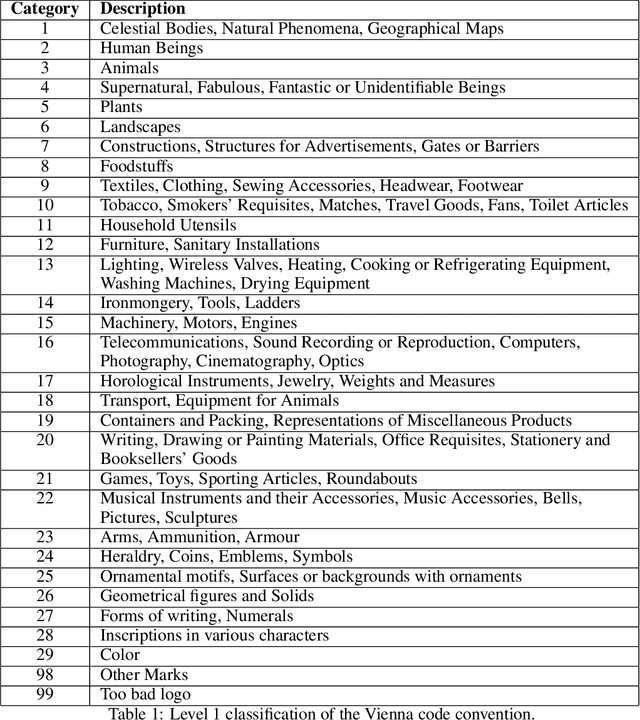
In this work, we present the Large Labelled Logo Dataset (L3D), a multipurpose, hand-labelled, continuously growing dataset. It is composed of around 770k of color 256x256 RGB images extracted from the European Union Intellectual Property Office (EUIPO) open registry. Each of them is associated to multiple labels that classify the figurative and textual elements that appear in the images. These annotations have been classified by the EUIPO evaluators using the Vienna classification, a hierarchical classification of figurative marks. We suggest two direct applications of this dataset, namely, logo classification and logo generation.
FinEAS: Financial Embedding Analysis of Sentiment
Nov 19, 2021
We introduce a new language representation model in finance called Financial Embedding Analysis of Sentiment (FinEAS). In financial markets, news and investor sentiment are significant drivers of security prices. Thus, leveraging the capabilities of modern NLP approaches for financial sentiment analysis is a crucial component in identifying patterns and trends that are useful for market participants and regulators. In recent years, methods that use transfer learning from large Transformer-based language models like BERT, have achieved state-of-the-art results in text classification tasks, including sentiment analysis using labelled datasets. Researchers have quickly adopted these approaches to financial texts, but best practices in this domain are not well-established. In this work, we propose a new model for financial sentiment analysis based on supervised fine-tuned sentence embeddings from a standard BERT model. We demonstrate our approach achieves significant improvements in comparison to vanilla BERT, LSTM, and FinBERT, a financial domain specific BERT.
Spanish Legalese Language Model and Corpora
Oct 23, 2021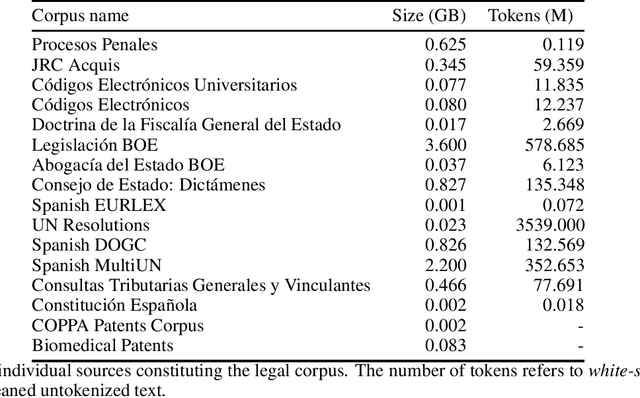
There are many Language Models for the English language according to its worldwide relevance. However, for the Spanish language, even if it is a widely spoken language, there are very few Spanish Language Models which result to be small and too general. Legal slang could be think of a Spanish variant on its own as it is very complicated in vocabulary, semantics and phrase understanding. For this work we gathered legal-domain corpora from different sources, generated a model and evaluated against Spanish general domain tasks. The model provides reasonable results in those tasks.
Biomedical and Clinical Language Models for Spanish: On the Benefits of Domain-Specific Pretraining in a Mid-Resource Scenario
Sep 17, 2021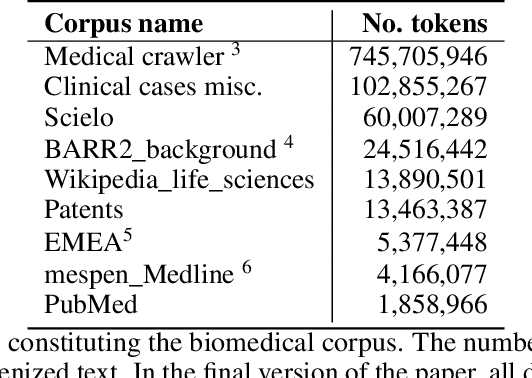
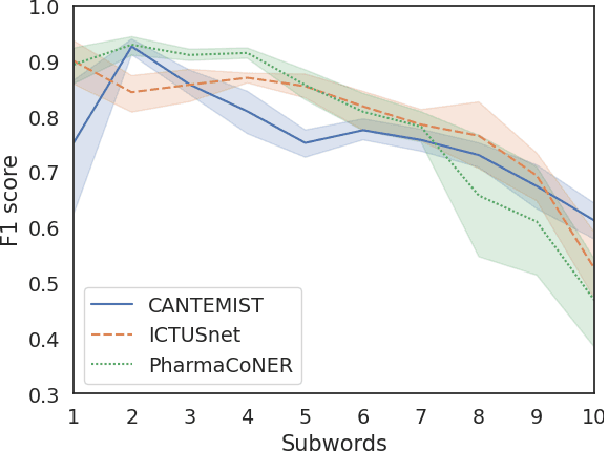
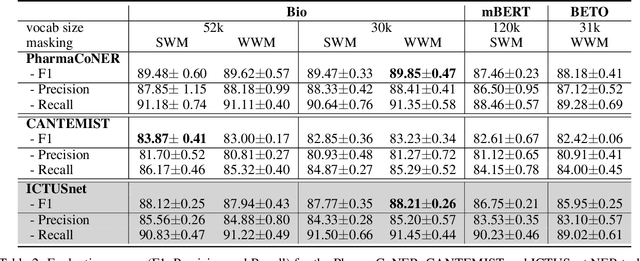
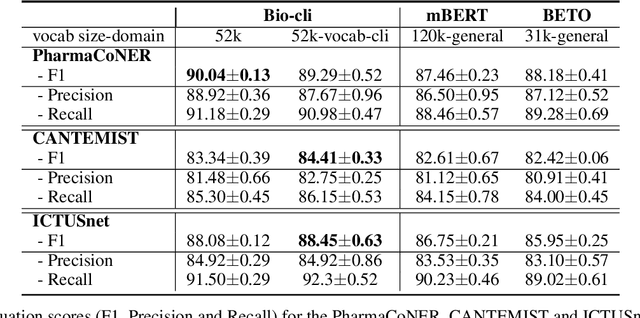
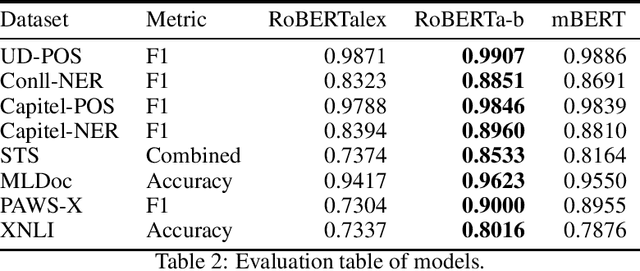
This work presents biomedical and clinical language models for Spanish by experimenting with different pretraining choices, such as masking at word and subword level, varying the vocabulary size and testing with domain data, looking for better language representations. Interestingly, in the absence of enough clinical data to train a model from scratch, we applied mixed-domain pretraining and cross-domain transfer approaches to generate a performant bio-clinical model suitable for real-world clinical data. We evaluated our models on Named Entity Recognition (NER) tasks for biomedical documents and challenging hospital discharge reports. When compared against the competitive mBERT and BETO models, we outperform them in all NER tasks by a significant margin. Finally, we studied the impact of the model's vocabulary on the NER performances by offering an interesting vocabulary-centric analysis. The results confirm that domain-specific pretraining is fundamental to achieving higher performances in downstream NER tasks, even within a mid-resource scenario. To the best of our knowledge, we provide the first biomedical and clinical transformer-based pretrained language models for Spanish, intending to boost native Spanish NLP applications in biomedicine. Our best models are freely available in the HuggingFace hub: https://huggingface.co/BSC-TeMU.
Spanish Biomedical Crawled Corpus: A Large, Diverse Dataset for Spanish Biomedical Language Models
Sep 16, 2021
We introduce CoWeSe (the Corpus Web Salud Espa\~nol), the largest Spanish biomedical corpus to date, consisting of 4.5GB (about 750M tokens) of clean plain text. CoWeSe is the result of a massive crawler on 3000 Spanish domains executed in 2020. The corpus is openly available and already preprocessed. CoWeSe is an important resource for biomedical and health NLP in Spanish and has already been employed to train domain-specific language models and to produce word embbedings. We released the CoWeSe corpus under a Creative Commons Attribution 4.0 International license, both in Zenodo (\url{https://zenodo.org/record/4561971\#.YTI5SnVKiEA}).
Spanish Language Models
Aug 13, 2021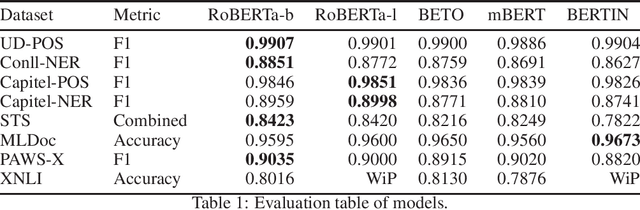
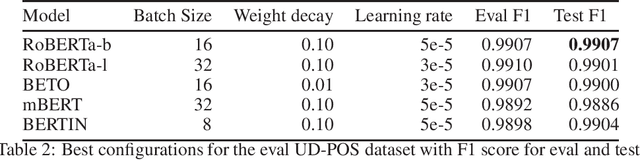
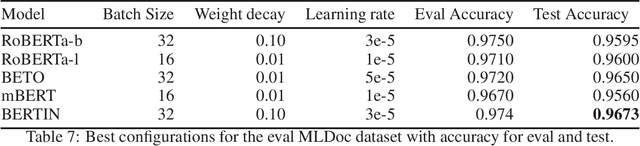
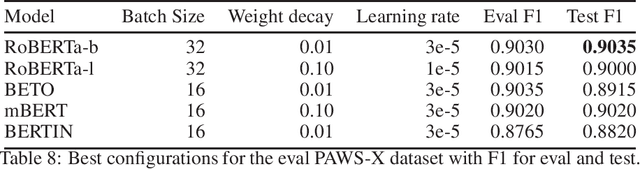
This paper presents the Spanish RoBERTa-base and RoBERTa-large models, as well as the corresponding performance evaluations. Both models were pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the National Library of Spain from 2009 to 2019. We extended the current evaluation datasets with an extractive Question Answering dataset and our models outperform the existing Spanish models across tasks and settings.
Persistent Homology Captures the Generalization of Neural Networks Without A Validation Set
May 31, 2021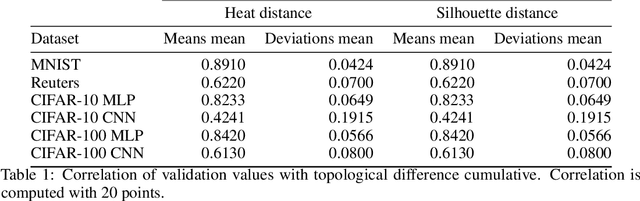

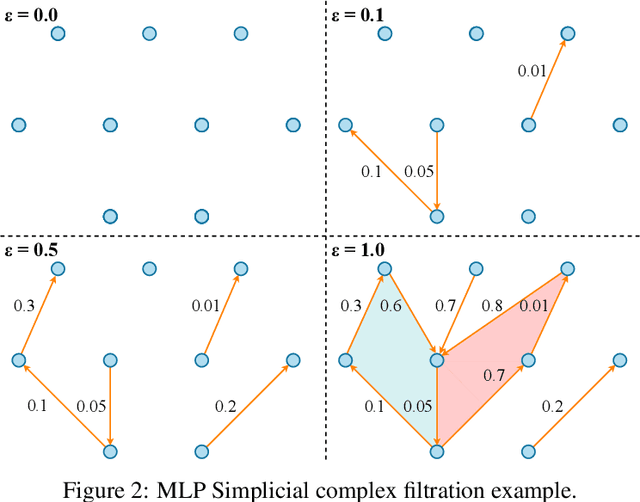
The training of neural networks is usually monitored with a validation (holdout) set to estimate the generalization of the model. This is done instead of measuring intrinsic properties of the model to determine whether it is learning appropriately. In this work, we suggest studying the training of neural networks with Algebraic Topology, specifically Persistent Homology (PH). Using simplicial complex representations of neural networks, we study the PH diagram distance evolution on the neural network learning process with different architectures and several datasets. Results show that the PH diagram distance between consecutive neural network states correlates with the validation accuracy, implying that the generalization error of a neural network could be intrinsically estimated without any holdout set.
Spanish Biomedical and Clinical Language Embeddings
Feb 25, 2021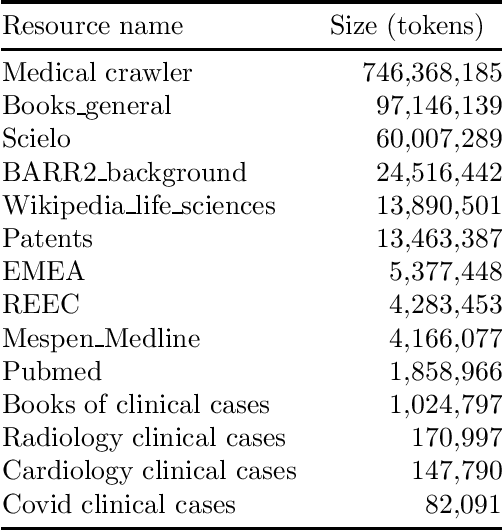
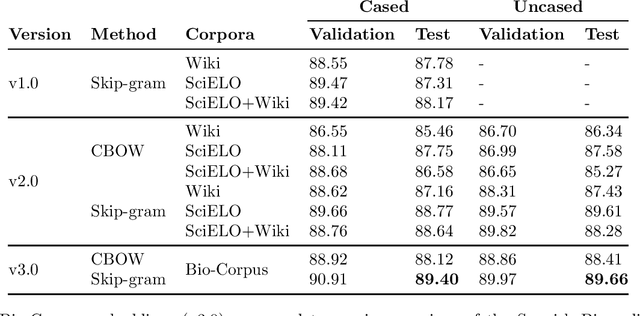
We computed both Word and Sub-word Embeddings using FastText. For Sub-word embeddings we selected Byte Pair Encoding (BPE) algorithm to represent the sub-words. We evaluated the Biomedical Word Embeddings obtaining better results than previous versions showing the implication that with more data, we obtain better representations.
Determining Structural Properties of Artificial Neural Networks Using Algebraic Topology
Jan 21, 2021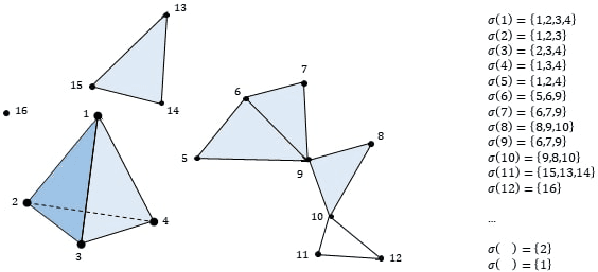
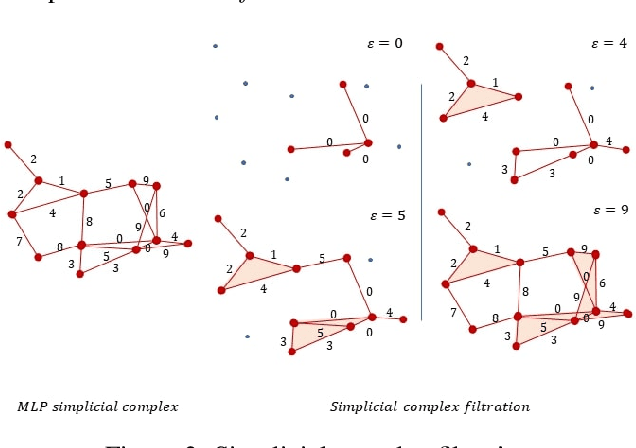
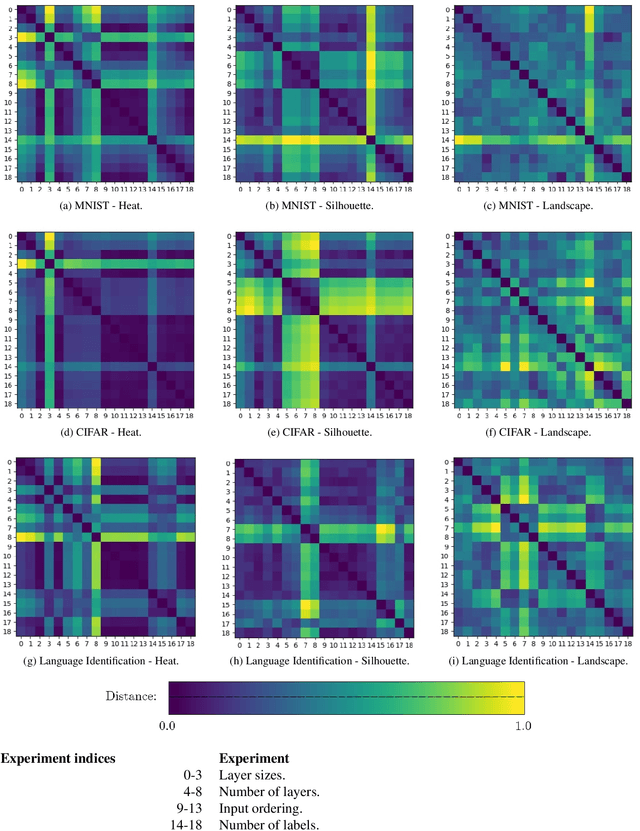
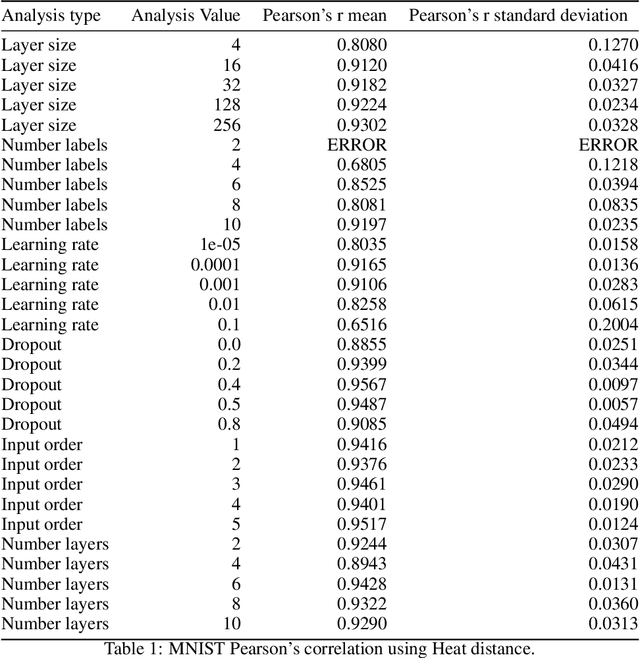
Artificial Neural Networks (ANNs) are widely used for approximating complex functions. The process that is usually followed to define the most appropriate architecture for an ANN given a specific function is mostly empirical. Once this architecture has been defined, weights are usually optimized according to the error function. On the other hand, we observe that ANNs can be represented as graphs and their topological 'fingerprints' can be obtained using Persistent Homology (PH). In this paper, we describe a proposal focused on designing more principled architecture search procedures. To do this, different architectures for solving problems related to a heterogeneous set of datasets have been analyzed. The results of the evaluation corroborate that PH effectively characterizes the ANN invariants: when ANN density (layers and neurons) or sample feeding order is the only difference, PH topological invariants appear; in the opposite direction in different sub-problems (i.e. different labels), PH varies. This approach based on topological analysis helps towards the goal of designing more principled architecture search procedures and having a better understanding of ANNs.