 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeesCorpius: A Massive Spanish Crawling Corpus
Jul 01, 2022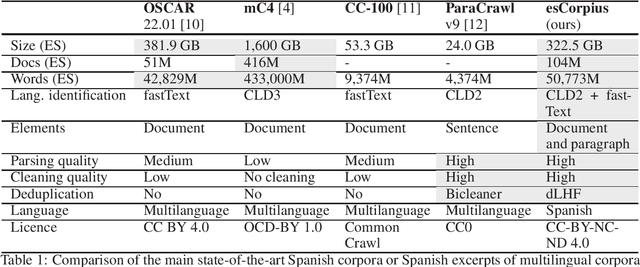
In the recent years, transformer-based models have lead to significant advances in language modelling for natural language processing. However, they require a vast amount of data to be (pre-)trained and there is a lack of corpora in languages other than English. Recently, several initiatives have presented multilingual datasets obtained from automatic web crawling. However, the results in Spanish present important shortcomings, as they are either too small in comparison with other languages, or present a low quality derived from sub-optimal cleaning and deduplication. In this paper, we introduce esCorpius, a Spanish crawling corpus obtained from near 1 Pb of Common Crawl data. It is the most extensive corpus in Spanish with this level of quality in the extraction, purification and deduplication of web textual content. Our data curation process involves a novel highly parallel cleaning pipeline and encompasses a series of deduplication mechanisms that together ensure the integrity of both document and paragraph boundaries. Additionally, we maintain both the source web page URL and the WARC shard origin URL in order to complain with EU regulations. esCorpius has been released under CC BY-NC-ND 4.0 license and is available on HuggingFace.
The Large Labelled Logo Dataset (L3D): A Multipurpose and Hand-Labelled Continuously Growing Dataset
Dec 10, 2021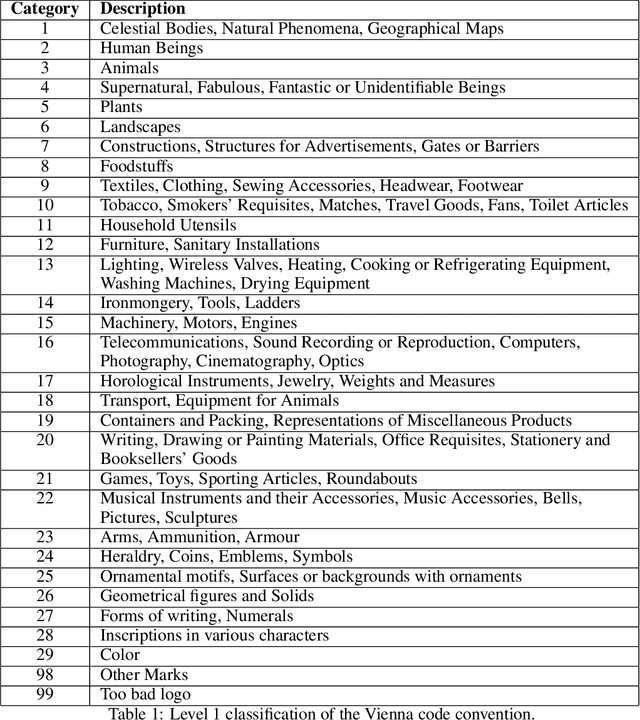
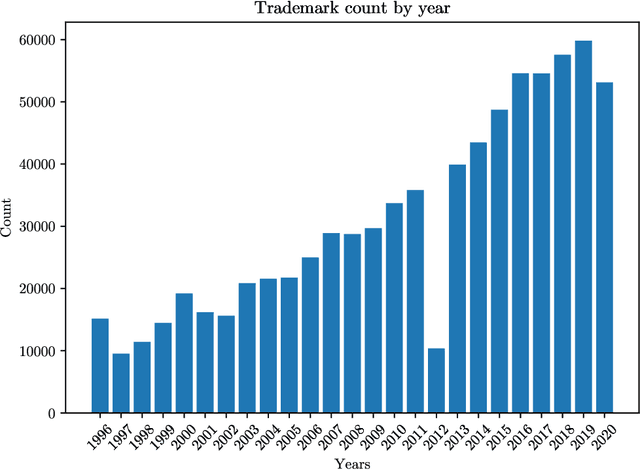
In this work, we present the Large Labelled Logo Dataset (L3D), a multipurpose, hand-labelled, continuously growing dataset. It is composed of around 770k of color 256x256 RGB images extracted from the European Union Intellectual Property Office (EUIPO) open registry. Each of them is associated to multiple labels that classify the figurative and textual elements that appear in the images. These annotations have been classified by the EUIPO evaluators using the Vienna classification, a hierarchical classification of figurative marks. We suggest two direct applications of this dataset, namely, logo classification and logo generation.
Persistent Homology Captures the Generalization of Neural Networks Without A Validation Set
May 31, 2021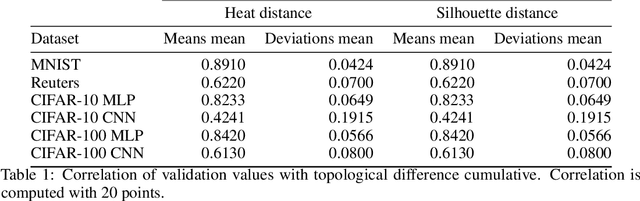
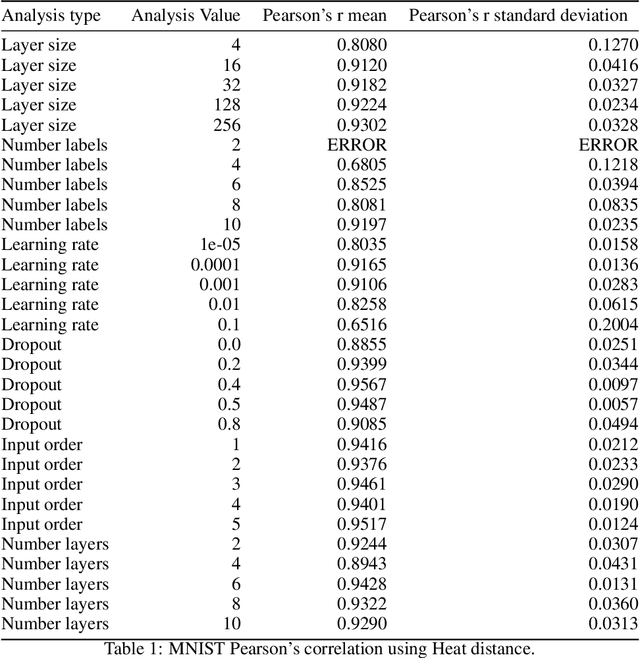

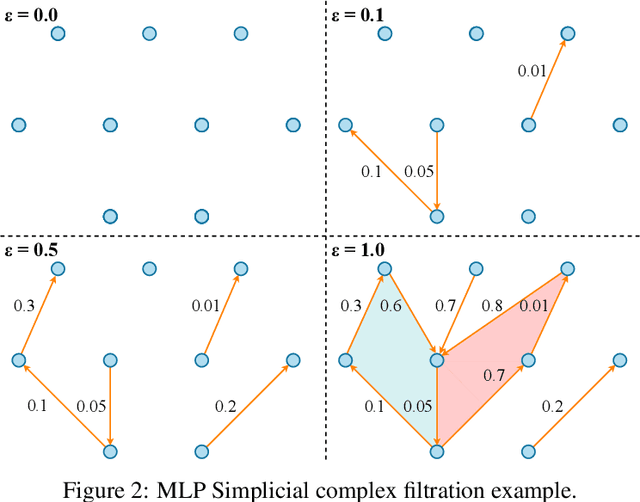
The training of neural networks is usually monitored with a validation (holdout) set to estimate the generalization of the model. This is done instead of measuring intrinsic properties of the model to determine whether it is learning appropriately. In this work, we suggest studying the training of neural networks with Algebraic Topology, specifically Persistent Homology (PH). Using simplicial complex representations of neural networks, we study the PH diagram distance evolution on the neural network learning process with different architectures and several datasets. Results show that the PH diagram distance between consecutive neural network states correlates with the validation accuracy, implying that the generalization error of a neural network could be intrinsically estimated without any holdout set.