 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Catalan Language CLUB
Dec 03, 2021


The Catalan Language Understanding Benchmark (CLUB) encompasses various datasets representative of different NLU tasks that enable accurate evaluations of language models, following the General Language Understanding Evaluation (GLUE) example. It is part of AINA and PlanTL, two public funding initiatives to empower the Catalan language in the Artificial Intelligence era.
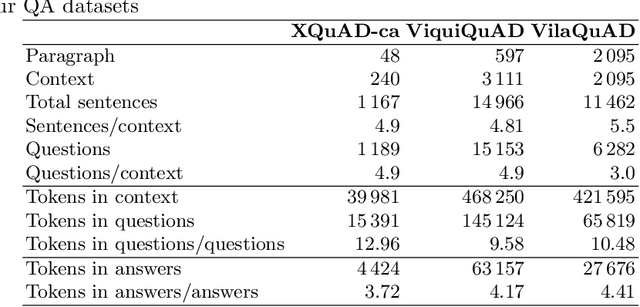
Spanish Language Models
Aug 13, 2021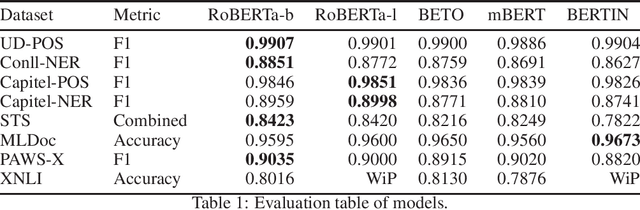
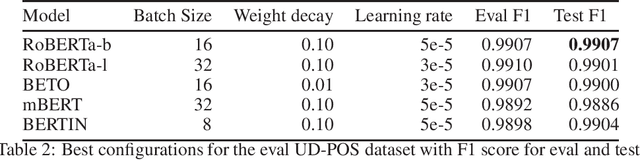
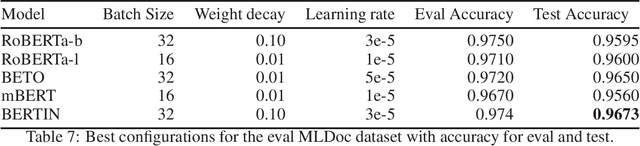
This paper presents the Spanish RoBERTa-base and RoBERTa-large models, as well as the corresponding performance evaluations. Both models were pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the National Library of Spain from 2009 to 2019. We extended the current evaluation datasets with an extractive Question Answering dataset and our models outperform the existing Spanish models across tasks and settings.
Are Multilingual Models the Best Choice for Moderately Under-resourced Languages? A Comprehensive Assessment for Catalan
Jul 16, 2021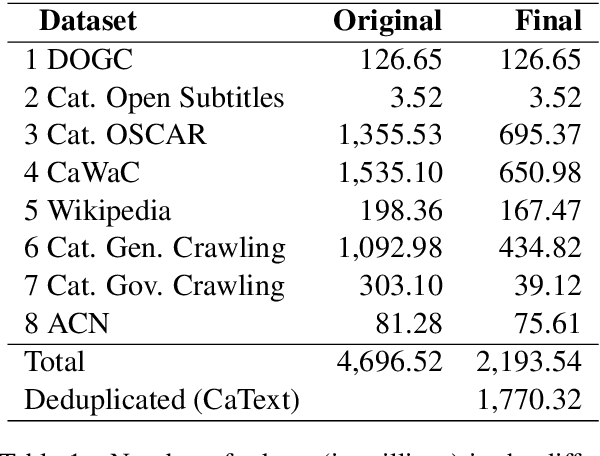
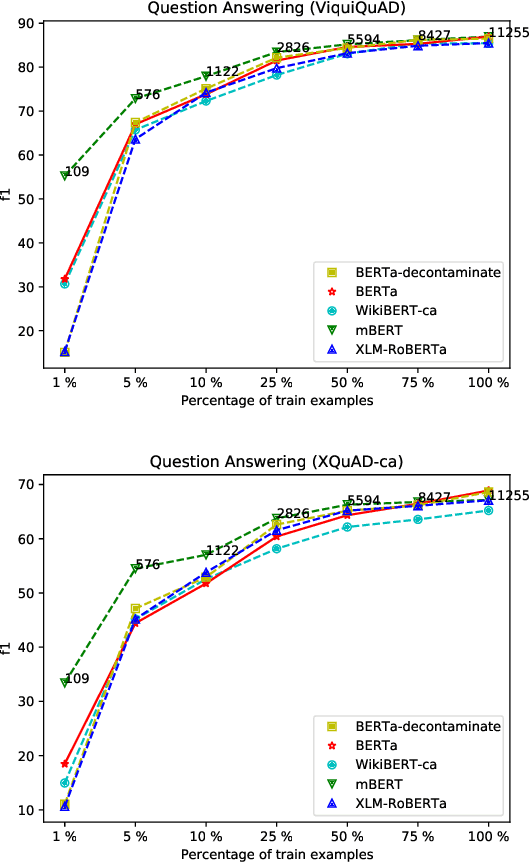

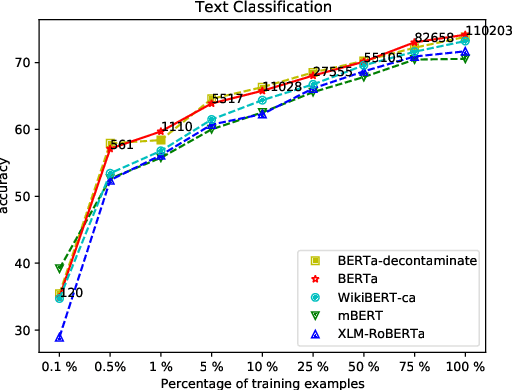
Multilingual language models have been a crucial breakthrough as they considerably reduce the need of data for under-resourced languages. Nevertheless, the superiority of language-specific models has already been proven for languages having access to large amounts of data. In this work, we focus on Catalan with the aim to explore to what extent a medium-sized monolingual language model is competitive with state-of-the-art large multilingual models. For this, we: (1) build a clean, high-quality textual Catalan corpus (CaText), the largest to date (but only a fraction of the usual size of the previous work in monolingual language models), (2) train a Transformer-based language model for Catalan (BERTa), and (3) devise a thorough evaluation in a diversity of settings, comprising a complete array of downstream tasks, namely, Part of Speech Tagging, Named Entity Recognition and Classification, Text Classification, Question Answering, and Semantic Textual Similarity, with most of the corresponding datasets being created ex novo. The result is a new benchmark, the Catalan Language Understanding Benchmark (CLUB), which we publish as an open resource, together with the clean textual corpus, the language model, and the cleaning pipeline. Using state-of-the-art multilingual models and a monolingual model trained only on Wikipedia as baselines, we consistently observe the superiority of our model across tasks and settings.
Overview of BioASQ 2020: The eighth BioASQ challenge on Large-Scale Biomedical Semantic Indexing and Question Answering
Jun 28, 2021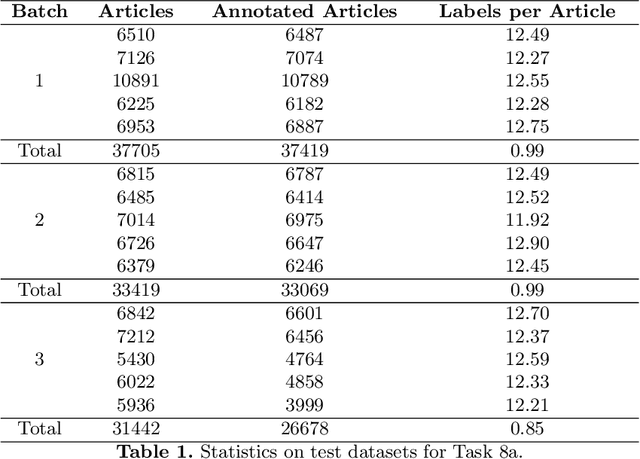

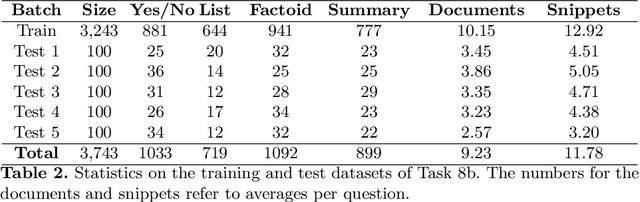
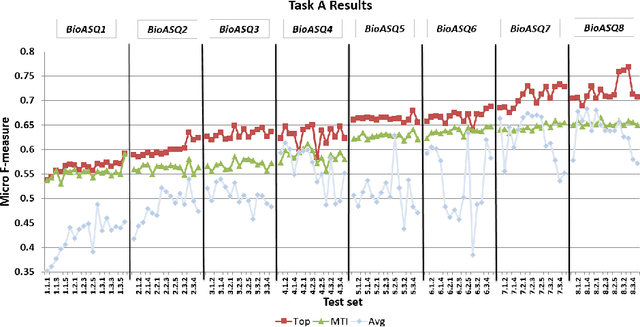
In this paper, we present an overview of the eighth edition of the BioASQ challenge, which ran as a lab in the Conference and Labs of the Evaluation Forum (CLEF) 2020. BioASQ is a series of challenges aiming at the promotion of systems and methodologies for large-scale biomedical semantic indexing and question answering. To this end, shared tasks are organized yearly since 2012, where different teams develop systems that compete on the same demanding benchmark datasets that represent the real information needs of experts in the biomedical domain. This year, the challenge has been extended with the introduction of a new task on medical semantic indexing in Spanish. In total, 34 teams with more than 100 systems participated in the three tasks of the challenge. As in previous years, the results of the evaluation reveal that the top-performing systems managed to outperform the strong baselines, which suggests that state-of-the-art systems keep pushing the frontier of research through continuous improvements.
* 21 pages, 10 tables, 3 figures