 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Catalan Language CLUB
Dec 03, 2021


The Catalan Language Understanding Benchmark (CLUB) encompasses various datasets representative of different NLU tasks that enable accurate evaluations of language models, following the General Language Understanding Evaluation (GLUE) example. It is part of AINA and PlanTL, two public funding initiatives to empower the Catalan language in the Artificial Intelligence era.
Spanish Biomedical Crawled Corpus: A Large, Diverse Dataset for Spanish Biomedical Language Models
Sep 16, 2021
We introduce CoWeSe (the Corpus Web Salud Espa\~nol), the largest Spanish biomedical corpus to date, consisting of 4.5GB (about 750M tokens) of clean plain text. CoWeSe is the result of a massive crawler on 3000 Spanish domains executed in 2020. The corpus is openly available and already preprocessed. CoWeSe is an important resource for biomedical and health NLP in Spanish and has already been employed to train domain-specific language models and to produce word embbedings. We released the CoWeSe corpus under a Creative Commons Attribution 4.0 International license, both in Zenodo (\url{https://zenodo.org/record/4561971\#.YTI5SnVKiEA}).
On the Multilingual Capabilities of Very Large-Scale English Language Models
Aug 30, 2021
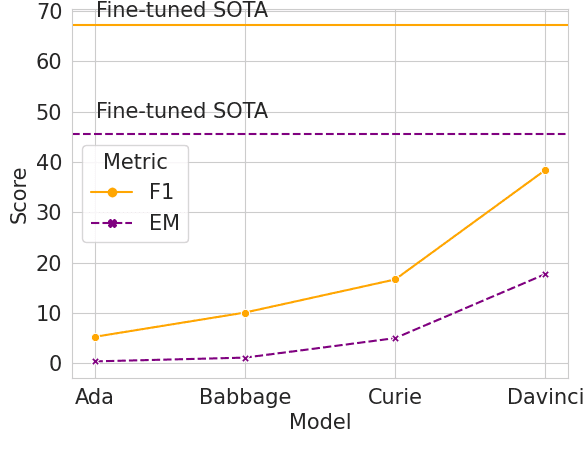

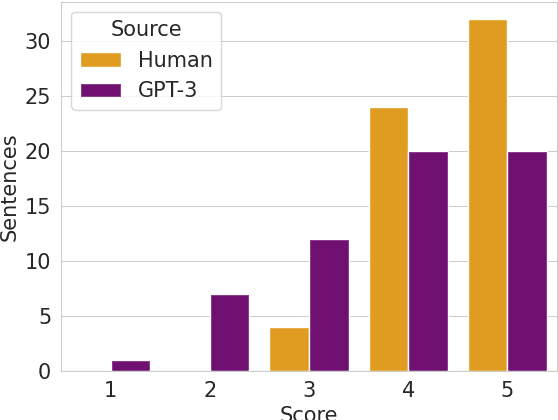
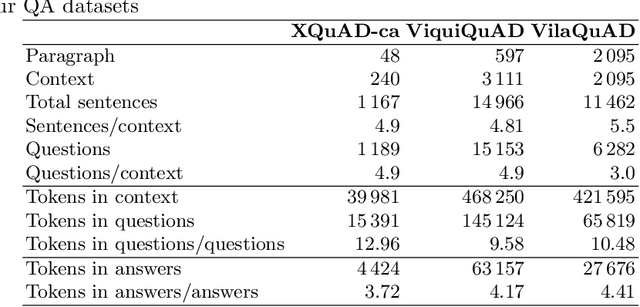
Generative Pre-trained Transformers (GPTs) have recently been scaled to unprecedented sizes in the history of machine learning. These models, solely trained on the language modeling objective, have been shown to exhibit outstanding few-shot learning capabilities in a number of different tasks. Nevertheless, aside from anecdotal experiences, little is known regarding their multilingual capabilities, given the fact that the pre-training corpus is almost entirely composed of English text. In this work, we investigate the multilingual skills of GPT-3, focusing on one language that barely appears in the pre-training corpus, Catalan, which makes the results especially meaningful; we assume that our results may be relevant for other languages as well. We find that the model shows an outstanding performance, particularly in generative tasks, with predictable limitations mostly in language understanding tasks but still with remarkable results given the zero-shot scenario. We investigate its potential and limits in extractive question-answering and natural language generation, as well as the effect of scale in terms of model size.
Are Multilingual Models the Best Choice for Moderately Under-resourced Languages? A Comprehensive Assessment for Catalan
Jul 16, 2021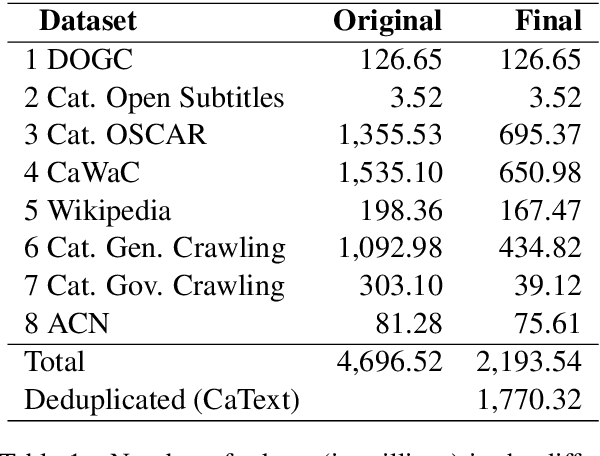
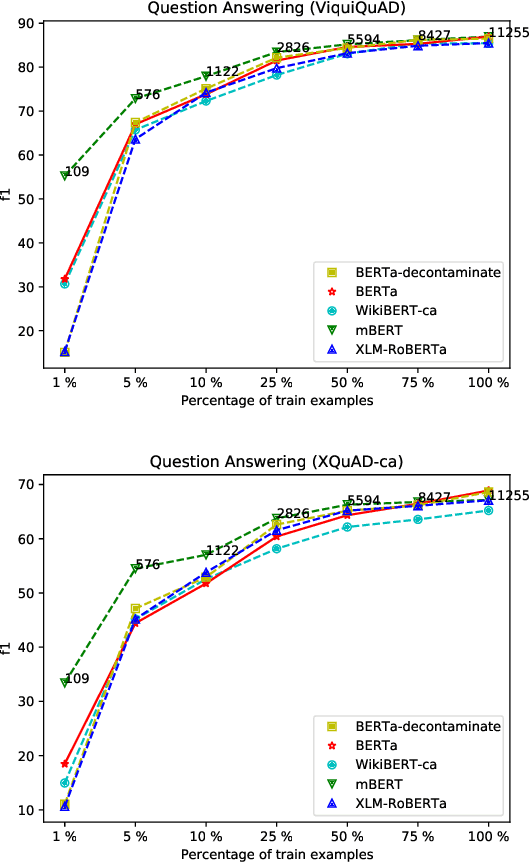

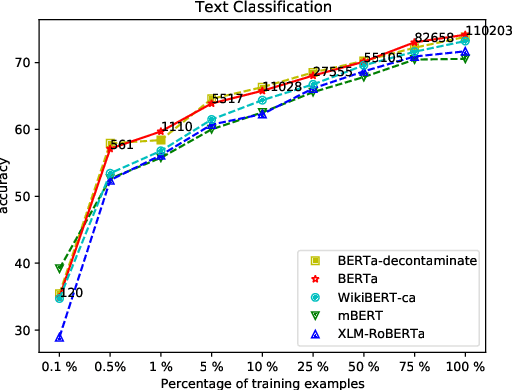
Multilingual language models have been a crucial breakthrough as they considerably reduce the need of data for under-resourced languages. Nevertheless, the superiority of language-specific models has already been proven for languages having access to large amounts of data. In this work, we focus on Catalan with the aim to explore to what extent a medium-sized monolingual language model is competitive with state-of-the-art large multilingual models. For this, we: (1) build a clean, high-quality textual Catalan corpus (CaText), the largest to date (but only a fraction of the usual size of the previous work in monolingual language models), (2) train a Transformer-based language model for Catalan (BERTa), and (3) devise a thorough evaluation in a diversity of settings, comprising a complete array of downstream tasks, namely, Part of Speech Tagging, Named Entity Recognition and Classification, Text Classification, Question Answering, and Semantic Textual Similarity, with most of the corresponding datasets being created ex novo. The result is a new benchmark, the Catalan Language Understanding Benchmark (CLUB), which we publish as an open resource, together with the clean textual corpus, the language model, and the cleaning pipeline. Using state-of-the-art multilingual models and a monolingual model trained only on Wikipedia as baselines, we consistently observe the superiority of our model across tasks and settings.