 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACADATA: Parallel Dataset of Academic Data for Machine Translation
Oct 14, 2025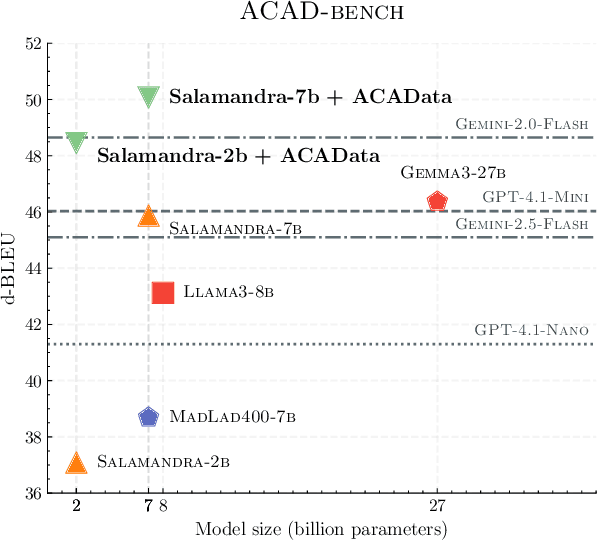
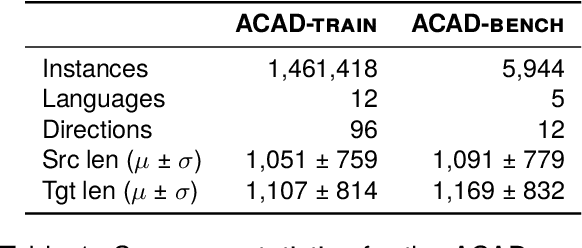
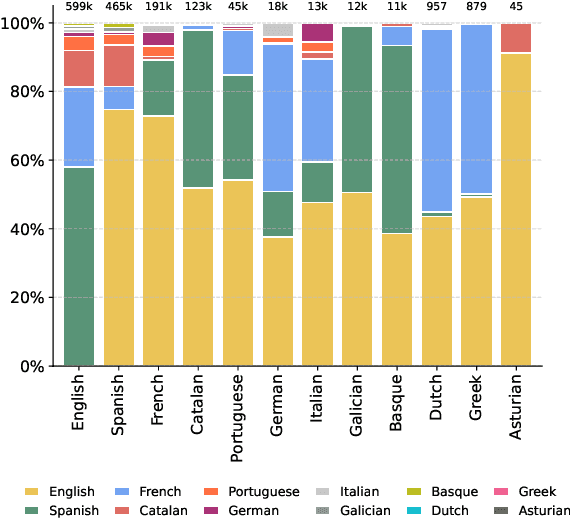
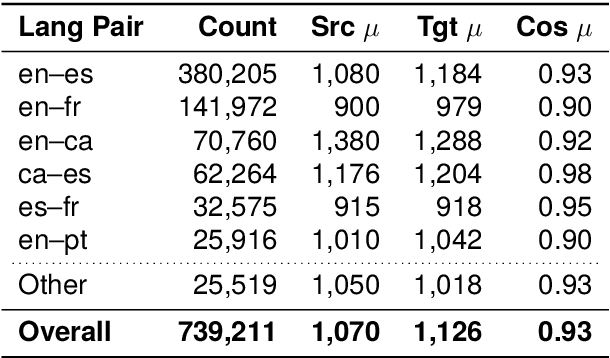
We present ACADATA, a high-quality parallel dataset for academic translation, that consists of two subsets: ACAD-TRAIN, which contains approximately 1.5 million author-generated paragraph pairs across 96 language directions and ACAD-BENCH, a curated evaluation set of almost 6,000 translations covering 12 directions. To validate its utility, we fine-tune two Large Language Models (LLMs) on ACAD-TRAIN and benchmark them on ACAD-BENCH against specialized machine-translation systems, general-purpose, open-weight LLMs, and several large-scale proprietary models. Experimental results demonstrate that fine-tuning on ACAD-TRAIN leads to improvements in academic translation quality by +6.1 and +12.4 d-BLEU points on average for 7B and 2B models respectively, while also improving long-context translation in a general domain by up to 24.9% when translating out of English. The fine-tuned top-performing model surpasses the best propietary and open-weight models on academic translation domain. By releasing ACAD-TRAIN, ACAD-BENCH and the fine-tuned models, we provide the community with a valuable resource to advance research in academic domain and long-context translation.
MT-LENS: An all-in-one Toolkit for Better Machine Translation Evaluation
Dec 16, 2024
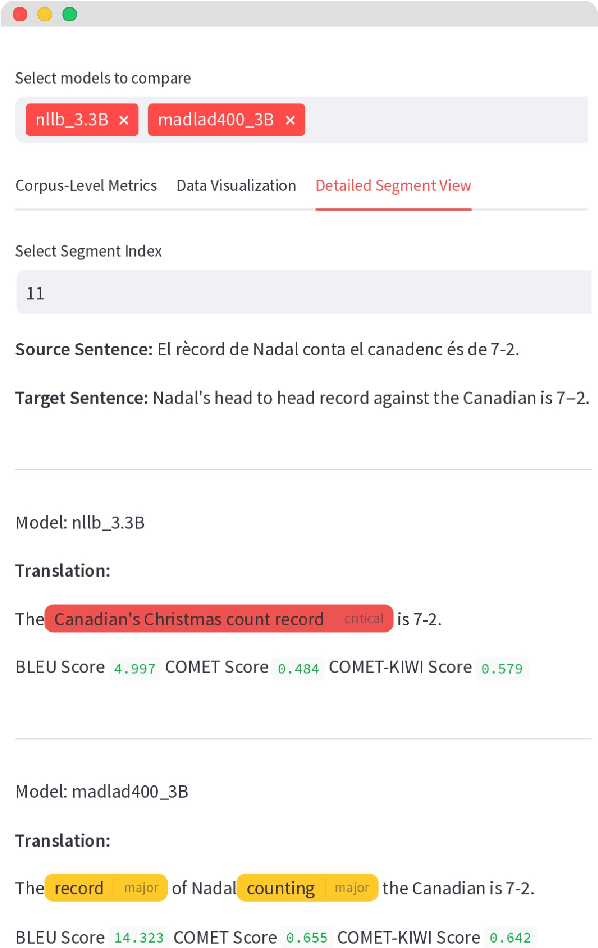
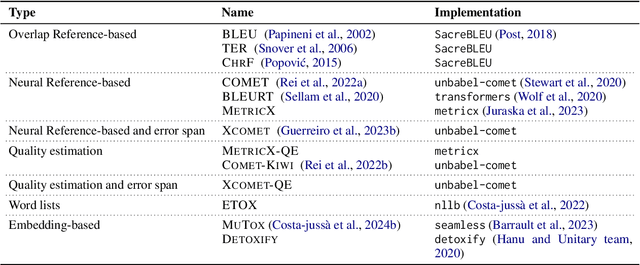
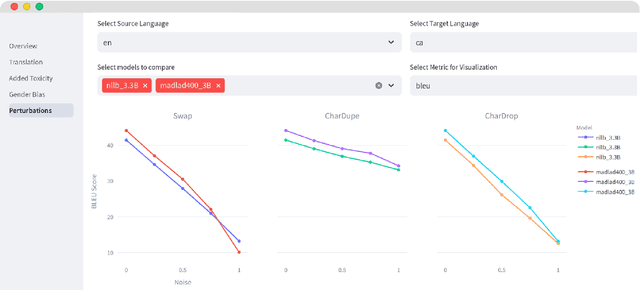
We introduce MT-LENS, a framework designed to evaluate Machine Translation (MT) systems across a variety of tasks, including translation quality, gender bias detection, added toxicity, and robustness to misspellings. While several toolkits have become very popular for benchmarking the capabilities of Large Language Models (LLMs), existing evaluation tools often lack the ability to thoroughly assess the diverse aspects of MT performance. MT-LENS addresses these limitations by extending the capabilities of LM-eval-harness for MT, supporting state-of-the-art datasets and a wide range of evaluation metrics. It also offers a user-friendly platform to compare systems and analyze translations with interactive visualizations. MT-LENS aims to broaden access to evaluation strategies that go beyond traditional translation quality evaluation, enabling researchers and engineers to better understand the performance of a NMT model and also easily measure system's biases.
The power of Prompts: Evaluating and Mitigating Gender Bias in MT with LLMs
Jul 26, 2024This paper studies gender bias in machine translation through the lens of Large Language Models (LLMs). Four widely-used test sets are employed to benchmark various base LLMs, comparing their translation quality and gender bias against state-of-the-art Neural Machine Translation (NMT) models for English to Catalan (En $\rightarrow$ Ca) and English to Spanish (En $\rightarrow$ Es) translation directions. Our findings reveal pervasive gender bias across all models, with base LLMs exhibiting a higher degree of bias compared to NMT models. To combat this bias, we explore prompting engineering techniques applied to an instruction-tuned LLM. We identify a prompt structure that significantly reduces gender bias by up to 12% on the WinoMT evaluation dataset compared to more straightforward prompts. These results significantly reduce the gender bias accuracy gap between LLMs and traditional NMT systems.
Investigating the translation capabilities of Large Language Models trained on parallel data only
Jun 13, 2024



In recent years, Large Language Models (LLMs) have demonstrated exceptional proficiency across a broad spectrum of Natural Language Processing (NLP) tasks, including Machine Translation. However, previous methods predominantly relied on iterative processes such as instruction fine-tuning or continual pre-training, leaving unexplored the challenges of training LLMs solely on parallel data. In this work, we introduce PLUME (Parallel Language Model), a collection of three 2B LLMs featuring varying vocabulary sizes (32k, 128k, and 256k) trained exclusively on Catalan-centric parallel examples. These models perform comparably to previous encoder-decoder architectures on 16 supervised translation directions and 56 zero-shot ones. Utilizing this set of models, we conduct a thorough investigation into the translation capabilities of LLMs, probing their performance, the impact of the different elements of the prompt, and their cross-lingual representation space.
A Hard Nut to Crack: Idiom Detection with Conversational Large Language Models
May 17, 2024In this work, we explore idiomatic language processing with Large Language Models (LLMs). We introduce the Idiomatic language Test Suite IdioTS, a new dataset of difficult examples specifically designed by language experts to assess the capabilities of LLMs to process figurative language at sentence level. We propose a comprehensive evaluation methodology based on an idiom detection task, where LLMs are prompted with detecting an idiomatic expression in a given English sentence. We present a thorough automatic and manual evaluation of the results and an extensive error analysis.
Sequence-to-Sequence Resources for Catalan
Feb 14, 2022
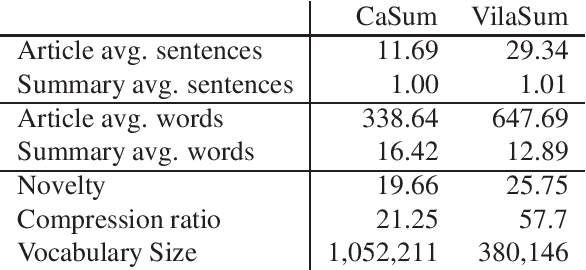
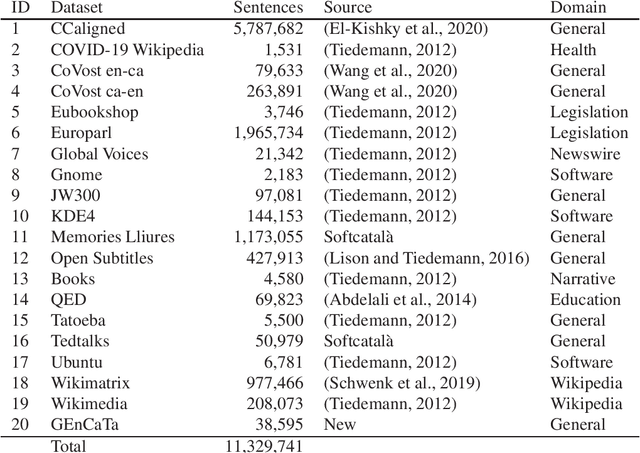

In this work, we introduce sequence-to-sequence language resources for Catalan, a moderately under-resourced language, towards two tasks, namely: Summarization and Machine Translation (MT). We present two new abstractive summarization datasets in the domain of newswire. We also introduce a parallel Catalan-English corpus, paired with three different brand new test sets. Finally, we evaluate the data presented with competing state of the art models, and we develop baselines for these tasks using a newly created Catalan BART. We release the resulting resources of this work under open license to encourage the development of language technology in Catalan.
The Catalan Language CLUB
Dec 03, 2021

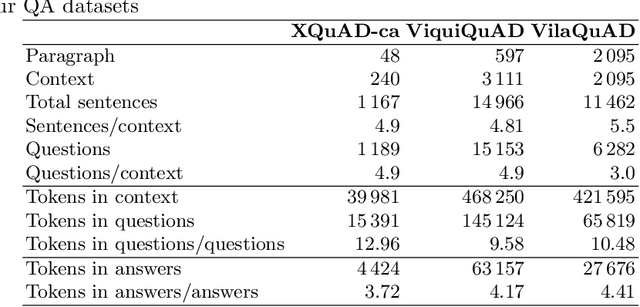

The Catalan Language Understanding Benchmark (CLUB) encompasses various datasets representative of different NLU tasks that enable accurate evaluations of language models, following the General Language Understanding Evaluation (GLUE) example. It is part of AINA and PlanTL, two public funding initiatives to empower the Catalan language in the Artificial Intelligence era.
On the Multilingual Capabilities of Very Large-Scale English Language Models
Aug 30, 2021
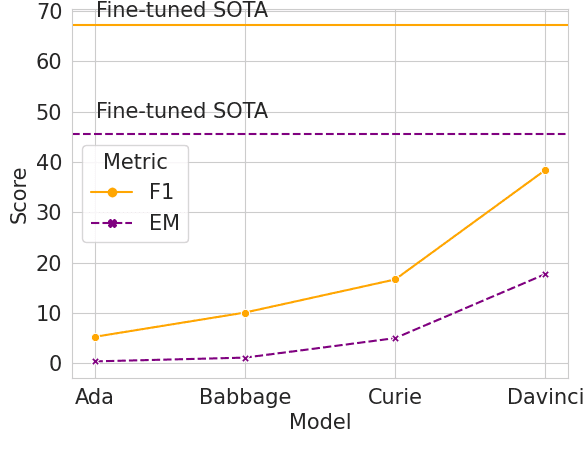

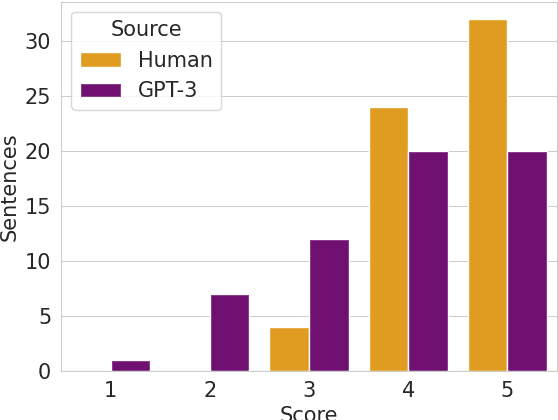
Generative Pre-trained Transformers (GPTs) have recently been scaled to unprecedented sizes in the history of machine learning. These models, solely trained on the language modeling objective, have been shown to exhibit outstanding few-shot learning capabilities in a number of different tasks. Nevertheless, aside from anecdotal experiences, little is known regarding their multilingual capabilities, given the fact that the pre-training corpus is almost entirely composed of English text. In this work, we investigate the multilingual skills of GPT-3, focusing on one language that barely appears in the pre-training corpus, Catalan, which makes the results especially meaningful; we assume that our results may be relevant for other languages as well. We find that the model shows an outstanding performance, particularly in generative tasks, with predictable limitations mostly in language understanding tasks but still with remarkable results given the zero-shot scenario. We investigate its potential and limits in extractive question-answering and natural language generation, as well as the effect of scale in terms of model size.
Are Multilingual Models the Best Choice for Moderately Under-resourced Languages? A Comprehensive Assessment for Catalan
Jul 16, 2021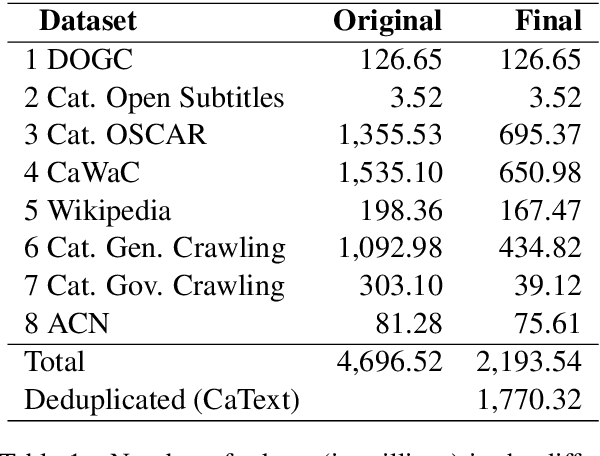
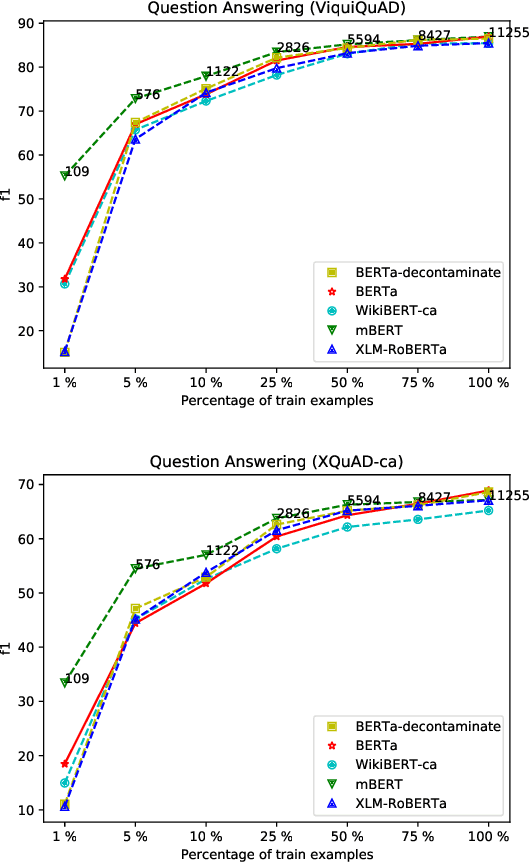

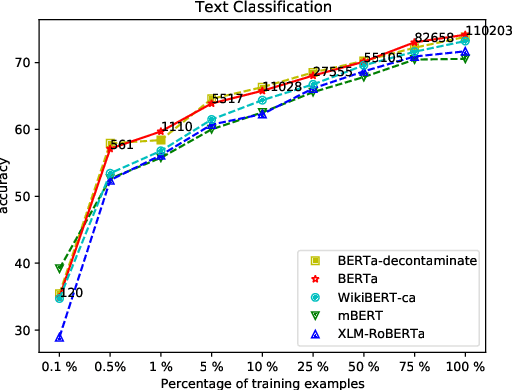
Multilingual language models have been a crucial breakthrough as they considerably reduce the need of data for under-resourced languages. Nevertheless, the superiority of language-specific models has already been proven for languages having access to large amounts of data. In this work, we focus on Catalan with the aim to explore to what extent a medium-sized monolingual language model is competitive with state-of-the-art large multilingual models. For this, we: (1) build a clean, high-quality textual Catalan corpus (CaText), the largest to date (but only a fraction of the usual size of the previous work in monolingual language models), (2) train a Transformer-based language model for Catalan (BERTa), and (3) devise a thorough evaluation in a diversity of settings, comprising a complete array of downstream tasks, namely, Part of Speech Tagging, Named Entity Recognition and Classification, Text Classification, Question Answering, and Semantic Textual Similarity, with most of the corresponding datasets being created ex novo. The result is a new benchmark, the Catalan Language Understanding Benchmark (CLUB), which we publish as an open resource, together with the clean textual corpus, the language model, and the cleaning pipeline. Using state-of-the-art multilingual models and a monolingual model trained only on Wikipedia as baselines, we consistently observe the superiority of our model across tasks and settings.
English-Catalan Neural Machine Translation in the Biomedical Domain through the cascade approach
Apr 26, 2018

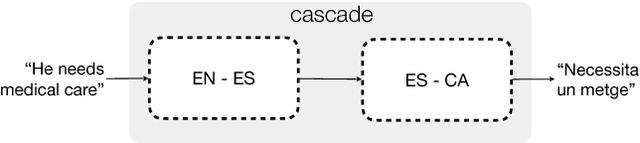
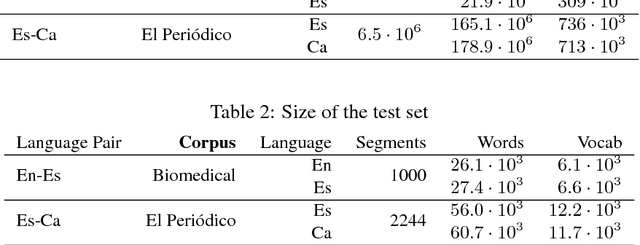
This paper describes the methodology followed to build a neural machine translation system in the biomedical domain for the English-Catalan language pair. This task can be considered a low-resourced task from the point of view of the domain and the language pair. To face this task, this paper reports experiments on a cascade pivot strategy through Spanish for the neural machine translation using the English-Spanish SCIELO and Spanish-Catalan El Peri\'odico database. To test the final performance of the system, we have created a new test data set for English-Catalan in the biomedical domain which is freely available on request.
* Full workshop proceedings can be found at https://multilingualbio.bsc.es/wp-content/uploads/2018/03/LREC-2018-PROCEEDINGS-MultilingualBIO.pdf