Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-Sequence Resources for Catalan
Paper and Code

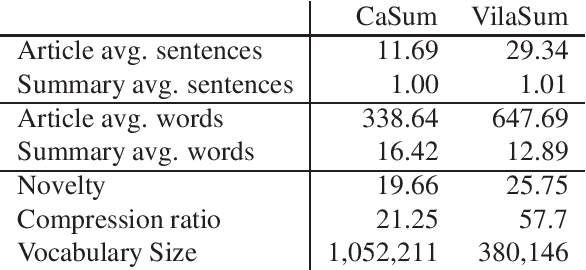
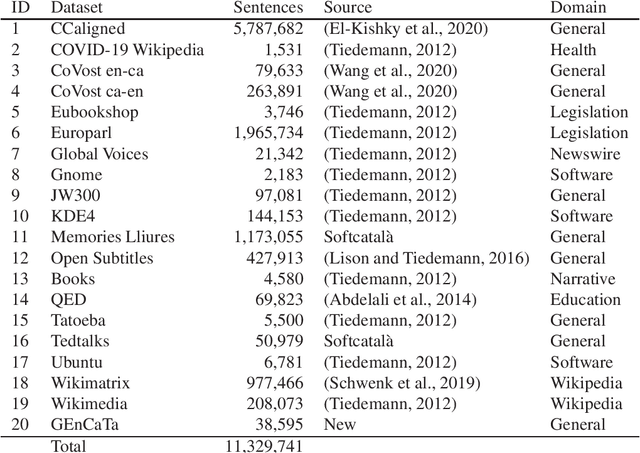

In this work, we introduce sequence-to-sequence language resources for Catalan, a moderately under-resourced language, towards two tasks, namely: Summarization and Machine Translation (MT). We present two new abstractive summarization datasets in the domain of newswire. We also introduce a parallel Catalan-English corpus, paired with three different brand new test sets. Finally, we evaluate the data presented with competing state of the art models, and we develop baselines for these tasks using a newly created Catalan BART. We release the resulting resources of this work under open license to encourage the development of language technology in Catalan.
View paper on