 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Low-Resource MT via Synthetic Data Generation with LLMs
May 20, 2025



We investigate the potential of LLM-generated synthetic data for improving low-resource machine translation (MT). Focusing on seven diverse target languages, we construct a document-level synthetic corpus from English Europarl, and extend it via pivoting to 147 additional language pairs. Automatic and human evaluation confirm its high overall quality. We study its practical application by (i) identifying effective training regimes, (ii) comparing our data with the HPLT dataset, and (iii) testing its utility beyond English-centric MT. Finally, we introduce SynOPUS, a public repository for synthetic parallel datasets. Our findings show that LLM-generated synthetic data, even when noisy, can substantially improve MT performance for low-resource languages.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
GlotEval: A Test Suite for Massively Multilingual Evaluation of Large Language Models
Apr 05, 2025Large language models (LLMs) are advancing at an unprecedented pace globally, with regions increasingly adopting these models for applications in their primary language. Evaluation of these models in diverse linguistic environments, especially in low-resource languages, has become a major challenge for academia and industry. Existing evaluation frameworks are disproportionately focused on English and a handful of high-resource languages, thereby overlooking the realistic performance of LLMs in multilingual and lower-resource scenarios. To address this gap, we introduce GlotEval, a lightweight framework designed for massively multilingual evaluation. Supporting seven key tasks (machine translation, text classification, summarization, open-ended generation, reading comprehension, sequence labeling, and intrinsic evaluation), spanning over dozens to hundreds of languages, GlotEval highlights consistent multilingual benchmarking, language-specific prompt templates, and non-English-centric machine translation. This enables a precise diagnosis of model strengths and weaknesses in diverse linguistic contexts. A multilingual translation case study demonstrates GlotEval's applicability for multilingual and language-specific evaluations.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
A New Massive Multilingual Dataset for High-Performance Language Technologies
Mar 20, 2024We present the HPLT (High Performance Language Technologies) language resources, a new massive multilingual dataset including both monolingual and bilingual corpora extracted from CommonCrawl and previously unused web crawls from the Internet Archive. We describe our methods for data acquisition, management and processing of large corpora, which rely on open-source software tools and high-performance computing. Our monolingual collection focuses on low- to medium-resourced languages and covers 75 languages and a total of ~5.6 trillion word tokens de-duplicated on the document level. Our English-centric parallel corpus is derived from its monolingual counterpart and covers 18 language pairs and more than 96 million aligned sentence pairs with roughly 1.4 billion English tokens. The HPLT language resources are one of the largest open text corpora ever released, providing a great resource for language modeling and machine translation training. We publicly release the corpora, the software, and the tools used in this work.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Sequence-to-Sequence Resources for Catalan
Feb 14, 2022
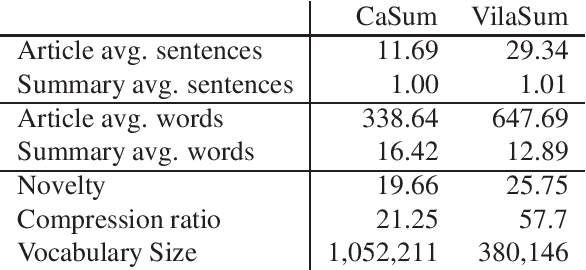
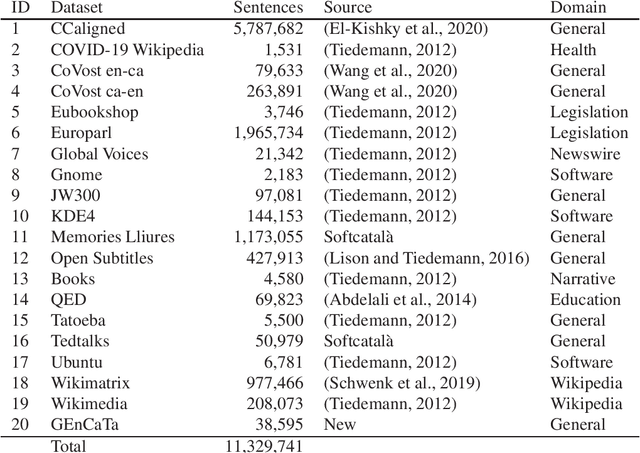

In this work, we introduce sequence-to-sequence language resources for Catalan, a moderately under-resourced language, towards two tasks, namely: Summarization and Machine Translation (MT). We present two new abstractive summarization datasets in the domain of newswire. We also introduce a parallel Catalan-English corpus, paired with three different brand new test sets. Finally, we evaluate the data presented with competing state of the art models, and we develop baselines for these tasks using a newly created Catalan BART. We release the resulting resources of this work under open license to encourage the development of language technology in Catalan.
Hate Speech Dataset from a White Supremacy Forum
Sep 12, 2018
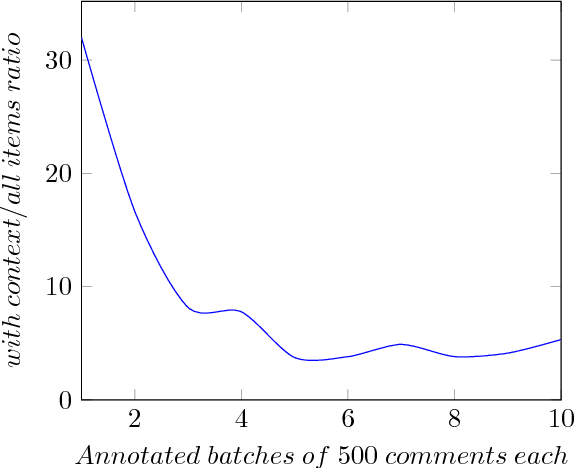

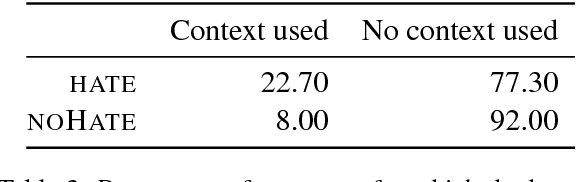
Hate speech is commonly defined as any communication that disparages a target group of people based on some characteristic such as race, colour, ethnicity, gender, sexual orientation, nationality, religion, or other characteristic. Due to the massive rise of user-generated web content on social media, the amount of hate speech is also steadily increasing. Over the past years, interest in online hate speech detection and, particularly, the automation of this task has continuously grown, along with the societal impact of the phenomenon. This paper describes a hate speech dataset composed of thousands of sentences manually labelled as containing hate speech or not. The sentences have been extracted from Stormfront, a white supremacist forum. A custom annotation tool has been developed to carry out the manual labelling task which, among other things, allows the annotators to choose whether to read the context of a sentence before labelling it. The paper also provides a thoughtful qualitative and quantitative study of the resulting dataset and several baseline experiments with different classification models. The dataset is publicly available.