 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnravelling the Mechanisms of Manipulating Numbers in Language Models
Oct 30, 2025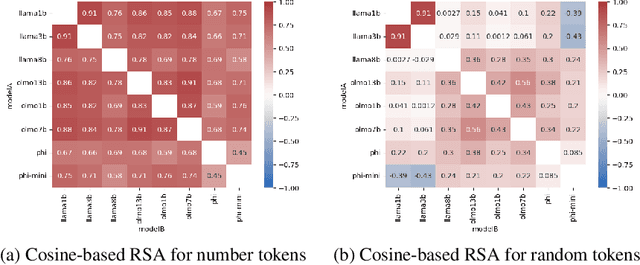

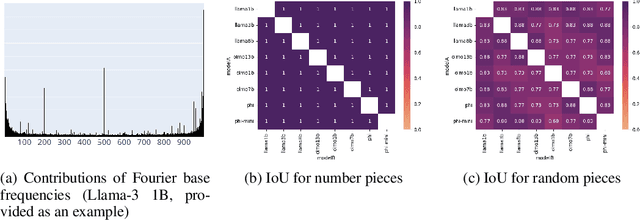
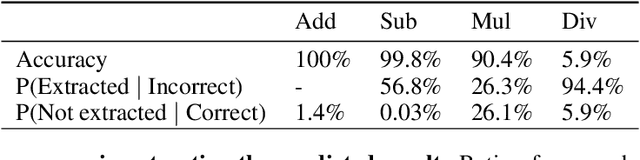
Recent work has shown that different large language models (LLMs) converge to similar and accurate input embedding representations for numbers. These findings conflict with the documented propensity of LLMs to produce erroneous outputs when dealing with numeric information. In this work, we aim to explain this conflict by exploring how language models manipulate numbers and quantify the lower bounds of accuracy of these mechanisms. We find that despite surfacing errors, different language models learn interchangeable representations of numbers that are systematic, highly accurate and universal across their hidden states and the types of input contexts. This allows us to create universal probes for each LLM and to trace information -- including the causes of output errors -- to specific layers. Our results lay a fundamental understanding of how pre-trained LLMs manipulate numbers and outline the potential of more accurate probing techniques in addressed refinements of LLMs' architectures.
Scaling Low-Resource MT via Synthetic Data Generation with LLMs
May 20, 2025



We investigate the potential of LLM-generated synthetic data for improving low-resource machine translation (MT). Focusing on seven diverse target languages, we construct a document-level synthetic corpus from English Europarl, and extend it via pivoting to 147 additional language pairs. Automatic and human evaluation confirm its high overall quality. We study its practical application by (i) identifying effective training regimes, (ii) comparing our data with the HPLT dataset, and (iii) testing its utility beyond English-centric MT. Finally, we introduce SynOPUS, a public repository for synthetic parallel datasets. Our findings show that LLM-generated synthetic data, even when noisy, can substantially improve MT performance for low-resource languages.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
GlotEval: A Test Suite for Massively Multilingual Evaluation of Large Language Models
Apr 05, 2025Large language models (LLMs) are advancing at an unprecedented pace globally, with regions increasingly adopting these models for applications in their primary language. Evaluation of these models in diverse linguistic environments, especially in low-resource languages, has become a major challenge for academia and industry. Existing evaluation frameworks are disproportionately focused on English and a handful of high-resource languages, thereby overlooking the realistic performance of LLMs in multilingual and lower-resource scenarios. To address this gap, we introduce GlotEval, a lightweight framework designed for massively multilingual evaluation. Supporting seven key tasks (machine translation, text classification, summarization, open-ended generation, reading comprehension, sequence labeling, and intrinsic evaluation), spanning over dozens to hundreds of languages, GlotEval highlights consistent multilingual benchmarking, language-specific prompt templates, and non-English-centric machine translation. This enables a precise diagnosis of model strengths and weaknesses in diverse linguistic contexts. A multilingual translation case study demonstrates GlotEval's applicability for multilingual and language-specific evaluations.
Your Model is Overconfident, and Other Lies We Tell Ourselves
Mar 03, 2025The difficulty intrinsic to a given example, rooted in its inherent ambiguity, is a key yet often overlooked factor in evaluating neural NLP models. We investigate the interplay and divergence among various metrics for assessing intrinsic difficulty, including annotator dissensus, training dynamics, and model confidence. Through a comprehensive analysis using 29 models on three datasets, we reveal that while correlations exist among these metrics, their relationships are neither linear nor monotonic. By disentangling these dimensions of uncertainty, we aim to refine our understanding of data complexity and its implications for evaluating and improving NLP models.
I Have an Attention Bridge to Sell You: Generalization Capabilities of Modular Translation Architectures
Apr 30, 2024



Modularity is a paradigm of machine translation with the potential of bringing forth models that are large at training time and small during inference. Within this field of study, modular approaches, and in particular attention bridges, have been argued to improve the generalization capabilities of models by fostering language-independent representations. In the present paper, we study whether modularity affects translation quality; as well as how well modular architectures generalize across different evaluation scenarios. For a given computational budget, we find non-modular architectures to be always comparable or preferable to all modular designs we study.
SemEval-2024 Shared Task 6: SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes
Mar 20, 2024This paper presents the results of the SHROOM, a shared task focused on detecting hallucinations: outputs from natural language generation (NLG) systems that are fluent, yet inaccurate. Such cases of overgeneration put in jeopardy many NLG applications, where correctness is often mission-critical. The shared task was conducted with a newly constructed dataset of 4000 model outputs labeled by 5 annotators each, spanning 3 NLP tasks: machine translation, paraphrase generation and definition modeling. The shared task was tackled by a total of 58 different users grouped in 42 teams, out of which 27 elected to write a system description paper; collectively, they submitted over 300 prediction sets on both tracks of the shared task. We observe a number of key trends in how this approach was tackled -- many participants rely on a handful of model, and often rely either on synthetic data for fine-tuning or zero-shot prompting strategies. While a majority of the teams did outperform our proposed baseline system, the performances of top-scoring systems are still consistent with a random handling of the more challenging items.
MAMMOTH: Massively Multilingual Modular Open Translation @ Helsinki
Mar 12, 2024



NLP in the age of monolithic large language models is approaching its limits in terms of size and information that can be handled. The trend goes to modularization, a necessary step into the direction of designing smaller sub-networks and components with specialized functionality. In this paper, we present the MAMMOTH toolkit: a framework designed for training massively multilingual modular machine translation systems at scale, initially derived from OpenNMT-py and then adapted to ensure efficient training across computation clusters. We showcase its efficiency across clusters of A100 and V100 NVIDIA GPUs, and discuss our design philosophy and plans for future information. The toolkit is publicly available online.
Why bother with geometry? On the relevance of linear decompositions of Transformer embeddings
Oct 10, 2023A recent body of work has demonstrated that Transformer embeddings can be linearly decomposed into well-defined sums of factors, that can in turn be related to specific network inputs or components. There is however still a dearth of work studying whether these mathematical reformulations are empirically meaningful. In the present work, we study representations from machine-translation decoders using two of such embedding decomposition methods. Our results indicate that, while decomposition-derived indicators effectively correlate with model performance, variation across different runs suggests a more nuanced take on this question. The high variability of our measurements indicate that geometry reflects model-specific characteristics more than it does sentence-specific computations, and that similar training conditions do not guarantee similar vector spaces.
The University of Helsinki submissions to the WMT19 news translation task
Jun 10, 2019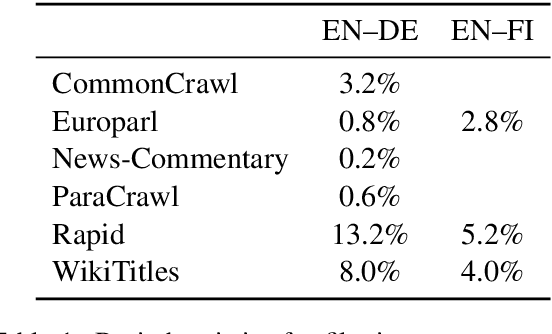
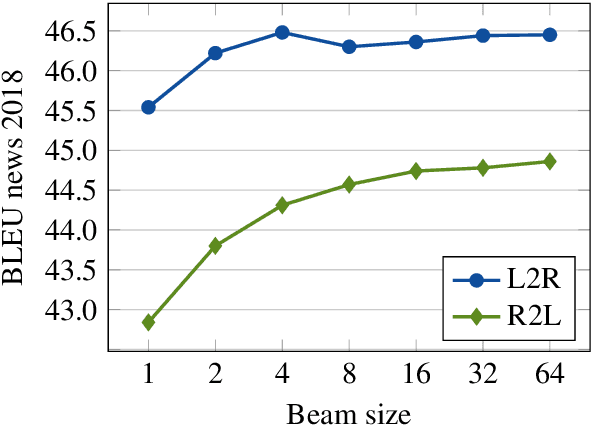

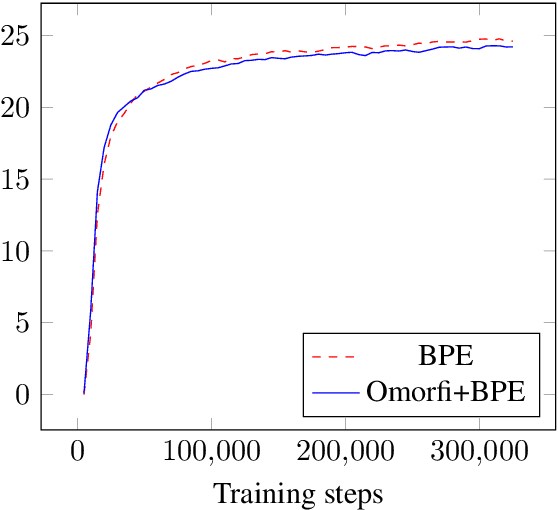
In this paper, we present the University of Helsinki submissions to the WMT 2019 shared task on news translation in three language pairs: English-German, English-Finnish and Finnish-English. This year, we focused first on cleaning and filtering the training data using multiple data-filtering approaches, resulting in much smaller and cleaner training sets. For English-German, we trained both sentence-level transformer models and compared different document-level translation approaches. For Finnish-English and English-Finnish we focused on different segmentation approaches, and we also included a rule-based system for English-Finnish.