 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs' morphological analyses of complex FST-generated Finnish words
Jul 11, 2024



Rule-based language processing systems have been overshadowed by neural systems in terms of utility, but it remains unclear whether neural NLP systems, in practice, learn the grammar rules that humans use. This work aims to shed light on the issue by evaluating state-of-the-art LLMs in a task of morphological analysis of complex Finnish noun forms. We generate the forms using an FST tool, and they are unlikely to have occurred in the training sets of the LLMs, therefore requiring morphological generalisation capacity. We find that GPT-4-turbo has some difficulties in the task while GPT-3.5-turbo struggles and smaller models Llama2-70B and Poro-34B fail nearly completely.
On Using Distribution-Based Compositionality Assessment to Evaluate Compositional Generalisation in Machine Translation
Nov 14, 2023

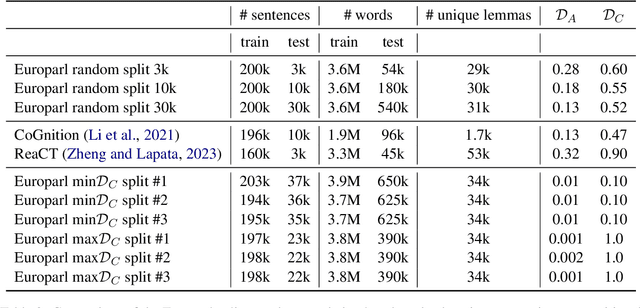

Compositional generalisation (CG), in NLP and in machine learning more generally, has been assessed mostly using artificial datasets. It is important to develop benchmarks to assess CG also in real-world natural language tasks in order to understand the abilities and limitations of systems deployed in the wild. To this end, our GenBench Collaborative Benchmarking Task submission utilises the distribution-based compositionality assessment (DBCA) framework to split the Europarl translation corpus into a training and a test set in such a way that the test set requires compositional generalisation capacity. Specifically, the training and test sets have divergent distributions of dependency relations, testing NMT systems' capability of translating dependencies that they have not been trained on. This is a fully-automated procedure to create natural language compositionality benchmarks, making it simple and inexpensive to apply it further to other datasets and languages. The code and data for the experiments is available at https://github.com/aalto-speech/dbca.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Semantic Search as Extractive Paraphrase Span Detection
Dec 09, 2021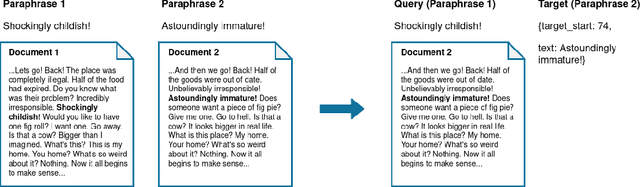
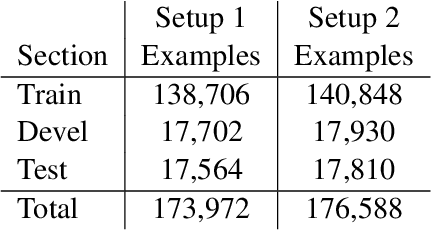
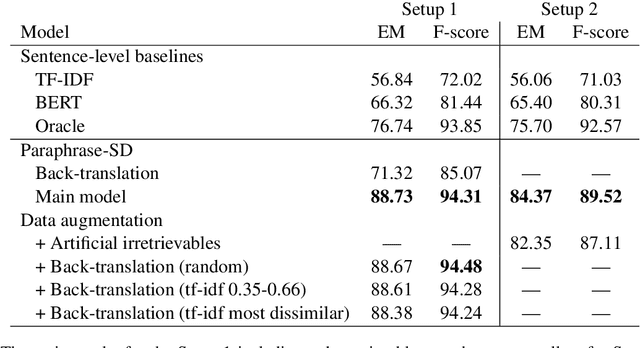
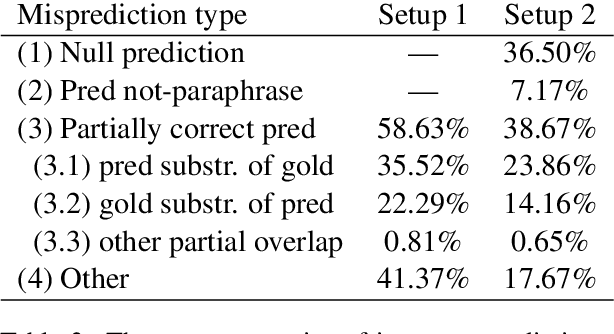
In this paper, we approach the problem of semantic search by framing the search task as paraphrase span detection, i.e. given a segment of text as a query phrase, the task is to identify its paraphrase in a given document, the same modelling setup as typically used in extractive question answering. On the Turku Paraphrase Corpus of 100,000 manually extracted Finnish paraphrase pairs including their original document context, we find that our paraphrase span detection model outperforms two strong retrieval baselines (lexical similarity and BERT sentence embeddings) by 31.9pp and 22.4pp respectively in terms of exact match, and by 22.3pp and 12.9pp in terms of token-level F-score. This demonstrates a strong advantage of modelling the task in terms of span retrieval, rather than sentence similarity. Additionally, we introduce a method for creating artificial paraphrase data through back-translation, suitable for languages where manually annotated paraphrase resources for training the span detection model are not available.
Grammatical Error Generation Based on Translated Fragments
Apr 20, 2021

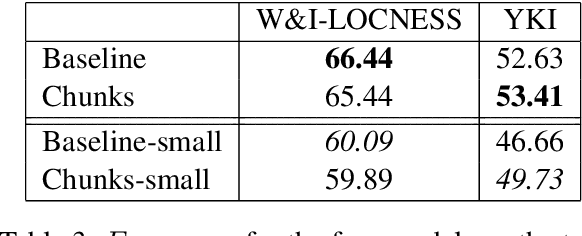
We perform neural machine translation of sentence fragments in order to create large amounts of training data for English grammatical error correction. Our method aims at simulating mistakes made by second language learners, and produces a wider range of non-native style language in comparison to state-of-the-art synthetic data creation methods. In addition to purely grammatical errors, our approach generates other types of errors, such as lexical errors. We perform grammatical error correction experiments using neural sequence-to-sequence models, and carry out quantitative and qualitative evaluation. A model trained on data created using our proposed method is shown to outperform a baseline model on test data with a high proportion of errors.
Multilingual NMT with a language-independent attention bridge
Nov 01, 2018
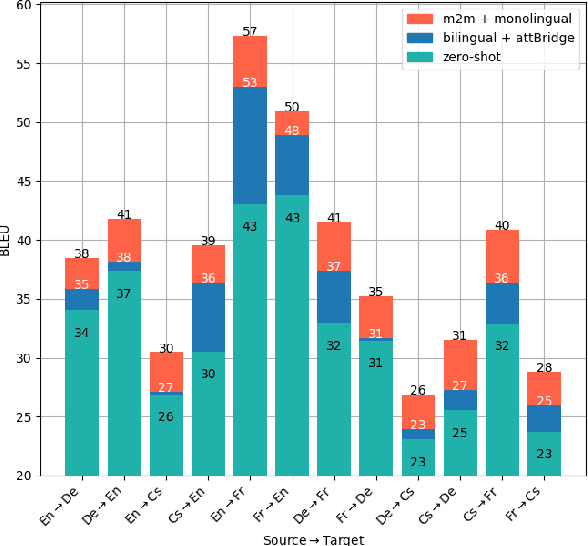
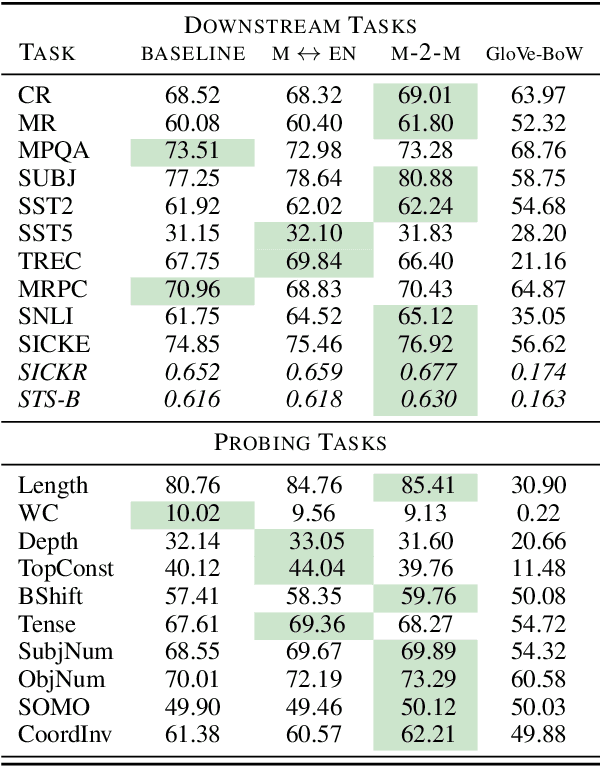
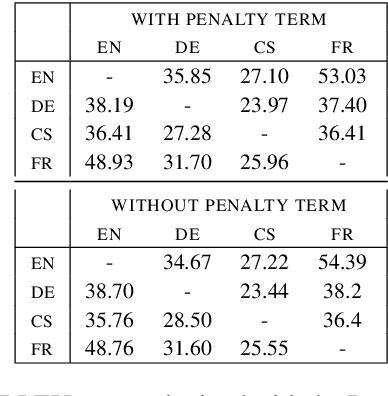
In this paper, we propose a multilingual encoder-decoder architecture capable of obtaining multilingual sentence representations by means of incorporating an intermediate {\em attention bridge} that is shared across all languages. That is, we train the model with language-specific encoders and decoders that are connected via self-attention with a shared layer that we call attention bridge. This layer exploits the semantics from each language for performing translation and develops into a language-independent meaning representation that can efficiently be used for transfer learning. We present a new framework for the efficient development of multilingual NMT using this model and scheduled training. We have tested the approach in a systematic way with a multi-parallel data set. We show that the model achieves substantial improvements over strong bilingual models and that it also works well for zero-shot translation, which demonstrates its ability of abstraction and transfer learning.
Paraphrase Detection on Noisy Subtitles in Six Languages
Sep 21, 2018
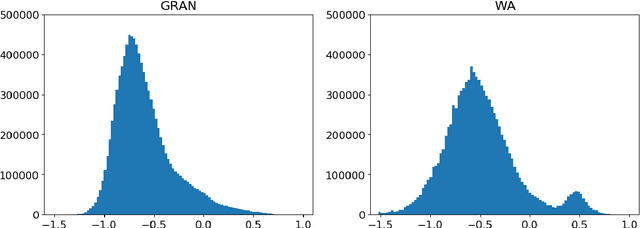
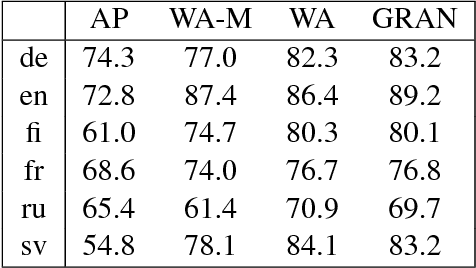
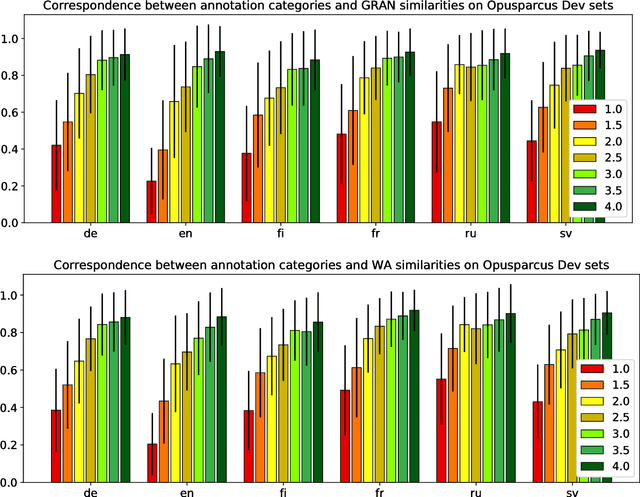
We perform automatic paraphrase detection on subtitle data from the Opusparcus corpus comprising six European languages: German, English, Finnish, French, Russian, and Swedish. We train two types of supervised sentence embedding models: a word-averaging (WA) model and a gated recurrent averaging network (GRAN) model. We find out that GRAN outperforms WA and is more robust to noisy training data. Better results are obtained with more and noisier data than less and cleaner data. Additionally, we experiment on other datasets, without reaching the same level of performance, because of domain mismatch between training and test data.
Open Subtitles Paraphrase Corpus for Six Languages
Sep 17, 2018
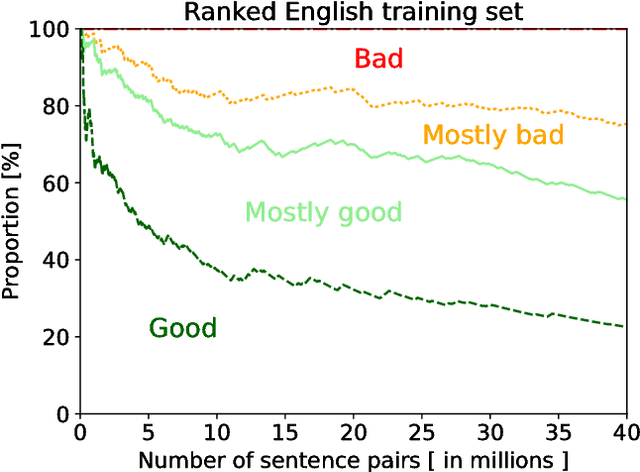

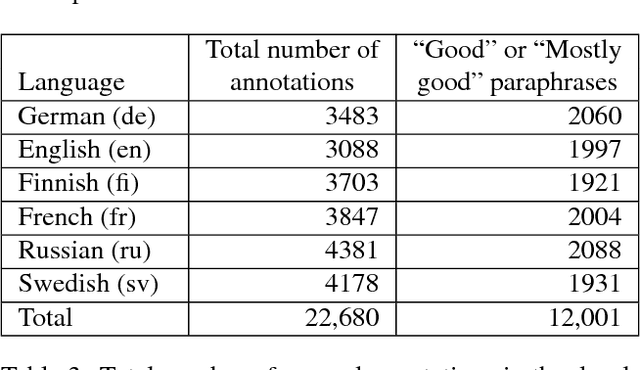
This paper accompanies the release of Opusparcus, a new paraphrase corpus for six European languages: German, English, Finnish, French, Russian, and Swedish. The corpus consists of paraphrases, that is, pairs of sentences in the same language that mean approximately the same thing. The paraphrases are extracted from the OpenSubtitles2016 corpus, which contains subtitles from movies and TV shows. The informal and colloquial genre that occurs in subtitles makes such data a very interesting language resource, for instance, from the perspective of computer assisted language learning. For each target language, the Opusparcus data have been partitioned into three types of data sets: training, development and test sets. The training sets are large, consisting of millions of sentence pairs, and have been compiled automatically, with the help of probabilistic ranking functions. The development and test sets consist of sentence pairs that have been checked manually; each set contains approximately 1000 sentence pairs that have been verified to be acceptable paraphrases by two annotators.
Unsupervised Discovery of Morphemes
May 21, 2002
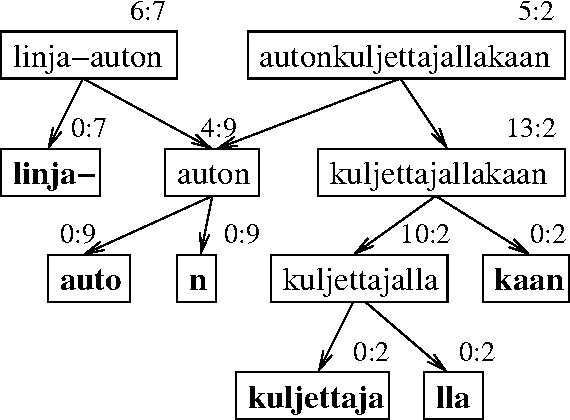
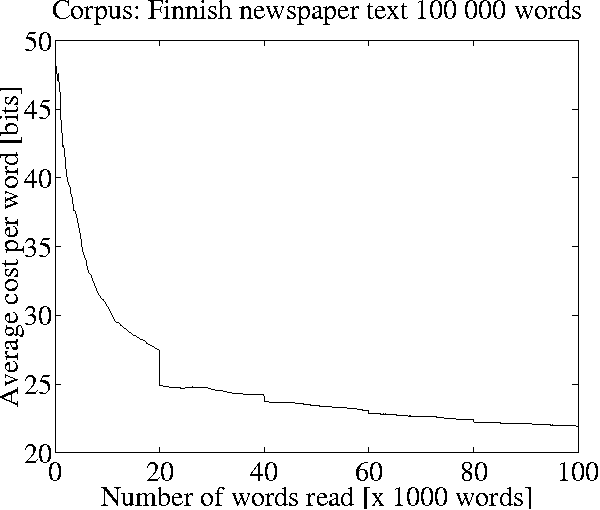
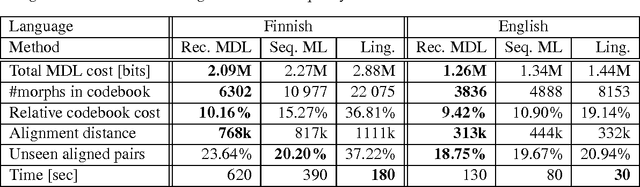
We present two methods for unsupervised segmentation of words into morpheme-like units. The model utilized is especially suited for languages with a rich morphology, such as Finnish. The first method is based on the Minimum Description Length (MDL) principle and works online. In the second method, Maximum Likelihood (ML) optimization is used. The quality of the segmentations is measured using an evaluation method that compares the segmentations produced to an existing morphological analysis. Experiments on both Finnish and English corpora show that the presented methods perform well compared to a current state-of-the-art system.