 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Search as Extractive Paraphrase Span Detection
Paper and Code
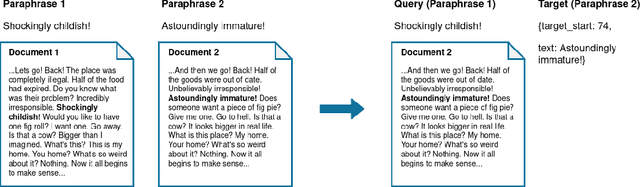
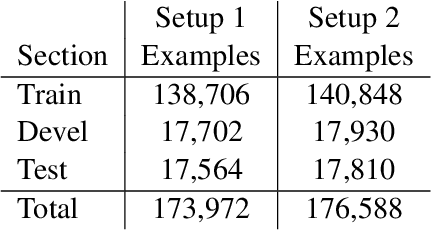
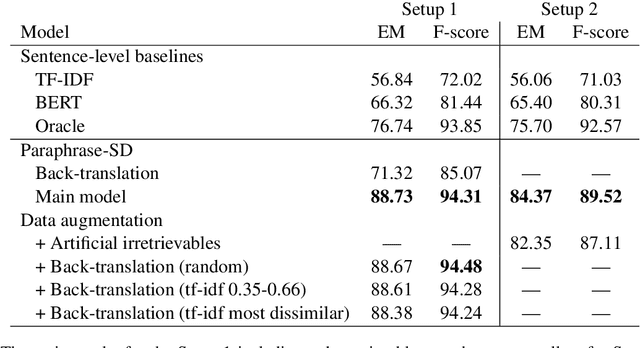
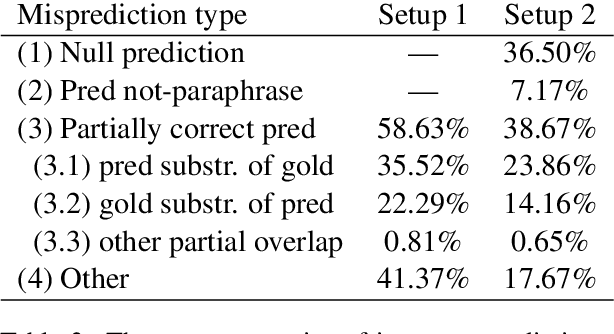
In this paper, we approach the problem of semantic search by framing the search task as paraphrase span detection, i.e. given a segment of text as a query phrase, the task is to identify its paraphrase in a given document, the same modelling setup as typically used in extractive question answering. On the Turku Paraphrase Corpus of 100,000 manually extracted Finnish paraphrase pairs including their original document context, we find that our paraphrase span detection model outperforms two strong retrieval baselines (lexical similarity and BERT sentence embeddings) by 31.9pp and 22.4pp respectively in terms of exact match, and by 22.3pp and 12.9pp in terms of token-level F-score. This demonstrates a strong advantage of modelling the task in terms of span retrieval, rather than sentence similarity. Additionally, we introduce a method for creating artificial paraphrase data through back-translation, suitable for languages where manually annotated paraphrase resources for training the span detection model are not available.