 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Social Integration Through Participation: Categorizing Organizations and Leisure Activities in the Displaced Karelians Interview Archive using LLMs
Feb 17, 2026Digitized historical archives make it possible to study everyday social life on a large scale, but the information extracted directly from text often does not directly allow one to answer the research questions posed by historians or sociologists in a quantitative manner. We address this problem in a large collection of Finnish World War II Karelian evacuee family interviews. Prior work extracted more than 350K mentions of leisure time activities and organizational memberships from these interviews, yielding 71K unique activity and organization names -- far too many to analyze directly. We develop a categorization framework that captures key aspects of participation (the kind of activity/organization, how social it typically is, how regularly it happens, and how physically demanding it is). We annotate a gold-standard set to allow for a reliable evaluation, and then test whether large language models can apply the same schema at scale. Using a simple voting approach across multiple model runs, we find that an open-weight LLM can closely match expert judgments. Finally, we apply the method to label the 350K entities, producing a structured resource for downstream studies of social integration and related outcomes.
Creating a Historical Migration Dataset from Finnish Church Records, 1800-1920
Jun 09, 2025
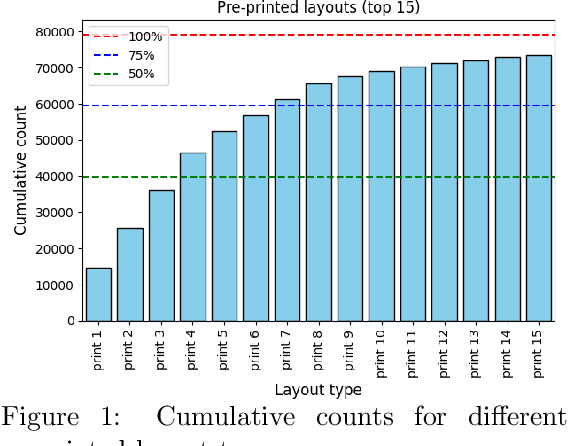

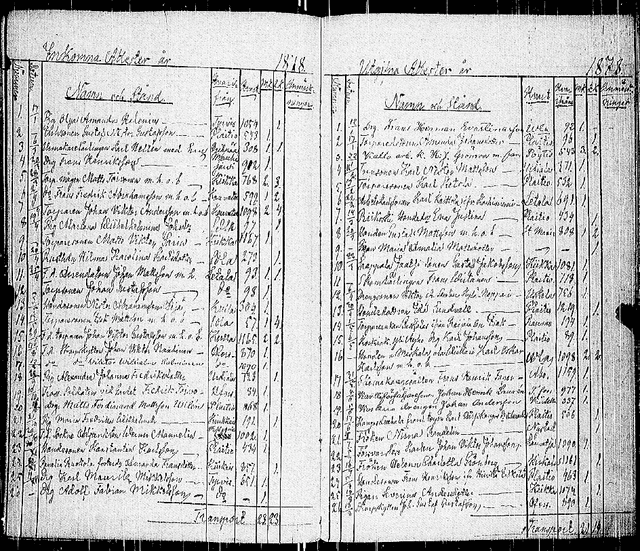
This article presents a large-scale effort to create a structured dataset of internal migration in Finland between 1800 and 1920 using digitized church moving records. These records, maintained by Evangelical-Lutheran parishes, document the migration of individuals and families and offer a valuable source for studying historical demographic patterns. The dataset includes over six million entries extracted from approximately 200,000 images of handwritten migration records. The data extraction process was automated using a deep learning pipeline that included layout analysis, table detection, cell classification, and handwriting recognition. The complete pipeline was applied to all images, resulting in a structured dataset suitable for research. The dataset can be used to study internal migration, urbanization, and family migration, and the spread of disease in preindustrial Finland. A case study from the Elim\"aki parish shows how local migration histories can be reconstructed. The work demonstrates how large volumes of handwritten archival material can be transformed into structured data to support historical and demographic research.
Extracting Social Connections from Finnish Karelian Refugee Interviews Using LLMs
Feb 19, 2025
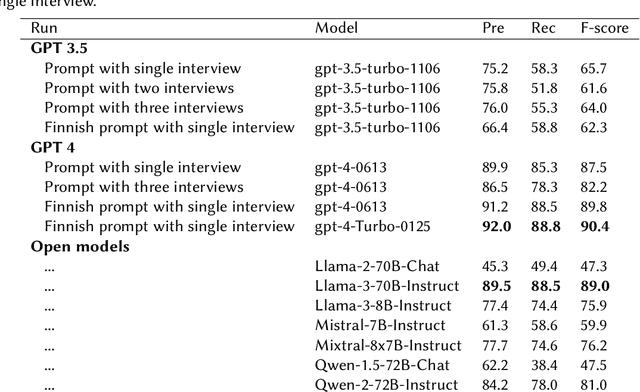

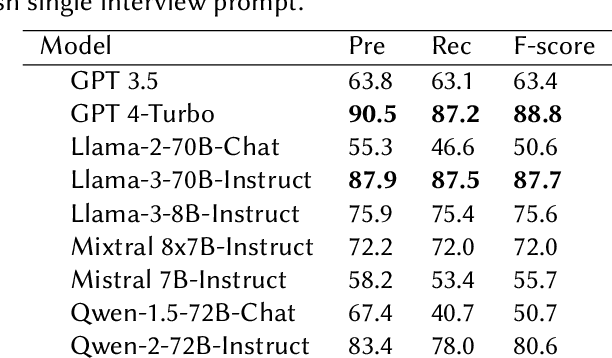
We performed a zero-shot information extraction study on a historical collection of 89,339 brief Finnish-language interviews of refugee families relocated post-WWII from Finnish Eastern Karelia. Our research objective is two-fold. First, we aim to extract social organizations and hobbies from the free text of the interviews, separately for each family member. These can act as a proxy variable indicating the degree of social integration of refugees in their new environment. Second, we aim to evaluate several alternative ways to approach this task, comparing a number of generative models and a supervised learning approach, to gain a broader insight into the relative merits of these different approaches and their applicability in similar studies. We find that the best generative model (GPT-4) is roughly on par with human performance, at an F-score of 88.8%. Interestingly, the best open generative model (Llama-3-70B-Instruct) reaches almost the same performance, at 87.7% F-score, demonstrating that open models are becoming a viable alternative for some practical tasks even on non-English data. Additionally, we test a supervised learning alternative, where we fine-tune a Finnish BERT model (FinBERT) using GPT-4 generated training data. By this method, we achieved an F-score of 84.1% already with 6K interviews up to an F-score of 86.3% with 30k interviews. Such an approach would be particularly appealing in cases where the computational resources are limited, or there is a substantial mass of data to process.
OCR Error Post-Correction with LLMs in Historical Documents: No Free Lunches
Feb 03, 2025

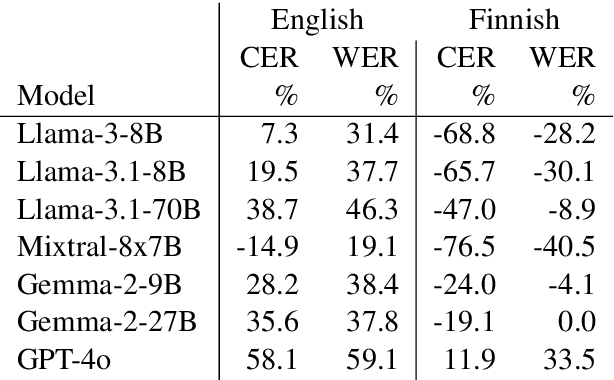
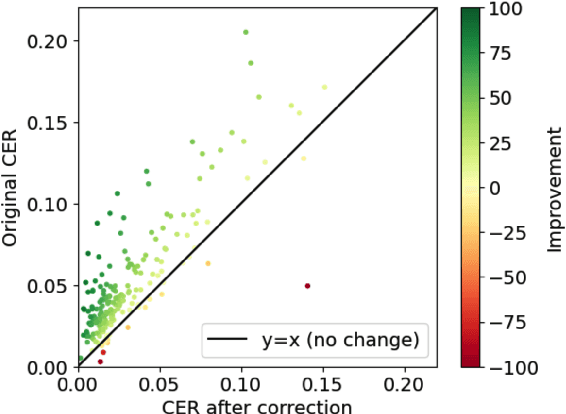
Optical Character Recognition (OCR) systems often introduce errors when transcribing historical documents, leaving room for post-correction to improve text quality. This study evaluates the use of open-weight LLMs for OCR error correction in historical English and Finnish datasets. We explore various strategies, including parameter optimization, quantization, segment length effects, and text continuation methods. Our results demonstrate that while modern LLMs show promise in reducing character error rates (CER) in English, a practically useful performance for Finnish was not reached. Our findings highlight the potential and limitations of LLMs in scaling OCR post-correction for large historical corpora.
FinGPT: Large Generative Models for a Small Language
Nov 03, 2023



Large language models (LLMs) excel in many tasks in NLP and beyond, but most open models have very limited coverage of smaller languages and LLM work tends to focus on languages where nearly unlimited data is available for pretraining. In this work, we study the challenges of creating LLMs for Finnish, a language spoken by less than 0.1% of the world population. We compile an extensive dataset of Finnish combining web crawls, news, social media and eBooks. We pursue two approaches to pretrain models: 1) we train seven monolingual models from scratch (186M to 13B parameters) dubbed FinGPT, 2) we continue the pretraining of the multilingual BLOOM model on a mix of its original training data and Finnish, resulting in a 176 billion parameter model we call BLUUMI. For model evaluation, we introduce FIN-bench, a version of BIG-bench with Finnish tasks. We also assess other model qualities such as toxicity and bias. Our models and tools are openly available at https://turkunlp.org/gpt3-finnish.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Out-of-Domain Evaluation of Finnish Dependency Parsing
Apr 22, 2022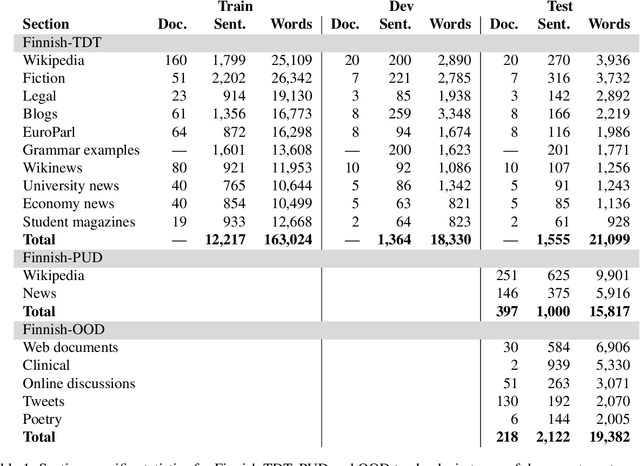

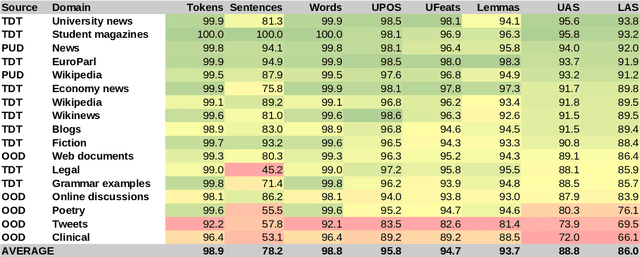
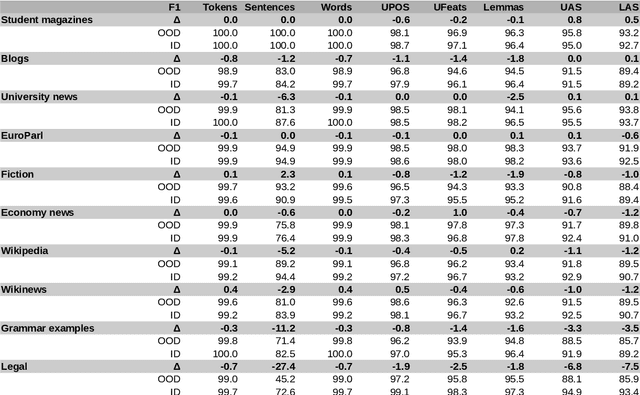
The prevailing practice in the academia is to evaluate the model performance on in-domain evaluation data typically set aside from the training corpus. However, in many real world applications the data on which the model is applied may very substantially differ from the characteristics of the training data. In this paper, we focus on Finnish out-of-domain parsing by introducing a novel UD Finnish-OOD out-of-domain treebank including five very distinct data sources (web documents, clinical, online discussions, tweets, and poetry), and a total of 19,382 syntactic words in 2,122 sentences released under the Universal Dependencies framework. Together with the new treebank, we present extensive out-of-domain parsing evaluation utilizing the available section-level information from three different Finnish UD treebanks (TDT, PUD, OOD). Compared to the previously existing treebanks, the new Finnish-OOD is shown include sections more challenging for the general parser, creating an interesting evaluation setting and yielding valuable information for those applying the parser outside of its training domain.
Semantic Search as Extractive Paraphrase Span Detection
Dec 09, 2021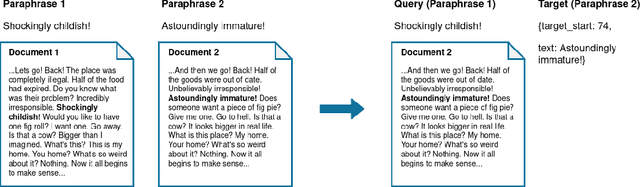
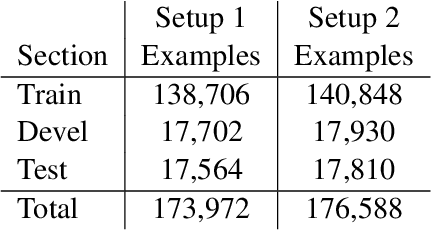
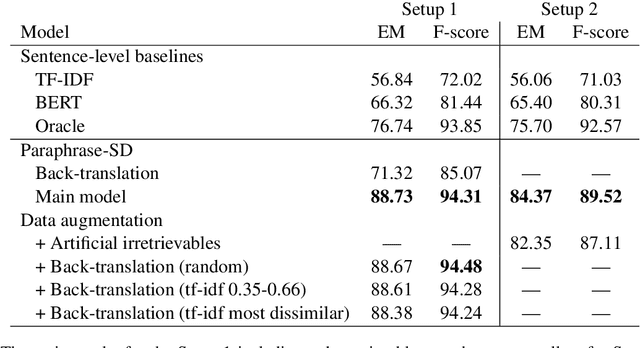
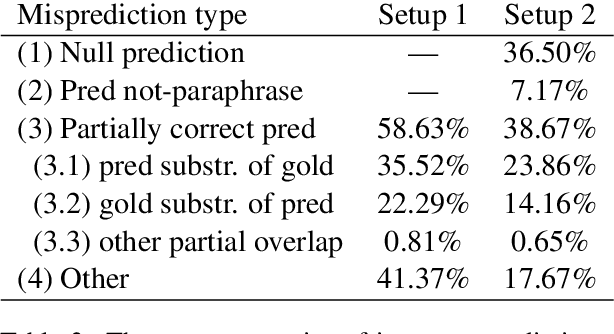
In this paper, we approach the problem of semantic search by framing the search task as paraphrase span detection, i.e. given a segment of text as a query phrase, the task is to identify its paraphrase in a given document, the same modelling setup as typically used in extractive question answering. On the Turku Paraphrase Corpus of 100,000 manually extracted Finnish paraphrase pairs including their original document context, we find that our paraphrase span detection model outperforms two strong retrieval baselines (lexical similarity and BERT sentence embeddings) by 31.9pp and 22.4pp respectively in terms of exact match, and by 22.3pp and 12.9pp in terms of token-level F-score. This demonstrates a strong advantage of modelling the task in terms of span retrieval, rather than sentence similarity. Additionally, we introduce a method for creating artificial paraphrase data through back-translation, suitable for languages where manually annotated paraphrase resources for training the span detection model are not available.
Annotation Guidelines for the Turku Paraphrase Corpus
Aug 19, 2021This document describes the annotation guidelines used to construct the Turku Paraphrase Corpus. These guidelines were developed together with the corpus annotation, revising and extending the guidelines regularly during the annotation work. Our paraphrase annotation scheme uses the base scale 1-4, where labels 1 and 2 are used for negative candidates (not paraphrases), while labels 3 and 4 are paraphrases at least in the given context if not everywhere. In addition to base labeling, the scheme is enriched with additional subcategories (flags) for categorizing different types of paraphrases inside the two positive labels, making the annotation scheme suitable for more fine-grained paraphrase categorization. The annotation scheme is used to annotate over 100,000 Finnish paraphrase pairs.
Quantitative Evaluation of Alternative Translations in a Corpus of Highly Dissimilar Finnish Paraphrases
May 06, 2021
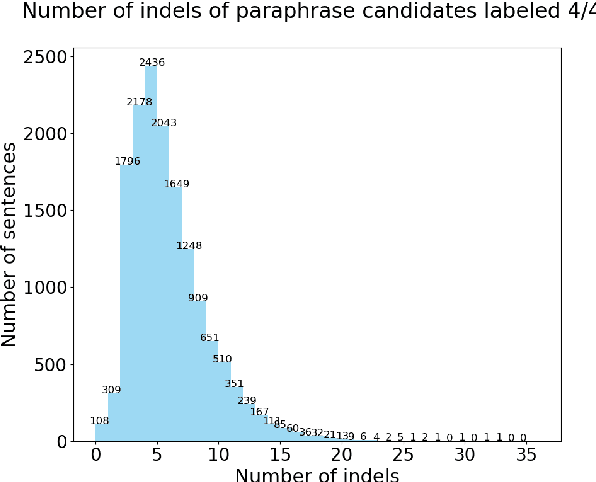
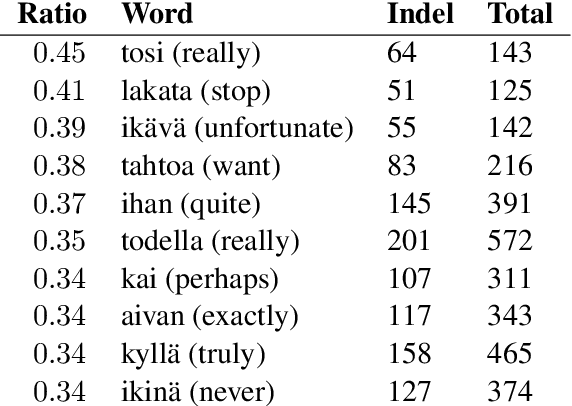

In this paper, we present a quantitative evaluation of differences between alternative translations in a large recently released Finnish paraphrase corpus focusing in particular on non-trivial variation in translation. We combine a series of automatic steps detecting systematic variation with manual analysis to reveal regularities and identify categories of translation differences. We find the paraphrase corpus to contain highly non-trivial translation variants difficult to recognize through automatic approaches.