 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinnish SQuAD: A Simple Approach to Machine Translation of Span Annotations
Jan 10, 2025We apply a simple method to machine translate datasets with span-level annotation using the DeepL MT service and its ability to translate formatted documents. Using this method, we produce a Finnish version of the SQuAD2.0 question answering dataset and train QA retriever models on this new dataset. We evaluate the quality of the dataset and more generally the MT method through direct evaluation, indirect comparison to other similar datasets, a backtranslation experiment, as well as through the performance of downstream trained QA models. In all these evaluations, we find that the method of transfer is not only simple to use but produces consistently better translated data. Given its good performance on the SQuAD dataset, it is likely the method can be used to translate other similar span-annotated datasets for other tasks and languages as well. All code and data is available under an open license: data at HuggingFace TurkuNLP/squad_v2_fi, code on GitHub TurkuNLP/squad2-fi, and model at HuggingFace TurkuNLP/bert-base-finnish-cased-squad2.
Annotation Guidelines for the Turku Paraphrase Corpus
Aug 19, 2021This document describes the annotation guidelines used to construct the Turku Paraphrase Corpus. These guidelines were developed together with the corpus annotation, revising and extending the guidelines regularly during the annotation work. Our paraphrase annotation scheme uses the base scale 1-4, where labels 1 and 2 are used for negative candidates (not paraphrases), while labels 3 and 4 are paraphrases at least in the given context if not everywhere. In addition to base labeling, the scheme is enriched with additional subcategories (flags) for categorizing different types of paraphrases inside the two positive labels, making the annotation scheme suitable for more fine-grained paraphrase categorization. The annotation scheme is used to annotate over 100,000 Finnish paraphrase pairs.
Deep learning for sentence clustering in essay grading support
Apr 23, 2021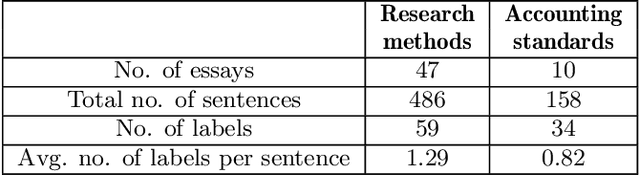
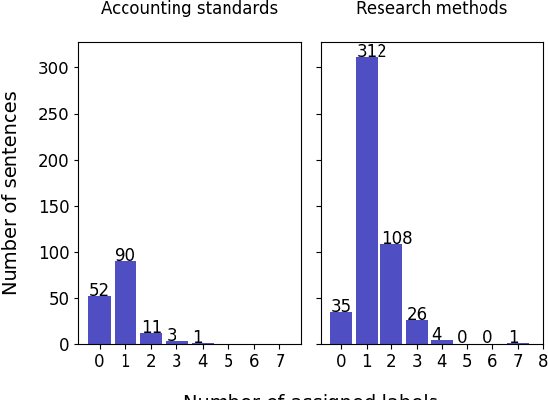

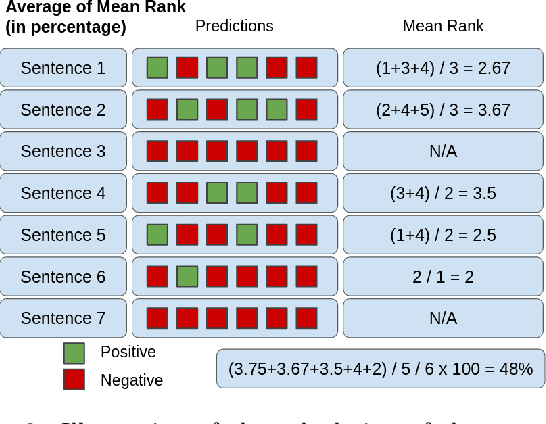
Essays as a form of assessment test student knowledge on a deeper level than short answer and multiple-choice questions. However, the manual evaluation of essays is time- and labor-consuming. Automatic clustering of essays, or their fragments, prior to manual evaluation presents a possible solution to reducing the effort required in the evaluation process. Such clustering presents numerous challenges due to the variability and ambiguity of natural language. In this paper, we introduce two datasets of undergraduate student essays in Finnish, manually annotated for salient arguments on the sentence level. Using these datasets, we evaluate several deep-learning embedding methods for their suitability to sentence clustering in support of essay grading. We find that the choice of the most suitable method depends on the nature of the exam question and the answers, with deep-learning methods being capable of, but not guaranteeing better performance over simpler methods based on lexical overlap.
Finnish Paraphrase Corpus
Mar 24, 2021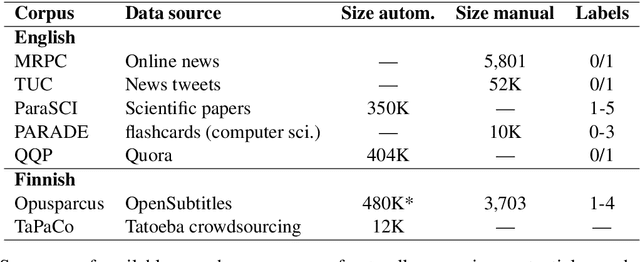
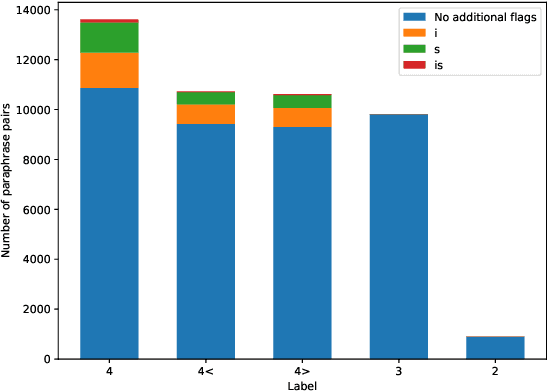

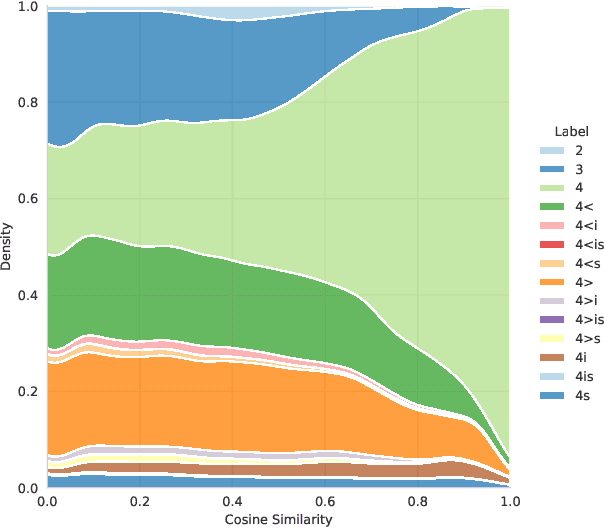
In this paper, we introduce the first fully manually annotated paraphrase corpus for Finnish containing 53,572 paraphrase pairs harvested from alternative subtitles and news headings. Out of all paraphrase pairs in our corpus 98% are manually classified to be paraphrases at least in their given context, if not in all contexts. Additionally, we establish a manual candidate selection method and demonstrate its feasibility in high quality paraphrase selection in terms of both cost and quality.