 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation Guidelines for the Turku Paraphrase Corpus
Aug 19, 2021This document describes the annotation guidelines used to construct the Turku Paraphrase Corpus. These guidelines were developed together with the corpus annotation, revising and extending the guidelines regularly during the annotation work. Our paraphrase annotation scheme uses the base scale 1-4, where labels 1 and 2 are used for negative candidates (not paraphrases), while labels 3 and 4 are paraphrases at least in the given context if not everywhere. In addition to base labeling, the scheme is enriched with additional subcategories (flags) for categorizing different types of paraphrases inside the two positive labels, making the annotation scheme suitable for more fine-grained paraphrase categorization. The annotation scheme is used to annotate over 100,000 Finnish paraphrase pairs.
Finnish Paraphrase Corpus
Mar 24, 2021
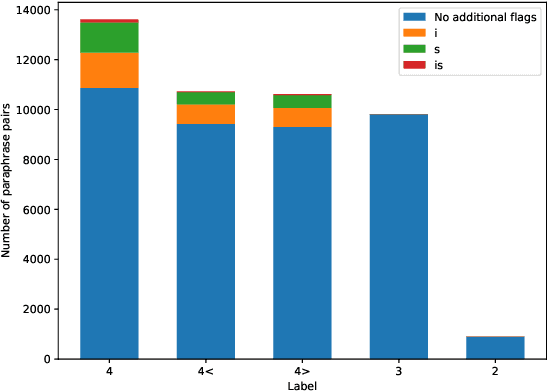

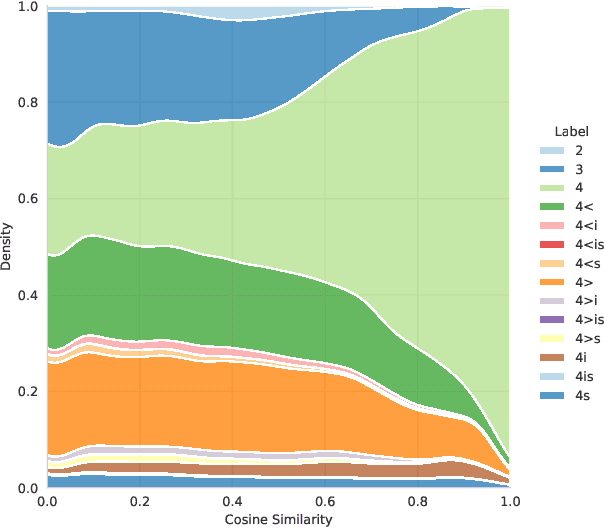
In this paper, we introduce the first fully manually annotated paraphrase corpus for Finnish containing 53,572 paraphrase pairs harvested from alternative subtitles and news headings. Out of all paraphrase pairs in our corpus 98% are manually classified to be paraphrases at least in their given context, if not in all contexts. Additionally, we establish a manual candidate selection method and demonstrate its feasibility in high quality paraphrase selection in terms of both cost and quality.
Beyond the English Web: Zero-Shot Cross-Lingual and Lightweight Monolingual Classification of Registers
Feb 15, 2021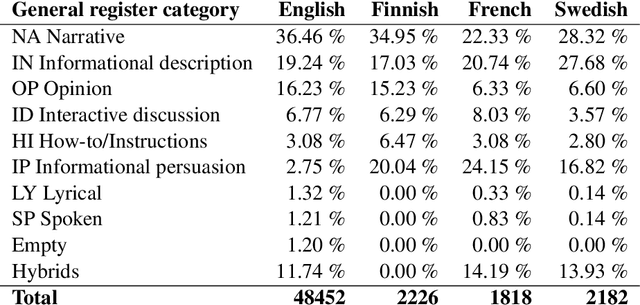
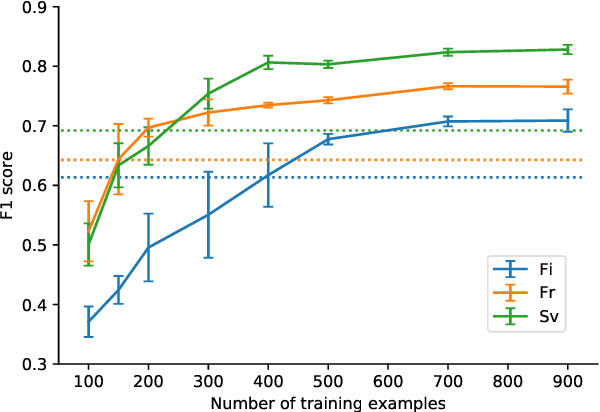
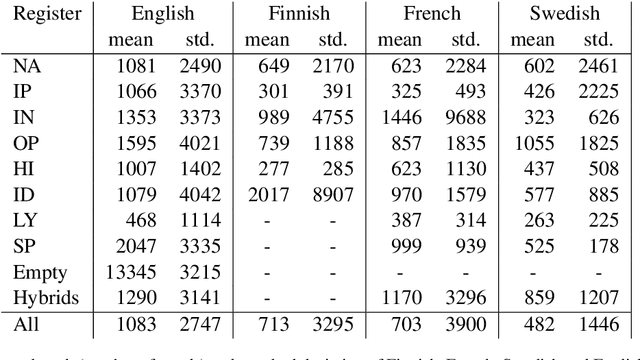
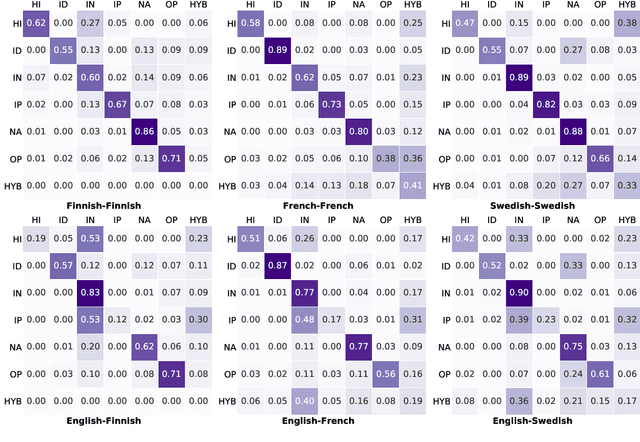
We explore cross-lingual transfer of register classification for web documents. Registers, that is, text varieties such as blogs or news are one of the primary predictors of linguistic variation and thus affect the automatic processing of language. We introduce two new register annotated corpora, FreCORE and SweCORE, for French and Swedish. We demonstrate that deep pre-trained language models perform strongly in these languages and outperform previous state-of-the-art in English and Finnish. Specifically, we show 1) that zero-shot cross-lingual transfer from the large English CORE corpus can match or surpass previously published monolingual models, and 2) that lightweight monolingual classification requiring very little training data can reach or surpass our zero-shot performance. We further analyse classification results finding that certain registers continue to pose challenges in particular for cross-lingual transfer.