 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUntangling the Unrestricted Web: Automatic Identification of Multilingual Registers
Jun 28, 2024


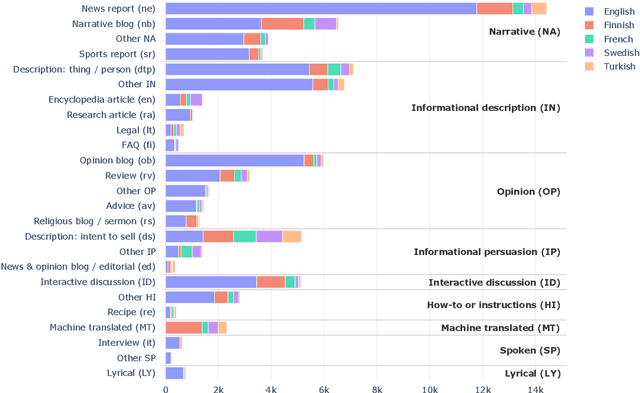
This article explores deep learning models for the automatic identification of registers - text varieties such as news reports and discussion forums - in web-based datasets across 16 languages. Web register (or genre) identification would provide a robust solution for understanding the content of web-scale datasets, which have become crucial in computational linguistics. Despite recent advances, the potential of register classifiers on the noisy web remains largely unexplored, particularly in multilingual settings and when targeting the entire unrestricted web. We experiment with a range of deep learning models using the new Multilingual CORE corpora, which includes 16 languages annotated using a detailed, hierarchical taxonomy of 25 registers designed to cover the entire unrestricted web. Our models achieve state-of-the-art results, showing that a detailed taxonomy in a hierarchical multi-label setting can yield competitive classification performance. However, all models hit a glass ceiling at approximately 80% F1 score, which we attribute to the non-discrete nature of web registers and the inherent uncertainty in labeling some documents. By pruning ambiguous examples, we improve model performance to over 90%. Finally, multilingual models outperform monolingual ones, particularly benefiting languages with fewer training examples and smaller registers. Although a zero-shot setting decreases performance by an average of 7%, these drops are not linked to specific registers or languages. Instead, registers show surprising similarity across languages.
Beyond the English Web: Zero-Shot Cross-Lingual and Lightweight Monolingual Classification of Registers
Feb 15, 2021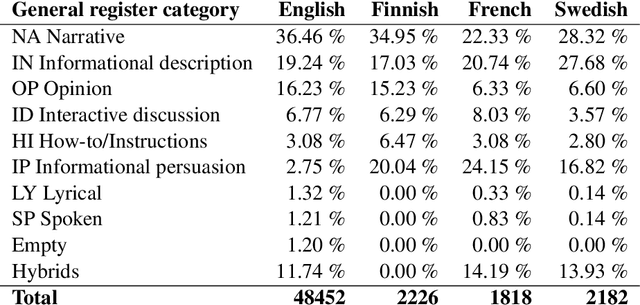
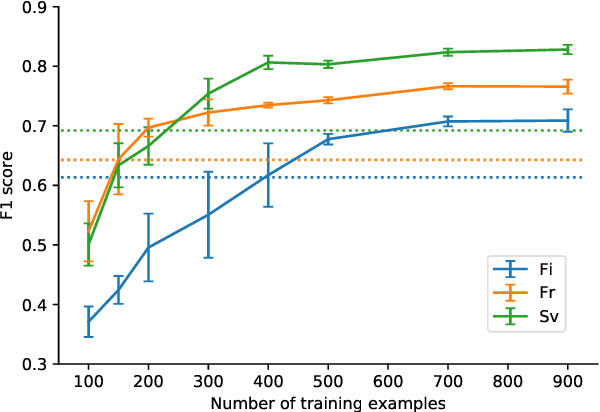
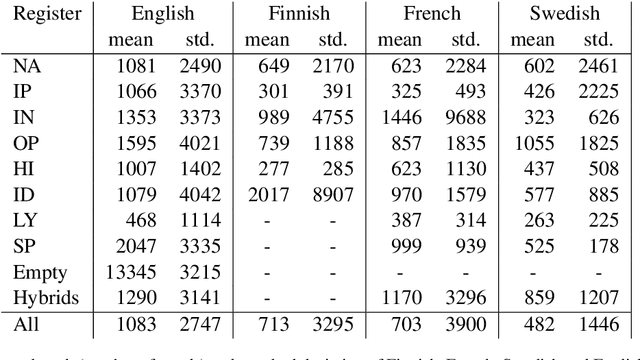
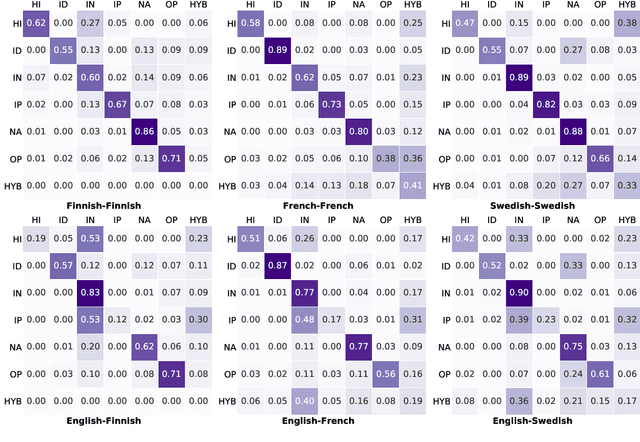
We explore cross-lingual transfer of register classification for web documents. Registers, that is, text varieties such as blogs or news are one of the primary predictors of linguistic variation and thus affect the automatic processing of language. We introduce two new register annotated corpora, FreCORE and SweCORE, for French and Swedish. We demonstrate that deep pre-trained language models perform strongly in these languages and outperform previous state-of-the-art in English and Finnish. Specifically, we show 1) that zero-shot cross-lingual transfer from the large English CORE corpus can match or surpass previously published monolingual models, and 2) that lightweight monolingual classification requiring very little training data can reach or surpass our zero-shot performance. We further analyse classification results finding that certain registers continue to pose challenges in particular for cross-lingual transfer.