 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegister Always Matters: Analysis of LLM Pretraining Data Through the Lens of Language Variation
Apr 02, 2025Pretraining data curation is a cornerstone in Large Language Model (LLM) development, leading to growing research on quality filtering of large web corpora. From statistical quality flags to LLM-based labeling systems, datasets are divided into categories, frequently reducing to a binary: those passing the filters deemed as valuable examples, others discarded as useless or detrimental. However, a more detailed understanding of the contribution of different kinds of texts to model performance is still largely lacking. In this article, we present the first study utilizing registers (also known as genres) - a widely used standard in corpus linguistics to model linguistic variation - to curate pretraining datasets and investigate the effect of register on the performance of LLMs. We perform comparative studies by training models with register classified data and evaluating them using standard benchmarks, and show that the register of pretraining data substantially affects model performance. We uncover surprising relationships between the pretraining material and the resulting models: using the News register results in subpar performance, and on the contrary, including the Opinion class, covering texts such as reviews and opinion blogs, is highly beneficial. While a model trained on the entire unfiltered dataset outperforms those trained on datasets limited to a single register, combining well-performing registers like How-to-Instructions, Informational Description, and Opinion leads to major improvements. Furthermore, analysis of individual benchmark results reveals key differences in the strengths and drawbacks of specific register classes as pretraining data. These findings show that register is an important explainer of model variation and can facilitate more deliberate future data selection practices.
Untangling the Unrestricted Web: Automatic Identification of Multilingual Registers
Jun 28, 2024This article explores deep learning models for the automatic identification of registers - text varieties such as news reports and discussion forums - in web-based datasets across 16 languages. Web register (or genre) identification would provide a robust solution for understanding the content of web-scale datasets, which have become crucial in computational linguistics. Despite recent advances, the potential of register classifiers on the noisy web remains largely unexplored, particularly in multilingual settings and when targeting the entire unrestricted web. We experiment with a range of deep learning models using the new Multilingual CORE corpora, which includes 16 languages annotated using a detailed, hierarchical taxonomy of 25 registers designed to cover the entire unrestricted web. Our models achieve state-of-the-art results, showing that a detailed taxonomy in a hierarchical multi-label setting can yield competitive classification performance. However, all models hit a glass ceiling at approximately 80% F1 score, which we attribute to the non-discrete nature of web registers and the inherent uncertainty in labeling some documents. By pruning ambiguous examples, we improve model performance to over 90%. Finally, multilingual models outperform monolingual ones, particularly benefiting languages with fewer training examples and smaller registers. Although a zero-shot setting decreases performance by an average of 7%, these drops are not linked to specific registers or languages. Instead, registers show surprising similarity across languages.
Explaining Classes through Word Attribution
Aug 31, 2021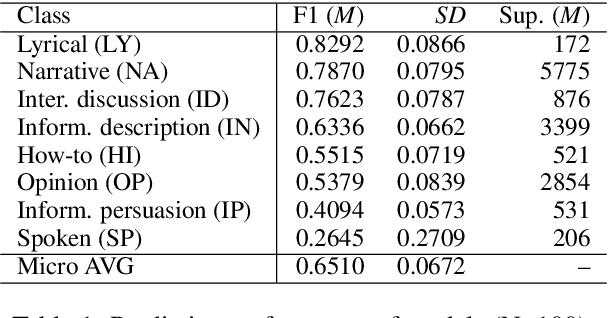
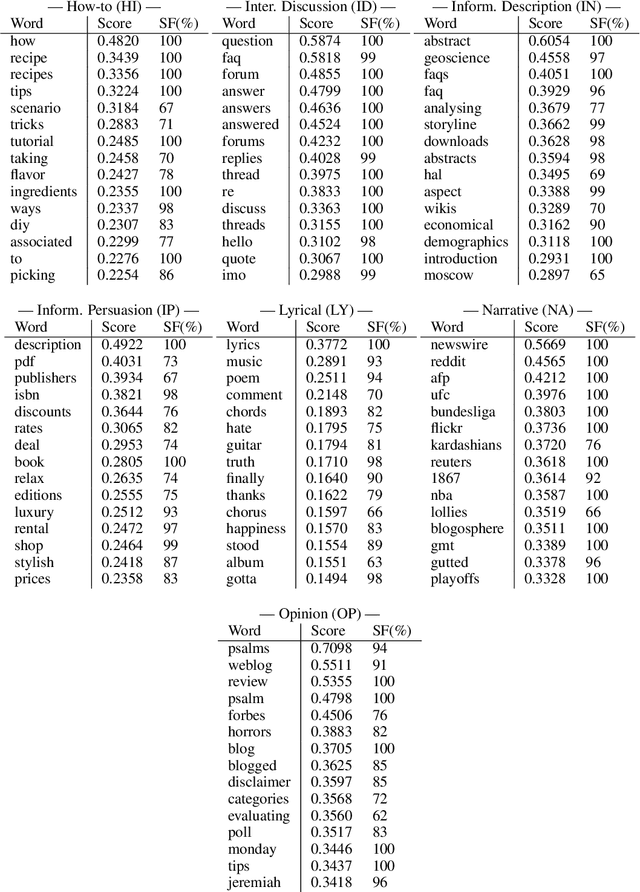
In recent years, several methods have been proposed for explaining individual predictions of deep learning models, yet there has been little study of how to aggregate these predictions to explain how such models view classes as a whole in text classification tasks. In this work, we propose a method for explaining classes using deep learning models and the Integrated Gradients feature attribution technique by aggregating explanations of individual examples in text classification to general descriptions of the classes. We demonstrate the approach on Web register (genre) classification using the XML-R model and the Corpus of Online Registers of English (CORE), finding that the method identifies plausible and discriminative keywords characterizing all but the smallest class.