 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Search as Extractive Paraphrase Span Detection
Dec 09, 2021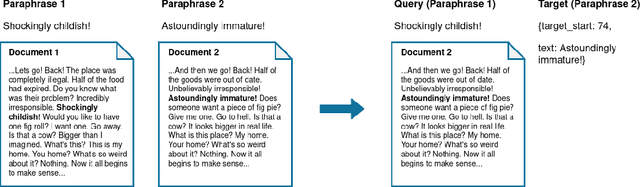
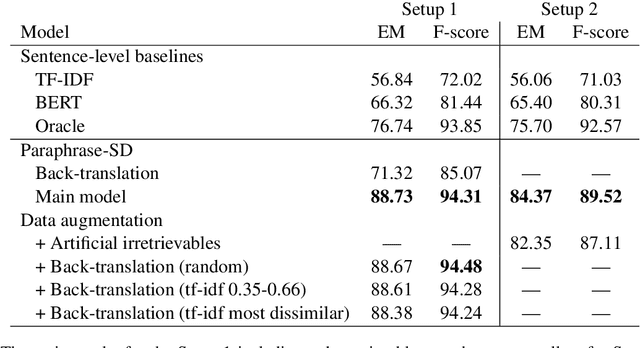
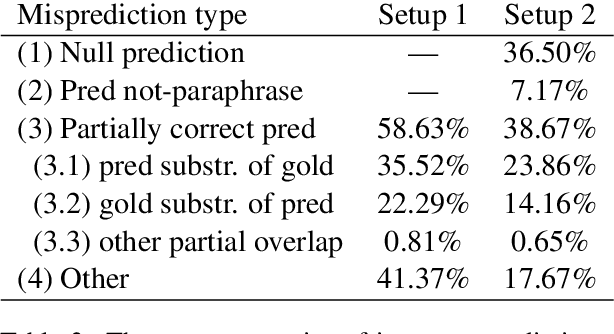
In this paper, we approach the problem of semantic search by framing the search task as paraphrase span detection, i.e. given a segment of text as a query phrase, the task is to identify its paraphrase in a given document, the same modelling setup as typically used in extractive question answering. On the Turku Paraphrase Corpus of 100,000 manually extracted Finnish paraphrase pairs including their original document context, we find that our paraphrase span detection model outperforms two strong retrieval baselines (lexical similarity and BERT sentence embeddings) by 31.9pp and 22.4pp respectively in terms of exact match, and by 22.3pp and 12.9pp in terms of token-level F-score. This demonstrates a strong advantage of modelling the task in terms of span retrieval, rather than sentence similarity. Additionally, we introduce a method for creating artificial paraphrase data through back-translation, suitable for languages where manually annotated paraphrase resources for training the span detection model are not available.
Annotation Guidelines for the Turku Paraphrase Corpus
Aug 19, 2021This document describes the annotation guidelines used to construct the Turku Paraphrase Corpus. These guidelines were developed together with the corpus annotation, revising and extending the guidelines regularly during the annotation work. Our paraphrase annotation scheme uses the base scale 1-4, where labels 1 and 2 are used for negative candidates (not paraphrases), while labels 3 and 4 are paraphrases at least in the given context if not everywhere. In addition to base labeling, the scheme is enriched with additional subcategories (flags) for categorizing different types of paraphrases inside the two positive labels, making the annotation scheme suitable for more fine-grained paraphrase categorization. The annotation scheme is used to annotate over 100,000 Finnish paraphrase pairs.
Quantitative Evaluation of Alternative Translations in a Corpus of Highly Dissimilar Finnish Paraphrases
May 06, 2021
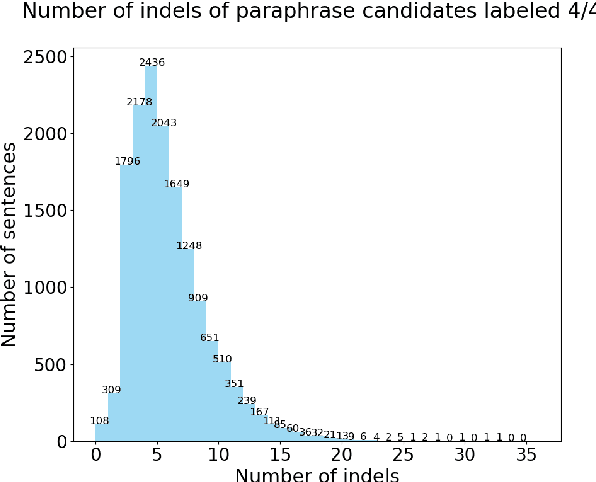
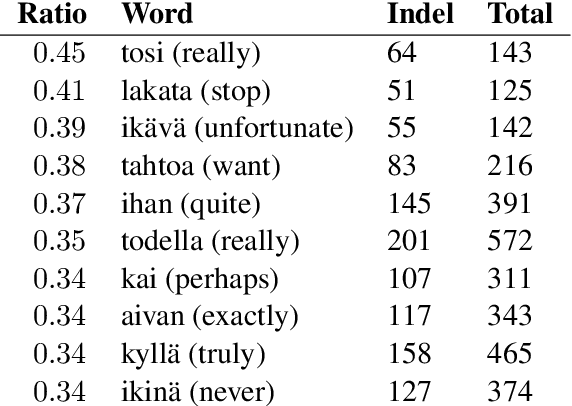

In this paper, we present a quantitative evaluation of differences between alternative translations in a large recently released Finnish paraphrase corpus focusing in particular on non-trivial variation in translation. We combine a series of automatic steps detecting systematic variation with manual analysis to reveal regularities and identify categories of translation differences. We find the paraphrase corpus to contain highly non-trivial translation variants difficult to recognize through automatic approaches.
Deep learning for sentence clustering in essay grading support
Apr 23, 2021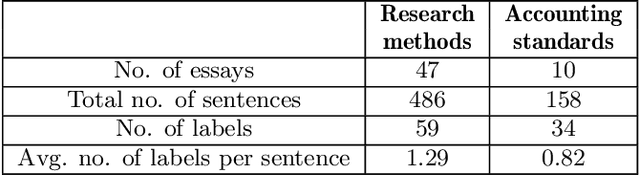
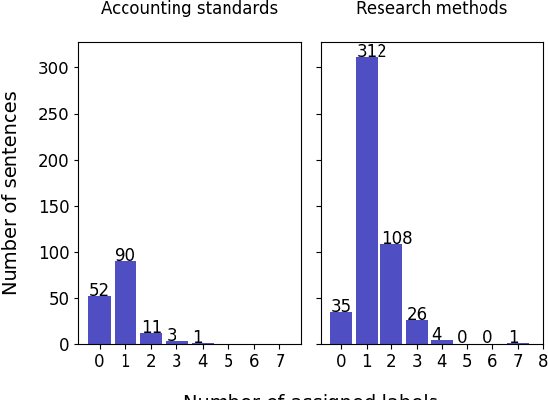

Essays as a form of assessment test student knowledge on a deeper level than short answer and multiple-choice questions. However, the manual evaluation of essays is time- and labor-consuming. Automatic clustering of essays, or their fragments, prior to manual evaluation presents a possible solution to reducing the effort required in the evaluation process. Such clustering presents numerous challenges due to the variability and ambiguity of natural language. In this paper, we introduce two datasets of undergraduate student essays in Finnish, manually annotated for salient arguments on the sentence level. Using these datasets, we evaluate several deep-learning embedding methods for their suitability to sentence clustering in support of essay grading. We find that the choice of the most suitable method depends on the nature of the exam question and the answers, with deep-learning methods being capable of, but not guaranteeing better performance over simpler methods based on lexical overlap.
Finnish Paraphrase Corpus
Mar 24, 2021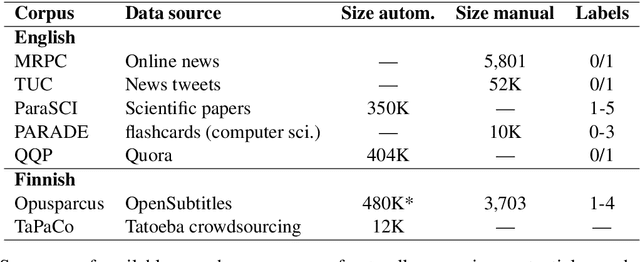
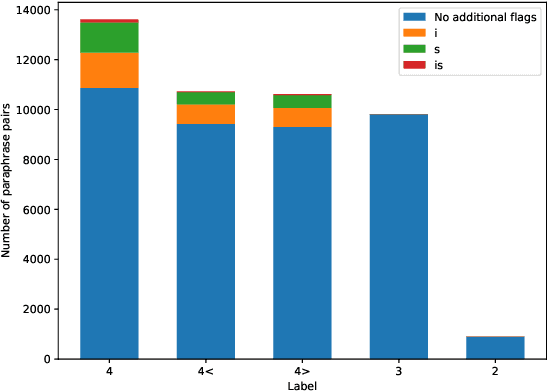

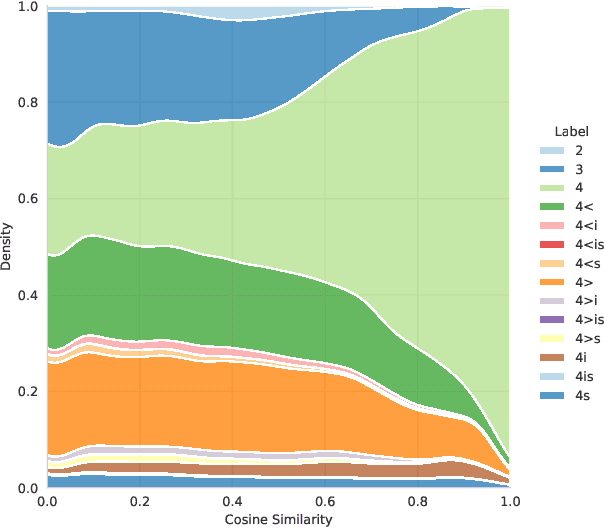
In this paper, we introduce the first fully manually annotated paraphrase corpus for Finnish containing 53,572 paraphrase pairs harvested from alternative subtitles and news headings. Out of all paraphrase pairs in our corpus 98% are manually classified to be paraphrases at least in their given context, if not in all contexts. Additionally, we establish a manual candidate selection method and demonstrate its feasibility in high quality paraphrase selection in terms of both cost and quality.
Towards Fully Bilingual Deep Language Modeling
Oct 22, 2020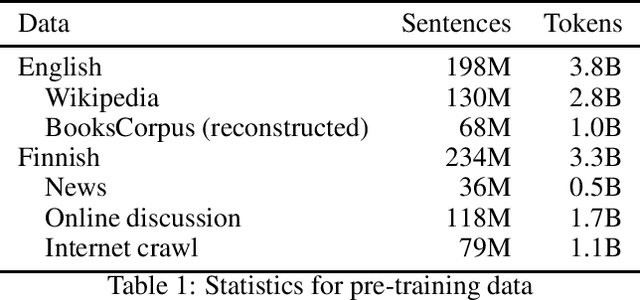


Language models based on deep neural networks have facilitated great advances in natural language processing and understanding tasks in recent years. While models covering a large number of languages have been introduced, their multilinguality has come at a cost in terms of monolingual performance, and the best-performing models at most tasks not involving cross-lingual transfer remain monolingual. In this paper, we consider the question of whether it is possible to pre-train a bilingual model for two remotely related languages without compromising performance at either language. We collect pre-training data, create a Finnish-English bilingual BERT model and evaluate its performance on datasets used to evaluate the corresponding monolingual models. Our bilingual model performs on par with Google's original English BERT on GLUE and nearly matches the performance of monolingual Finnish BERT on a range of Finnish NLP tasks, clearly outperforming multilingual BERT. We find that when the model vocabulary size is increased, the BERT-Base architecture has sufficient capacity to learn two remotely related languages to a level where it achieves comparable performance with monolingual models, demonstrating the feasibility of training fully bilingual deep language models. The model and all tools involved in its creation are freely available at https://github.com/TurkuNLP/biBERT