 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning for sentence clustering in essay grading support
Paper and Code
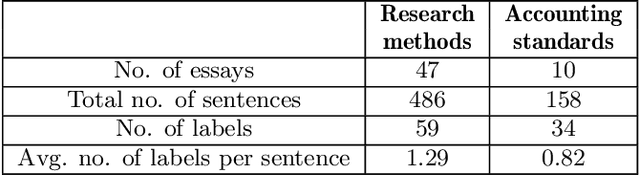
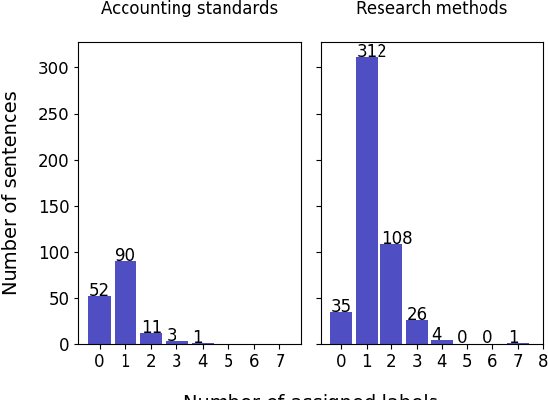

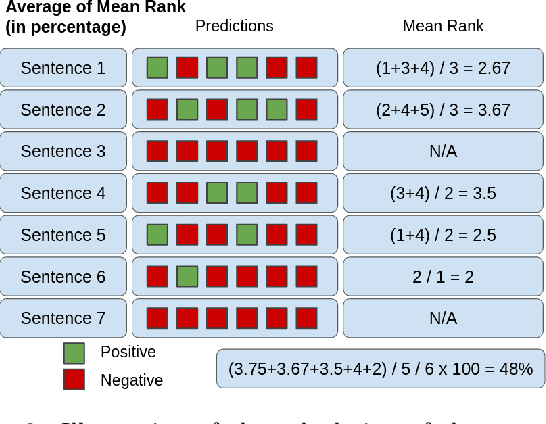
Essays as a form of assessment test student knowledge on a deeper level than short answer and multiple-choice questions. However, the manual evaluation of essays is time- and labor-consuming. Automatic clustering of essays, or their fragments, prior to manual evaluation presents a possible solution to reducing the effort required in the evaluation process. Such clustering presents numerous challenges due to the variability and ambiguity of natural language. In this paper, we introduce two datasets of undergraduate student essays in Finnish, manually annotated for salient arguments on the sentence level. Using these datasets, we evaluate several deep-learning embedding methods for their suitability to sentence clustering in support of essay grading. We find that the choice of the most suitable method depends on the nature of the exam question and the answers, with deep-learning methods being capable of, but not guaranteeing better performance over simpler methods based on lexical overlap.