 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHopes and Fears -- Emotion Distribution in the Topic Landscape of Finnish Parliamentary Speech 2000-2020
Jan 28, 2026Existing research often treats parliamentary discourse as a homogeneous whole, overlooking topic-specific patterns. Parliamentary speeches address a wide range of topics, some of which evoke stronger emotions than others. While everyone has intuitive assumptions about what the most emotive topics in a parliament may be, there has been little research into the emotions typically linked to different topics. This paper strives to fill this gap by examining emotion expression among the topics of parliamentary speeches delivered in Eduskunta, the Finnish Parliament, between 2000 and 2020. An emotion analysis model is used to investigate emotion expression in topics, from both synchronic and diachronic perspectives. The results strengthen evidence of increasing positivity in parliamentary speech and provide further insights into topic-specific emotion expression within parliamentary debate.
FinerWeb-10BT: Refining Web Data with LLM-Based Line-Level Filtering
Jan 13, 2025Data quality is crucial for training Large Language Models (LLMs). Traditional heuristic filters often miss low-quality text or mistakenly remove valuable content. In this paper, we introduce an LLM-based line-level filtering method to enhance training data quality. We use GPT-4o mini to label a 20,000-document sample from FineWeb at the line level, allowing the model to create descriptive labels for low-quality lines. These labels are grouped into nine main categories, and we train a DeBERTa-v3 classifier to scale the filtering to a 10B-token subset of FineWeb. To test the impact of our filtering, we train GPT-2 models on both the original and the filtered datasets. The results show that models trained on the filtered data achieve higher accuracy on the HellaSwag benchmark and reach their performance targets faster, even with up to 25\% less data. This demonstrates that LLM-based line-level filtering can significantly improve data quality and training efficiency for LLMs. We release our quality-annotated dataset, FinerWeb-10BT, and the codebase to support further work in this area.
Annotation Guidelines for the Turku Paraphrase Corpus
Aug 19, 2021This document describes the annotation guidelines used to construct the Turku Paraphrase Corpus. These guidelines were developed together with the corpus annotation, revising and extending the guidelines regularly during the annotation work. Our paraphrase annotation scheme uses the base scale 1-4, where labels 1 and 2 are used for negative candidates (not paraphrases), while labels 3 and 4 are paraphrases at least in the given context if not everywhere. In addition to base labeling, the scheme is enriched with additional subcategories (flags) for categorizing different types of paraphrases inside the two positive labels, making the annotation scheme suitable for more fine-grained paraphrase categorization. The annotation scheme is used to annotate over 100,000 Finnish paraphrase pairs.
Finnish Paraphrase Corpus
Mar 24, 2021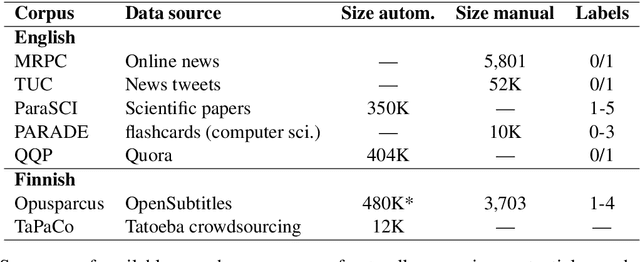
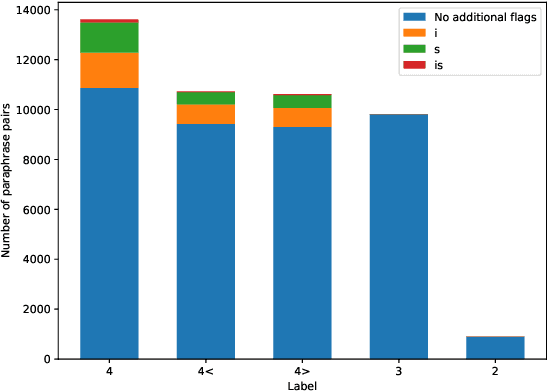

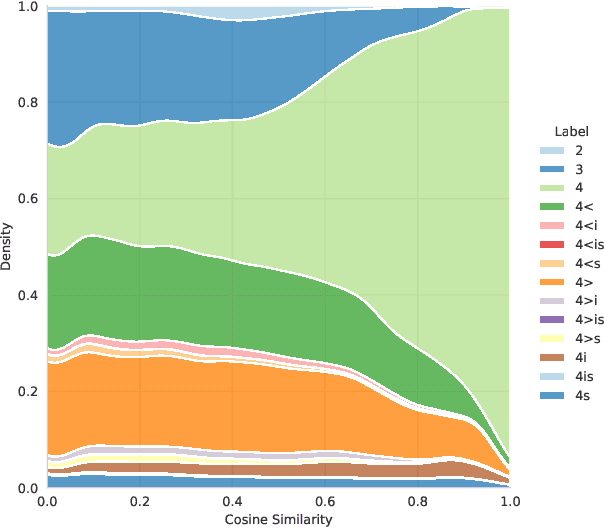
In this paper, we introduce the first fully manually annotated paraphrase corpus for Finnish containing 53,572 paraphrase pairs harvested from alternative subtitles and news headings. Out of all paraphrase pairs in our corpus 98% are manually classified to be paraphrases at least in their given context, if not in all contexts. Additionally, we establish a manual candidate selection method and demonstrate its feasibility in high quality paraphrase selection in terms of both cost and quality.