 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Low-Resource MT via Synthetic Data Generation with LLMs
May 20, 2025



We investigate the potential of LLM-generated synthetic data for improving low-resource machine translation (MT). Focusing on seven diverse target languages, we construct a document-level synthetic corpus from English Europarl, and extend it via pivoting to 147 additional language pairs. Automatic and human evaluation confirm its high overall quality. We study its practical application by (i) identifying effective training regimes, (ii) comparing our data with the HPLT dataset, and (iii) testing its utility beyond English-centric MT. Finally, we introduce SynOPUS, a public repository for synthetic parallel datasets. Our findings show that LLM-generated synthetic data, even when noisy, can substantially improve MT performance for low-resource languages.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
SemEval-2024 Shared Task 6: SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes
Mar 20, 2024


This paper presents the results of the SHROOM, a shared task focused on detecting hallucinations: outputs from natural language generation (NLG) systems that are fluent, yet inaccurate. Such cases of overgeneration put in jeopardy many NLG applications, where correctness is often mission-critical. The shared task was conducted with a newly constructed dataset of 4000 model outputs labeled by 5 annotators each, spanning 3 NLP tasks: machine translation, paraphrase generation and definition modeling. The shared task was tackled by a total of 58 different users grouped in 42 teams, out of which 27 elected to write a system description paper; collectively, they submitted over 300 prediction sets on both tracks of the shared task. We observe a number of key trends in how this approach was tackled -- many participants rely on a handful of model, and often rely either on synthetic data for fine-tuning or zero-shot prompting strategies. While a majority of the teams did outperform our proposed baseline system, the performances of top-scoring systems are still consistent with a random handling of the more challenging items.
Semantic Search as Extractive Paraphrase Span Detection
Dec 09, 2021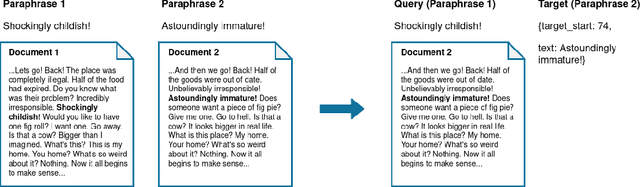
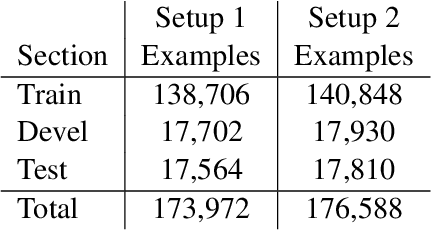
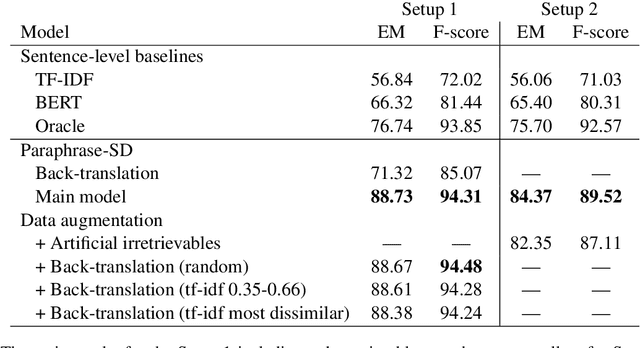
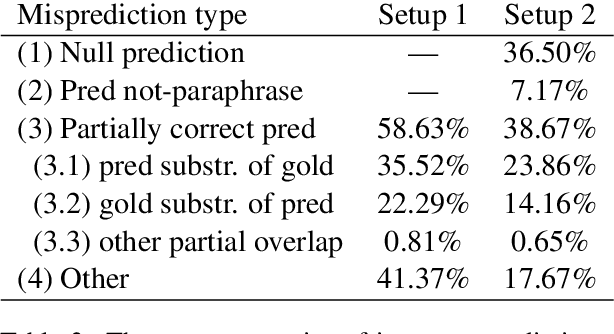
In this paper, we approach the problem of semantic search by framing the search task as paraphrase span detection, i.e. given a segment of text as a query phrase, the task is to identify its paraphrase in a given document, the same modelling setup as typically used in extractive question answering. On the Turku Paraphrase Corpus of 100,000 manually extracted Finnish paraphrase pairs including their original document context, we find that our paraphrase span detection model outperforms two strong retrieval baselines (lexical similarity and BERT sentence embeddings) by 31.9pp and 22.4pp respectively in terms of exact match, and by 22.3pp and 12.9pp in terms of token-level F-score. This demonstrates a strong advantage of modelling the task in terms of span retrieval, rather than sentence similarity. Additionally, we introduce a method for creating artificial paraphrase data through back-translation, suitable for languages where manually annotated paraphrase resources for training the span detection model are not available.
Grammatical Error Generation Based on Translated Fragments
Apr 20, 2021

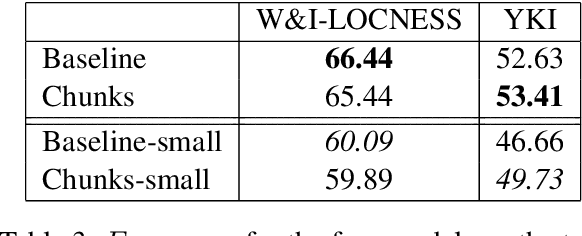
We perform neural machine translation of sentence fragments in order to create large amounts of training data for English grammatical error correction. Our method aims at simulating mistakes made by second language learners, and produces a wider range of non-native style language in comparison to state-of-the-art synthetic data creation methods. In addition to purely grammatical errors, our approach generates other types of errors, such as lexical errors. We perform grammatical error correction experiments using neural sequence-to-sequence models, and carry out quantitative and qualitative evaluation. A model trained on data created using our proposed method is shown to outperform a baseline model on test data with a high proportion of errors.