 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Low-Resource MT via Synthetic Data Generation with LLMs
May 20, 2025



We investigate the potential of LLM-generated synthetic data for improving low-resource machine translation (MT). Focusing on seven diverse target languages, we construct a document-level synthetic corpus from English Europarl, and extend it via pivoting to 147 additional language pairs. Automatic and human evaluation confirm its high overall quality. We study its practical application by (i) identifying effective training regimes, (ii) comparing our data with the HPLT dataset, and (iii) testing its utility beyond English-centric MT. Finally, we introduce SynOPUS, a public repository for synthetic parallel datasets. Our findings show that LLM-generated synthetic data, even when noisy, can substantially improve MT performance for low-resource languages.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
A New Massive Multilingual Dataset for High-Performance Language Technologies
Mar 20, 2024We present the HPLT (High Performance Language Technologies) language resources, a new massive multilingual dataset including both monolingual and bilingual corpora extracted from CommonCrawl and previously unused web crawls from the Internet Archive. We describe our methods for data acquisition, management and processing of large corpora, which rely on open-source software tools and high-performance computing. Our monolingual collection focuses on low- to medium-resourced languages and covers 75 languages and a total of ~5.6 trillion word tokens de-duplicated on the document level. Our English-centric parallel corpus is derived from its monolingual counterpart and covers 18 language pairs and more than 96 million aligned sentence pairs with roughly 1.4 billion English tokens. The HPLT language resources are one of the largest open text corpora ever released, providing a great resource for language modeling and machine translation training. We publicly release the corpora, the software, and the tools used in this work.
OpusCleaner and OpusTrainer, open source toolkits for training Machine Translation and Large language models
Nov 24, 2023Developing high quality machine translation systems is a labour intensive, challenging and confusing process for newcomers to the field. We present a pair of tools OpusCleaner and OpusTrainer that aim to simplify the process, reduce the amount of work and lower the entry barrier for newcomers. OpusCleaner is a data downloading, cleaning, and proprocessing toolkit. It is designed to allow researchers to quickly download, visualise and preprocess bilingual (or monolingual) data that comes from many different sources, each of them with different quality, issues, and unique filtering/preprocessing requirements. OpusTrainer is a data scheduling and data augmenting tool aimed at building large scale, robust machine translation systems and large language models. It features deterministic data mixing from many different sources, on-the-fly data augmentation and more. Using these tools, we showcase how we can use it to create high quality machine translation model robust to noisy user input; multilingual models and terminology aware models.
Democratizing Machine Translation with OPUS-MT
Dec 04, 2022This paper presents the OPUS ecosystem with a focus on the development of open machine translation models and tools, and their integration into end-user applications, development platforms and professional workflows. We discuss our on-going mission of increasing language coverage and translation quality, and also describe on-going work on the development of modular translation models and speed-optimized compact solutions for real-time translation on regular desktops and small devices.
Paraphrase Detection on Noisy Subtitles in Six Languages
Sep 21, 2018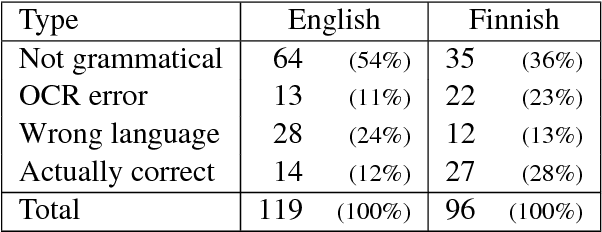
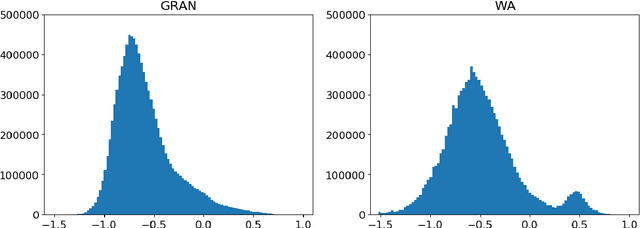
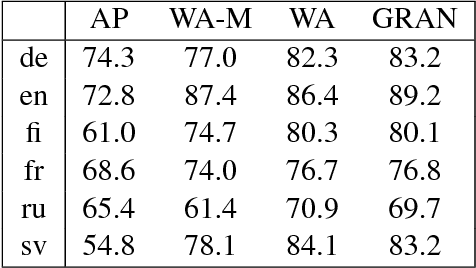
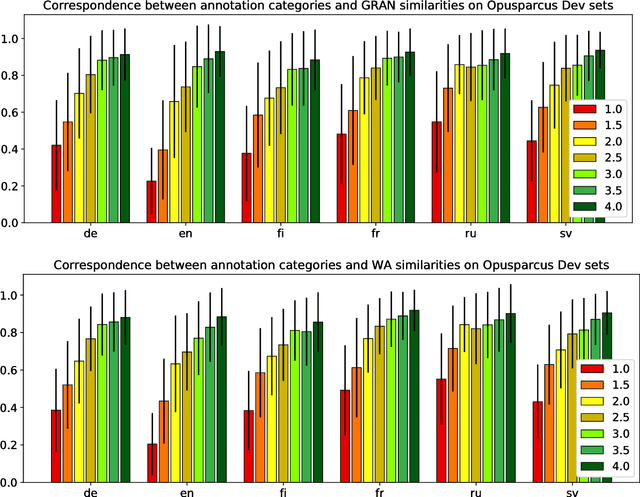
We perform automatic paraphrase detection on subtitle data from the Opusparcus corpus comprising six European languages: German, English, Finnish, French, Russian, and Swedish. We train two types of supervised sentence embedding models: a word-averaging (WA) model and a gated recurrent averaging network (GRAN) model. We find out that GRAN outperforms WA and is more robust to noisy training data. Better results are obtained with more and noisier data than less and cleaner data. Additionally, we experiment on other datasets, without reaching the same level of performance, because of domain mismatch between training and test data.