 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenLID-v3: Improving the Precision of Closely Related Language Identification -- An Experience Report
Feb 13, 2026Language identification (LID) is an essential step in building high-quality multilingual datasets from web data. Existing LID tools (such as OpenLID or GlotLID) often struggle to identify closely related languages and to distinguish valid natural language from noise, which contaminates language-specific subsets, especially for low-resource languages. In this work we extend the OpenLID classifier by adding more training data, merging problematic language variant clusters, and introducing a special label for marking noise. We call this extended system OpenLID-v3 and evaluate it against GlotLID on multiple benchmarks. During development, we focus on three groups of closely related languages (Bosnian, Croatian, and Serbian; Romance varieties of Northern Italy and Southern France; and Scandinavian languages) and contribute new evaluation datasets where existing ones are inadequate. We find that ensemble approaches improve precision but also substantially reduce coverage for low-resource languages. OpenLID-v3 is available on https://huggingface.co/HPLT/OpenLID-v3.
Multi-label Scandinavian Language Identification (SLIDE)
Feb 10, 2025



Identifying closely related languages at sentence level is difficult, in particular because it is often impossible to assign a sentence to a single language. In this paper, we focus on multi-label sentence-level Scandinavian language identification (LID) for Danish, Norwegian Bokm\r{a}l, Norwegian Nynorsk, and Swedish. We present the Scandinavian Language Identification and Evaluation, SLIDE, a manually curated multi-label evaluation dataset and a suite of LID models with varying speed-accuracy tradeoffs. We demonstrate that the ability to identify multiple languages simultaneously is necessary for any accurate LID method, and present a novel approach to training such multi-label LID models.
Definition generation for lexical semantic change detection
Jun 20, 2024



We use contextualized word definitions generated by large language models as semantic representations in the task of diachronic lexical semantic change detection (LSCD). In short, generated definitions are used as `senses', and the change score of a target word is retrieved by comparing their distributions in two time periods under comparison. On the material of five datasets and three languages, we show that generated definitions are indeed specific and general enough to convey a signal sufficient to rank sets of words by the degree of their semantic change over time. Our approach is on par with or outperforms prior non-supervised sense-based LSCD methods. At the same time, it preserves interpretability and allows to inspect the reasons behind a specific shift in terms of discrete definitions-as-senses. This is another step in the direction of explainable semantic change modeling.
Explainability of Machine Learning Approaches in Forensic Linguistics: A Case Study in Geolinguistic Authorship Profiling
Apr 29, 2024Forensic authorship profiling uses linguistic markers to infer characteristics about an author of a text. This task is paralleled in dialect classification, where a prediction is made about the linguistic variety of a text based on the text itself. While there have been significant advances in the last years in variety classification (Jauhiainen et al., 2019) and state-of-the-art approaches reach accuracies of up to 100% depending on the similarity of varieties and the scope of prediction (e.g., Milne et al., 2012; Blodgett et al., 2017), forensic linguistics rarely relies on these approaches due to their lack of transparency (see Nini, 2023), amongst other reasons. In this paper we therefore explore explainability of machine learning approaches considering the forensic context. We focus on variety classification as a means of geolinguistic profiling of unknown texts. For this we work with an approach proposed by Xie et al. (2024) to extract the lexical items most relevant to the variety classifications. We find that the extracted lexical features are indeed representative of their respective varieties and note that the trained models also rely on place names for classifications.
Findings of the VarDial Evaluation Campaign 2023
May 31, 2023This report presents the results of the shared tasks organized as part of the VarDial Evaluation Campaign 2023. The campaign is part of the tenth workshop on Natural Language Processing (NLP) for Similar Languages, Varieties and Dialects (VarDial), co-located with EACL 2023. Three separate shared tasks were included this year: Slot and intent detection for low-resource language varieties (SID4LR), Discriminating Between Similar Languages -- True Labels (DSL-TL), and Discriminating Between Similar Languages -- Speech (DSL-S). All three tasks were organized for the first time this year.
Democratizing Machine Translation with OPUS-MT
Dec 04, 2022This paper presents the OPUS ecosystem with a focus on the development of open machine translation models and tools, and their integration into end-user applications, development platforms and professional workflows. We discuss our on-going mission of increasing language coverage and translation quality, and also describe on-going work on the development of modular translation models and speed-optimized compact solutions for real-time translation on regular desktops and small devices.
Fixed Encoder Self-Attention Patterns in Transformer-Based Machine Translation
Feb 24, 2020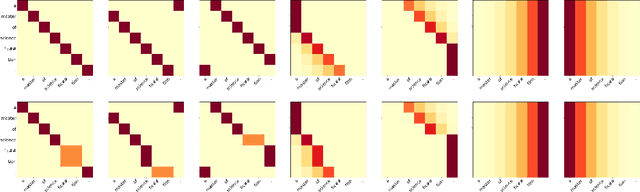

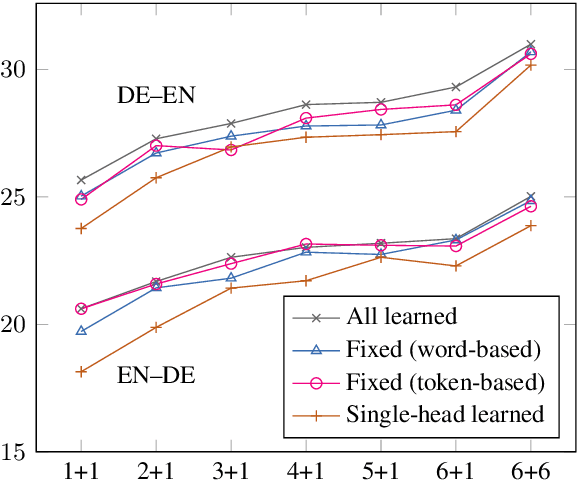

Transformer-based models have brought a radical change to neural machine translation. A key feature of the Transformer architecture is the so-called multi-head attention mechanism, which allows the model to focus simultaneously on different parts of the input. However, recent works have shown that attention heads learn simple positional patterns which are often redundant. In this paper, we propose to replace all but one attention head of each encoder layer with fixed -- non-learnable -- attentive patterns that are solely based on position and do not require any external knowledge. Our experiments show that fixing the attention heads on the encoder side of the Transformer at training time does not impact the translation quality and even increases BLEU scores by up to 3 points in low-resource scenarios.
The University of Helsinki submissions to the WMT19 news translation task
Jun 10, 2019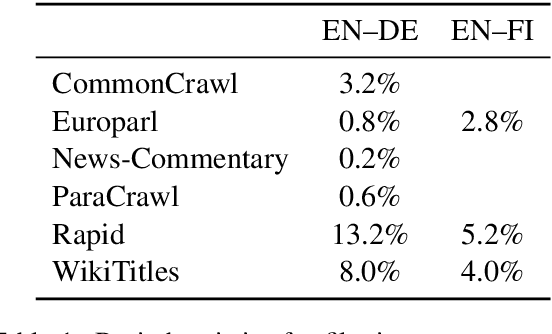
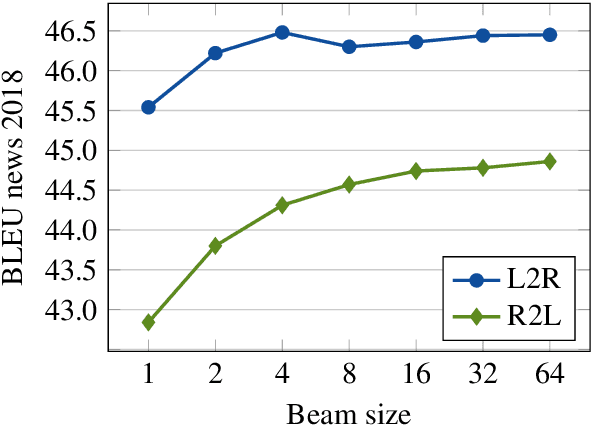

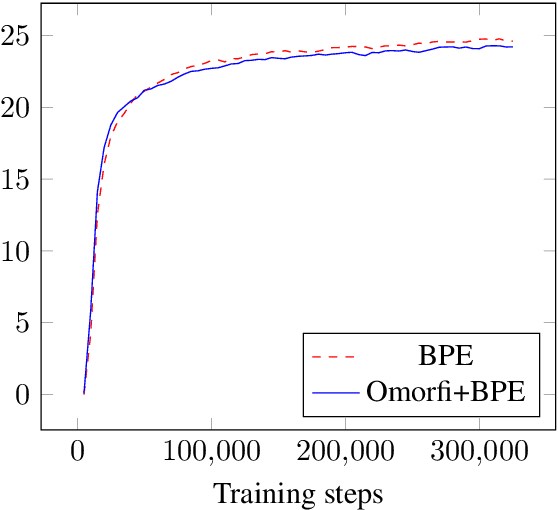
In this paper, we present the University of Helsinki submissions to the WMT 2019 shared task on news translation in three language pairs: English-German, English-Finnish and Finnish-English. This year, we focused first on cleaning and filtering the training data using multiple data-filtering approaches, resulting in much smaller and cleaner training sets. For English-German, we trained both sentence-level transformer models and compared different document-level translation approaches. For Finnish-English and English-Finnish we focused on different segmentation approaches, and we also included a rule-based system for English-Finnish.
Translational Grounding: Using Paraphrase Recognition and Generation to Demonstrate Semantic Abstraction Abilities of MultiLingual NMT
Aug 21, 2018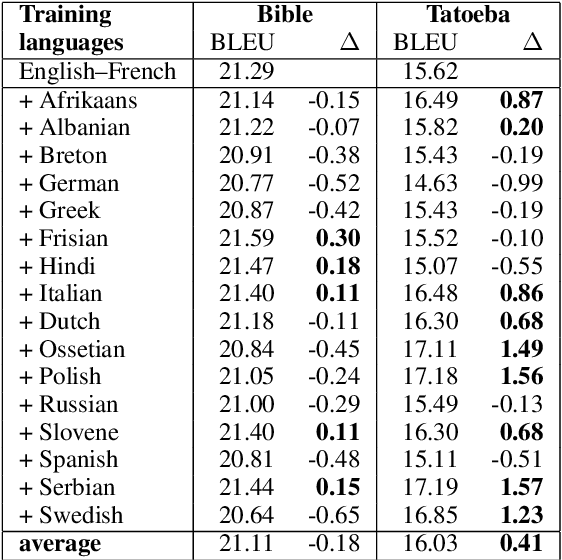
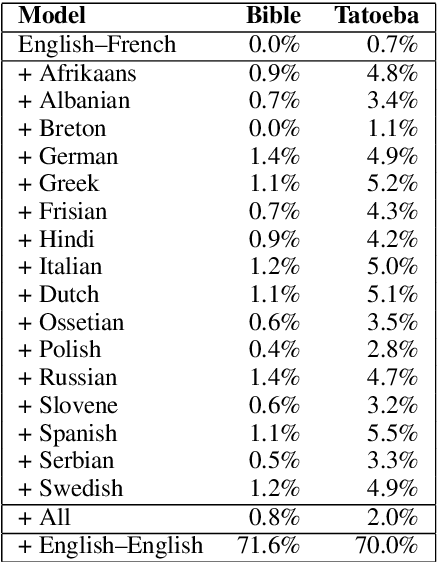
In this paper, we investigate whether multilingual neural translation models learn a stronger semantic abstraction of sentences than bilingual ones. We test this hypotheses by measuring the perplexity of such models when applied to paraphrases of the source language. The intuition is that an encoder produces better representations if a decoder is capable of recognizing synonymous sentences in the same language even though the model is never trained for that task. In our setup, we add 16 different auxiliary languages to a bidirectional bilingual baseline model (English-French) and test it with in-domain and out-of-domain paraphrases in English. The results show that the perplexity is significantly reduced in each of the cases, indicating that meaning can be grounded in translation. This is further supported by a study on paraphrase generation that we also include at the end of the paper.
Neural Machine Translation with Extended Context
Aug 20, 2017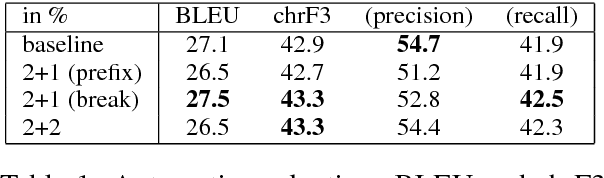
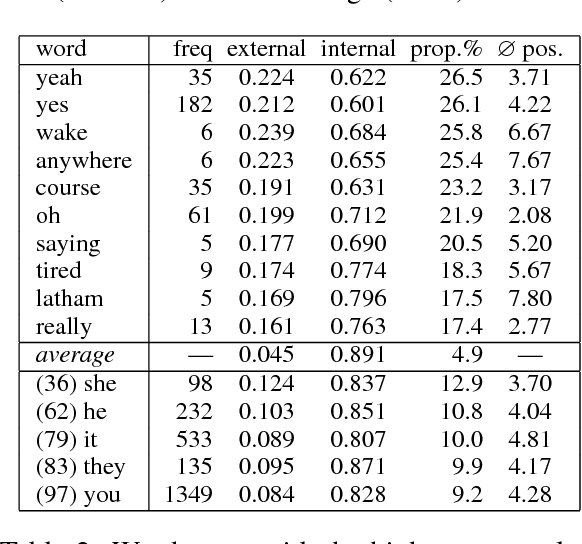

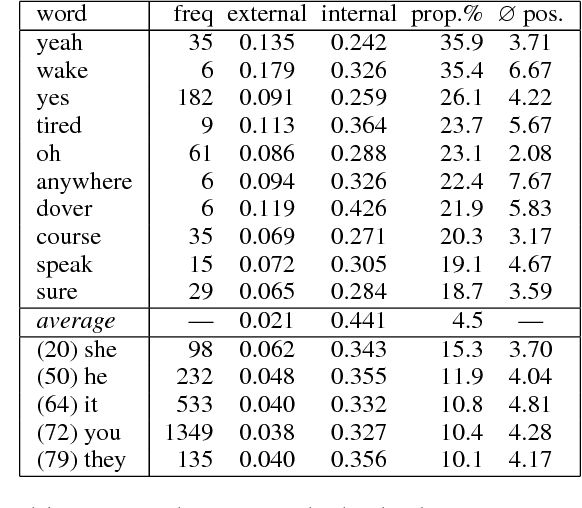
We investigate the use of extended context in attention-based neural machine translation. We base our experiments on translated movie subtitles and discuss the effect of increasing the segments beyond single translation units. We study the use of extended source language context as well as bilingual context extensions. The models learn to distinguish between information from different segments and are surprisingly robust with respect to translation quality. In this pilot study, we observe interesting cross-sentential attention patterns that improve textual coherence in translation at least in some selected cases.