 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Bias under Conflicting Information in Multilingual LLMs
Apr 08, 2026Large Language Models (LLMs) have been shown to contain biases in the process of integrating conflicting information when answering questions. Here we ask whether such biases also exist with respect to which language is used for each conflicting piece of information. To answer this question, we extend the conflicting needles in a haystack paradigm to a multilingual setting and perform a comprehensive set of evaluations with naturalistic news domain data in five different languages, for a range of multilingual LLMs of different sizes. We find that all LLMs tested, including GPT-5.2, ignore the conflict and confidently assert only one of the possible answers in the large majority of cases. Furthermore, there is a consistent bias across models in which languages are preferred, with a general bias against Russian and, for the longest context lengths, in favor of Chinese. Both of these patterns are consistent between models trained inside and outside of mainland China, though somewhat stronger in the former category.
Evaluation of really good grammatical error correction
Aug 17, 2023
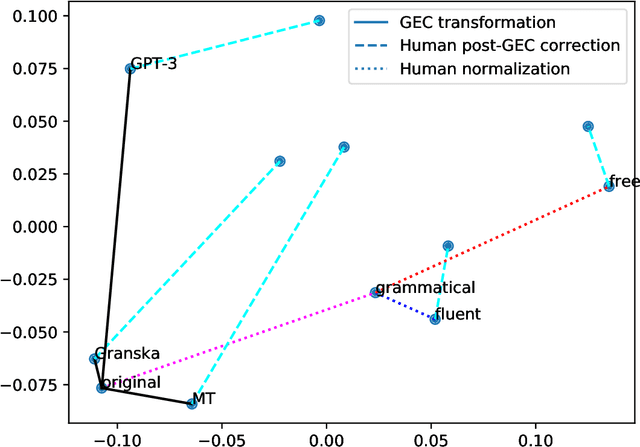

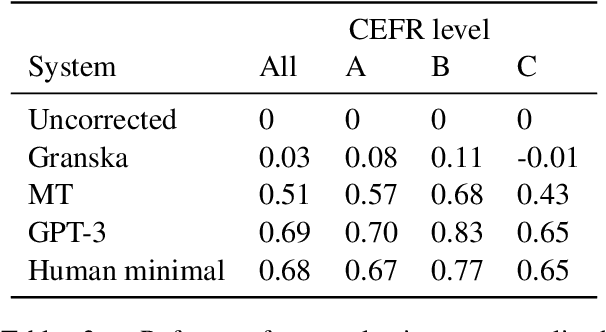
Although rarely stated, in practice, Grammatical Error Correction (GEC) encompasses various models with distinct objectives, ranging from grammatical error detection to improving fluency. Traditional evaluation methods fail to fully capture the full range of system capabilities and objectives. Reference-based evaluations suffer from limitations in capturing the wide variety of possible correction and the biases introduced during reference creation and is prone to favor fixing local errors over overall text improvement. The emergence of large language models (LLMs) has further highlighted the shortcomings of these evaluation strategies, emphasizing the need for a paradigm shift in evaluation methodology. In the current study, we perform a comprehensive evaluation of various GEC systems using a recently published dataset of Swedish learner texts. The evaluation is performed using established evaluation metrics as well as human judges. We find that GPT-3 in a few-shot setting by far outperforms previous grammatical error correction systems for Swedish, a language comprising only 0.11% of its training data. We also found that current evaluation methods contain undesirable biases that a human evaluation is able to reveal. We suggest using human post-editing of GEC system outputs to analyze the amount of change required to reach native-level human performance on the task, and provide a dataset annotated with human post-edits and assessments of grammaticality, fluency and meaning preservation of GEC system outputs.
Language Embeddings Sometimes Contain Typological Generalizations
Jan 19, 2023To what extent can neural network models learn generalizations about language structure, and how do we find out what they have learned? We explore these questions by training neural models for a range of natural language processing tasks on a massively multilingual dataset of Bible translations in 1295 languages. The learned language representations are then compared to existing typological databases as well as to a novel set of quantitative syntactic and morphological features obtained through annotation projection. We conclude that some generalizations are surprisingly close to traditional features from linguistic typology, but that most of our models, as well as those of previous work, do not appear to have made linguistically meaningful generalizations. Careful attention to details in the evaluation turns out to be essential to avoid false positives. Furthermore, to encourage continued work in this field, we release several resources covering most or all of the languages in our data: (i) multiple sets of language representations, (ii) multilingual word embeddings, (iii) projected and predicted syntactic and morphological features, (iv) software to provide linguistically sound evaluations of language representations.
Probing Multilingual Language Models for Discourse
Jun 09, 2021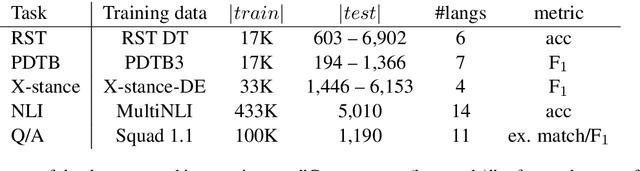



Pre-trained multilingual language models have become an important building block in multilingual natural language processing. In the present paper, we investigate a range of such models to find out how well they transfer discourse-level knowledge across languages. This is done with a systematic evaluation on a broader set of discourse-level tasks than has been previously been assembled. We find that the XLM-RoBERTa family of models consistently show the best performance, by simultaneously being good monolingual models and degrading relatively little in a zero-shot setting. Our results also indicate that model distillation may hurt the ability of cross-lingual transfer of sentence representations, while language dissimilarity at most has a modest effect. We hope that our test suite, covering 5 tasks with a total of 22 languages in 10 distinct families, will serve as a useful evaluation platform for multilingual performance at and beyond the sentence level.
Let's be explicit about that: Distant supervision for implicit discourse relation classification via connective prediction
Jun 06, 2021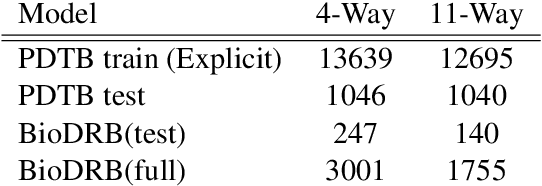
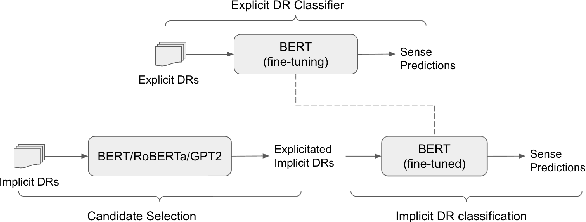

In implicit discourse relation classification, we want to predict the relation between adjacent sentences in the absence of any overt discourse connectives. This is challenging even for humans, leading to shortage of annotated data, a fact that makes the task even more difficult for supervised machine learning approaches. In the current study, we perform implicit discourse relation classification without relying on any labeled implicit relation. We sidestep the lack of data through explicitation of implicit relations to reduce the task to two sub-problems: language modeling and explicit discourse relation classification, a much easier problem. Our experimental results show that this method can even marginally outperform the state-of-the-art, in spite of being much simpler than alternative models of comparable performance. Moreover, we show that the achieved performance is robust across domains as suggested by the zero-shot experiments on a completely different domain. This indicates that recent advances in language modeling have made language models sufficiently good at capturing inter-sentence relations without the help of explicit discourse markers.
Zero-shot transfer for implicit discourse relation classification
Jul 30, 2019
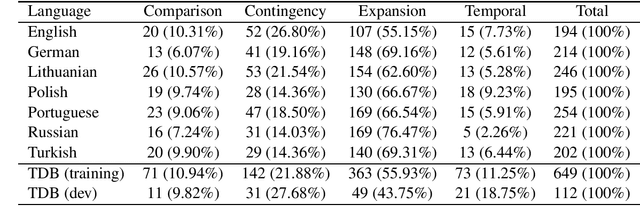

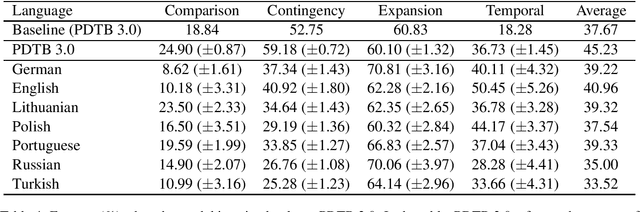
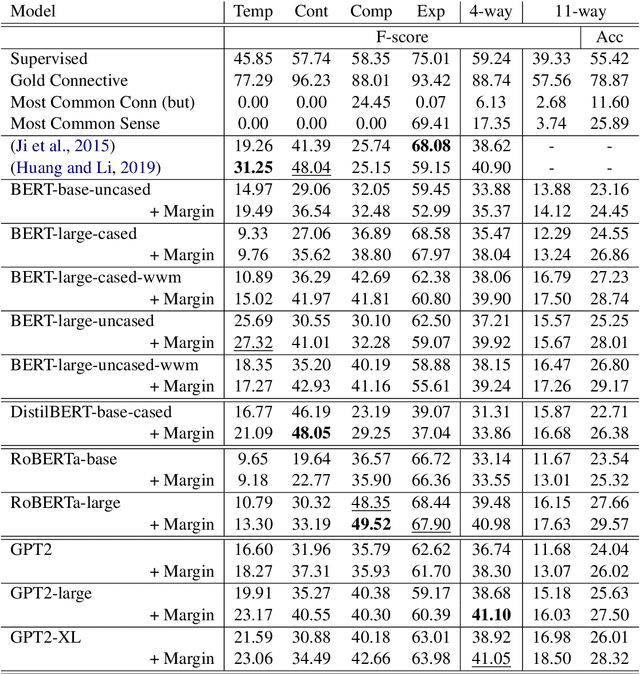
Automatically classifying the relation between sentences in a discourse is a challenging task, in particular when there is no overt expression of the relation. It becomes even more challenging by the fact that annotated training data exists only for a small number of languages, such as English and Chinese. We present a new system using zero-shot transfer learning for implicit discourse relation classification, where the only resource used for the target language is unannotated parallel text. This system is evaluated on the discourse-annotated TED-MDB parallel corpus, where it obtains good results for all seven languages using only English training data.
What do Language Representations Really Represent?
Jan 09, 2019A neural language model trained on a text corpus can be used to induce distributed representations of words, such that similar words end up with similar representations. If the corpus is multilingual, the same model can be used to learn distributed representations of languages, such that similar languages end up with similar representations. We show that this holds even when the multilingual corpus has been translated into English, by picking up the faint signal left by the source languages. However, just like it is a thorny problem to separate semantic from syntactic similarity in word representations, it is not obvious what type of similarity is captured by language representations. We investigate correlations and causal relationships between language representations learned from translations on one hand, and genetic, geographical, and several levels of structural similarity between languages on the other. Of these, structural similarity is found to correlate most strongly with language representation similarity, while genetic relationships---a convenient benchmark used for evaluation in previous work---appears to be a confounding factor. Apart from implications about translation effects, we see this more generally as a case where NLP and linguistic typology can interact and benefit one another.
Articulation rate in Swedish child-directed speech increases as a function of the age of the child even when surprisal is controlled for
Nov 24, 2017
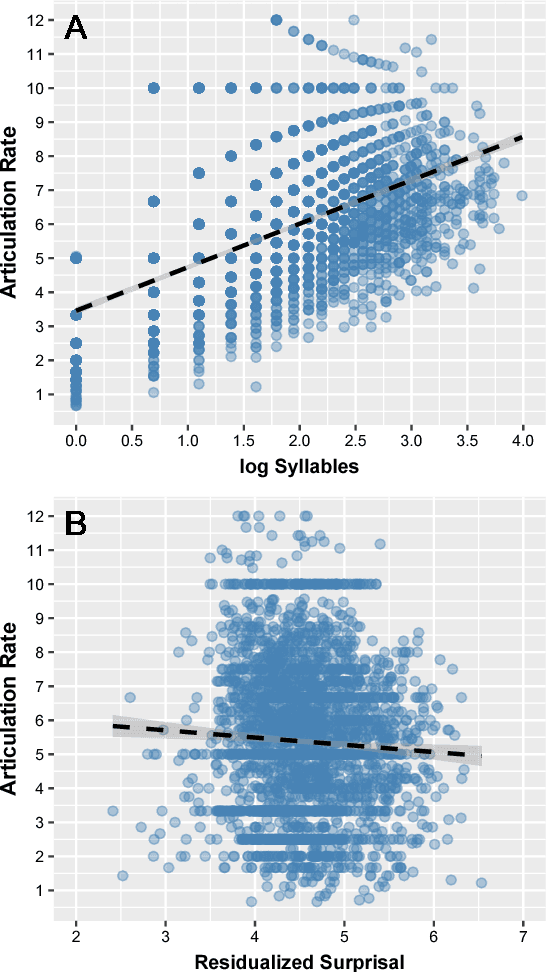
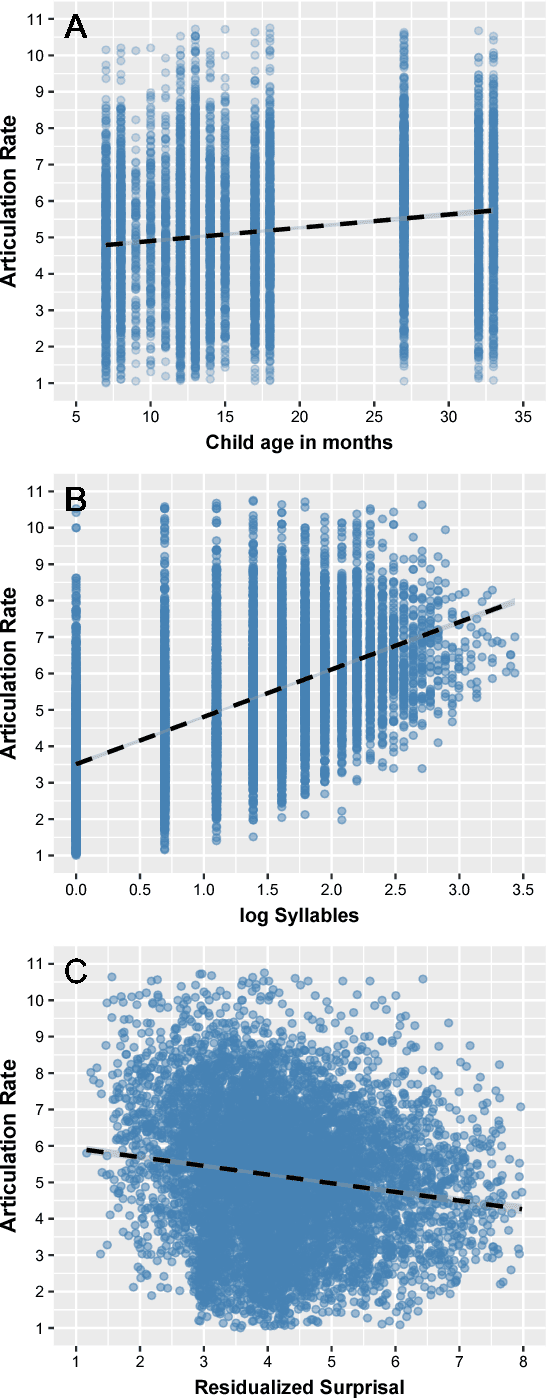
In earlier work, we have shown that articulation rate in Swedish child-directed speech (CDS) increases as a function of the age of the child, even when utterance length and differences in articulation rate between subjects are controlled for. In this paper we show on utterance level in spontaneous Swedish speech that i) for the youngest children, articulation rate in CDS is lower than in adult-directed speech (ADS), ii) there is a significant negative correlation between articulation rate and surprisal (the negative log probability) in ADS, and iii) the increase in articulation rate in Swedish CDS as a function of the age of the child holds, even when surprisal along with utterance length and differences in articulation rate between speakers are controlled for. These results indicate that adults adjust their articulation rate to make it fit the linguistic capacity of the child.
The Helsinki Neural Machine Translation System
Aug 20, 2017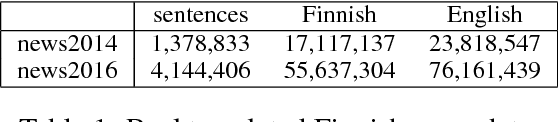
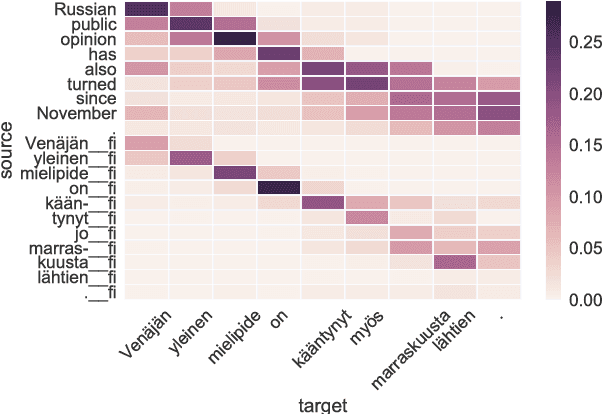
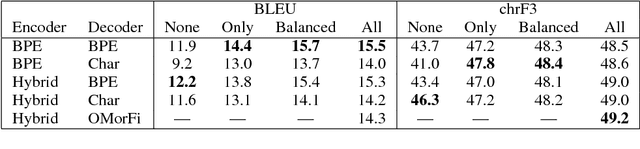
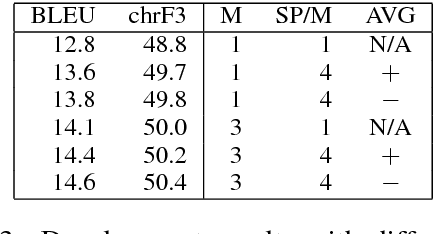
We introduce the Helsinki Neural Machine Translation system (HNMT) and how it is applied in the news translation task at WMT 2017, where it ranked first in both the human and automatic evaluations for English--Finnish. We discuss the success of English--Finnish translations and the overall advantage of NMT over a strong SMT baseline. We also discuss our submissions for English--Latvian, English--Chinese and Chinese--English.
Neural machine translation for low-resource languages
Aug 18, 2017

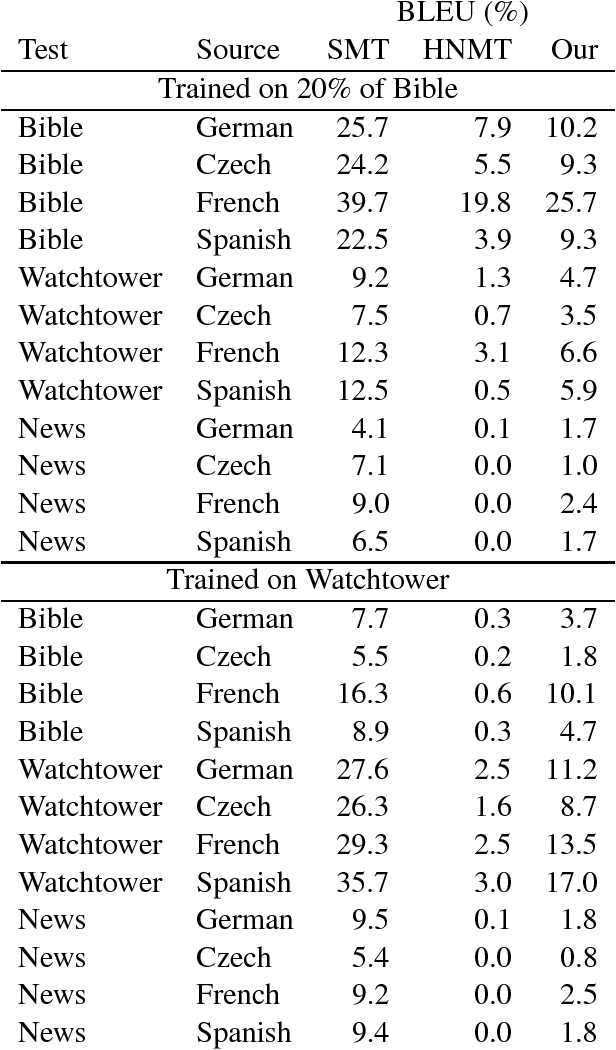
Neural machine translation (NMT) approaches have improved the state of the art in many machine translation settings over the last couple of years, but they require large amounts of training data to produce sensible output. We demonstrate that NMT can be used for low-resource languages as well, by introducing more local dependencies and using word alignments to learn sentence reordering during translation. In addition to our novel model, we also present an empirical evaluation of low-resource phrase-based statistical machine translation (SMT) and NMT to investigate the lower limits of the respective technologies. We find that while SMT remains the best option for low-resource settings, our method can produce acceptable translations with only 70000 tokens of training data, a level where the baseline NMT system fails completely.