Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot transfer for implicit discourse relation classification
Paper and Code

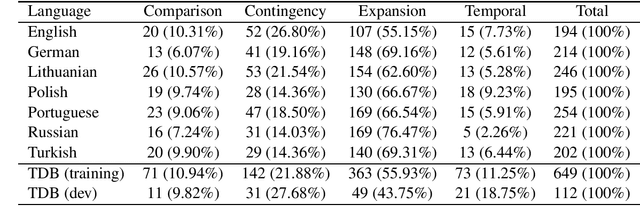

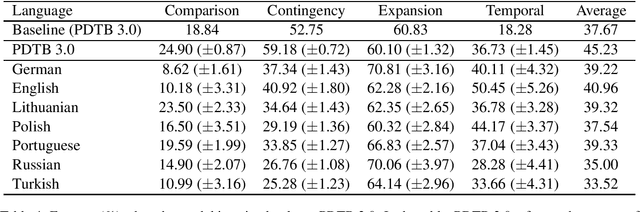
Automatically classifying the relation between sentences in a discourse is a challenging task, in particular when there is no overt expression of the relation. It becomes even more challenging by the fact that annotated training data exists only for a small number of languages, such as English and Chinese. We present a new system using zero-shot transfer learning for implicit discourse relation classification, where the only resource used for the target language is unannotated parallel text. This system is evaluated on the discourse-annotated TED-MDB parallel corpus, where it obtains good results for all seven languages using only English training data.
* to be presented at SIGDIAL 2019
View paper on