 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of really good grammatical error correction
Paper and Code

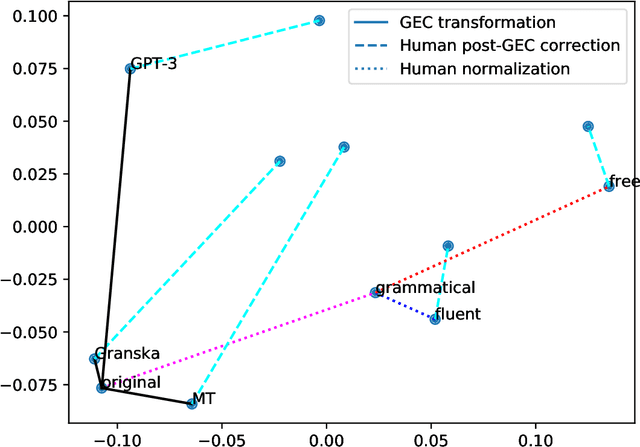

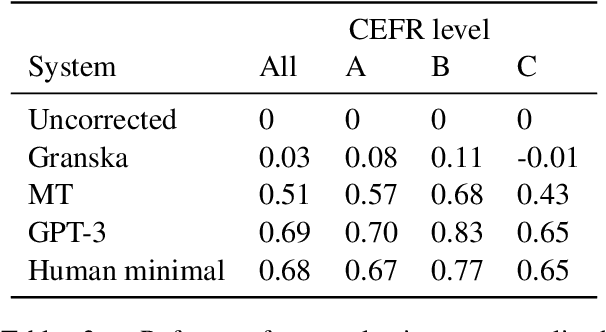
Although rarely stated, in practice, Grammatical Error Correction (GEC) encompasses various models with distinct objectives, ranging from grammatical error detection to improving fluency. Traditional evaluation methods fail to fully capture the full range of system capabilities and objectives. Reference-based evaluations suffer from limitations in capturing the wide variety of possible correction and the biases introduced during reference creation and is prone to favor fixing local errors over overall text improvement. The emergence of large language models (LLMs) has further highlighted the shortcomings of these evaluation strategies, emphasizing the need for a paradigm shift in evaluation methodology. In the current study, we perform a comprehensive evaluation of various GEC systems using a recently published dataset of Swedish learner texts. The evaluation is performed using established evaluation metrics as well as human judges. We find that GPT-3 in a few-shot setting by far outperforms previous grammatical error correction systems for Swedish, a language comprising only 0.11% of its training data. We also found that current evaluation methods contain undesirable biases that a human evaluation is able to reveal. We suggest using human post-editing of GEC system outputs to analyze the amount of change required to reach native-level human performance on the task, and provide a dataset annotated with human post-edits and assessments of grammaticality, fluency and meaning preservation of GEC system outputs.