 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel-Smoothed Scores for Denoising Diffusion: A Bias-Variance Study
May 28, 2025Diffusion models now set the benchmark in high-fidelity generative sampling, yet they can, in principle, be prone to memorization. In this case, their learned score overfits the finite dataset so that the reverse-time SDE samples are mostly training points. In this paper, we interpret the empirical score as a noisy version of the true score and show that its covariance matrix is asymptotically a re-weighted data PCA. In large dimension, the small time limit makes the noise variance blow up while simultaneously reducing spatial correlation. To reduce this variance, we introduce a kernel-smoothed empirical score and analyze its bias-variance trade-off. We derive asymptotic bounds on the Kullback-Leibler divergence between the true distribution and the one generated by the modified reverse SDE. Regularization on the score has the same effect as increasing the size of the training dataset, and thus helps prevent memorization. A spectral decomposition of the forward diffusion suggests better variance control under some regularity conditions of the true data distribution. Reverse diffusion with kernel-smoothed empirical score can be reformulated as a gradient descent drifted toward a Log-Exponential Double-Kernel Density Estimator (LED-KDE). This perspective highlights two regularization mechanisms taking place in denoising diffusions: an initial Gaussian kernel first diffuses mass isotropically in the ambient space, while a second kernel applied in score space concentrates and spreads that mass along the data manifold. Hence, even a straightforward regularization-without any learning-already mitigates memorization and enhances generalization. Numerically, we illustrate our results with several experiments on synthetic and MNIST datasets.
An Interdisciplinary Outlook on Large Language Models for Scientific Research
Nov 03, 2023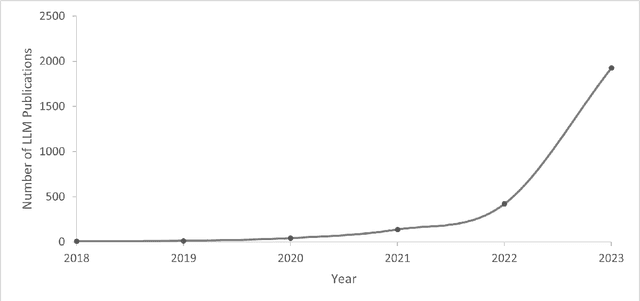
In this paper, we describe the capabilities and constraints of Large Language Models (LLMs) within disparate academic disciplines, aiming to delineate their strengths and limitations with precision. We examine how LLMs augment scientific inquiry, offering concrete examples such as accelerating literature review by summarizing vast numbers of publications, enhancing code development through automated syntax correction, and refining the scientific writing process. Simultaneously, we articulate the challenges LLMs face, including their reliance on extensive and sometimes biased datasets, and the potential ethical dilemmas stemming from their use. Our critical discussion extends to the varying impacts of LLMs across fields, from the natural sciences, where they help model complex biological sequences, to the social sciences, where they can parse large-scale qualitative data. We conclude by offering a nuanced perspective on how LLMs can be both a boon and a boundary to scientific progress.
Matryoshka Policy Gradient for Entropy-Regularized RL: Convergence and Global Optimality
Mar 22, 2023



A novel Policy Gradient (PG) algorithm, called Matryoshka Policy Gradient (MPG), is introduced and studied, in the context of max-entropy reinforcement learning, where an agent aims at maximising entropy bonuses additional to its cumulative rewards. MPG differs from standard PG in that it trains a sequence of policies to learn finite horizon tasks simultaneously, instead of a single policy for the single standard objective. For softmax policies, we prove convergence of MPG and global optimality of the limit by showing that the only critical point of the MPG objective is the optimal policy; these results hold true even in the case of continuous compact state space. MPG is intuitive, theoretically sound and we furthermore show that the optimal policy of the standard max-entropy objective can be approximated arbitrarily well by the optimal policy of the MPG framework. Finally, we justify that MPG is well suited when the policies are parametrized with neural networks and we provide an simple criterion to verify the global optimality of the policy at convergence. As a proof of concept, we evaluate numerically MPG on standard test benchmarks.
Reconstruction of the Density Power Spectrum from Quasar Spectra using Machine Learning
Jul 19, 2021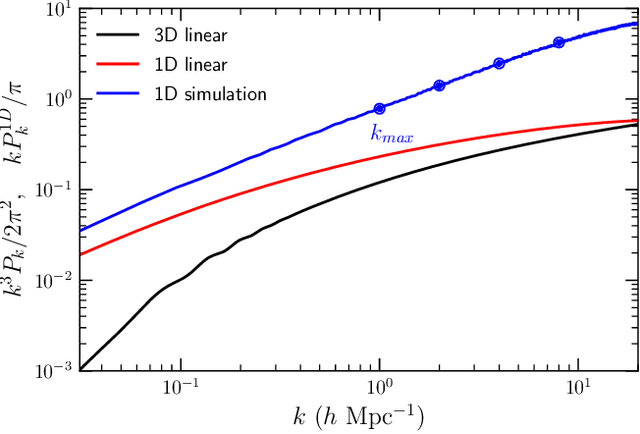

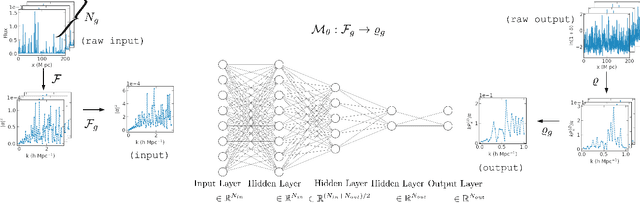
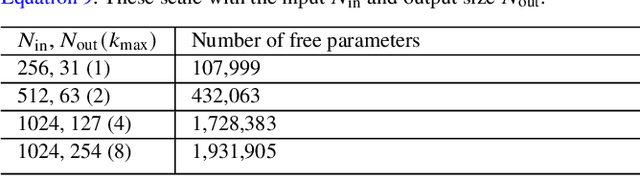
We describe a novel end-to-end approach using Machine Learning to reconstruct the power spectrum of cosmological density perturbations at high redshift from observed quasar spectra. State-of-the-art cosmological simulations of structure formation are used to generate a large synthetic dataset of line-of-sight absorption spectra paired with 1-dimensional fluid quantities along the same line-of-sight, such as the total density of matter and the density of neutral atomic hydrogen. With this dataset, we build a series of data-driven models to predict the power spectrum of total matter density. We are able to produce models which yield reconstruction to accuracy of about 1% for wavelengths $k \leq 2 h Mpc^{-1}$, while the error increases at larger $k$. We show the size of data sample required to reach a particular error rate, giving a sense of how much data is necessary to reach a desired accuracy. This work provides a foundation for developing methods to analyse very large upcoming datasets with the next-generation observational facilities.
What do Language Representations Really Represent?
Jan 09, 2019A neural language model trained on a text corpus can be used to induce distributed representations of words, such that similar words end up with similar representations. If the corpus is multilingual, the same model can be used to learn distributed representations of languages, such that similar languages end up with similar representations. We show that this holds even when the multilingual corpus has been translated into English, by picking up the faint signal left by the source languages. However, just like it is a thorny problem to separate semantic from syntactic similarity in word representations, it is not obvious what type of similarity is captured by language representations. We investigate correlations and causal relationships between language representations learned from translations on one hand, and genetic, geographical, and several levels of structural similarity between languages on the other. Of these, structural similarity is found to correlate most strongly with language representation similarity, while genetic relationships---a convenient benchmark used for evaluation in previous work---appears to be a confounding factor. Apart from implications about translation effects, we see this more generally as a case where NLP and linguistic typology can interact and benefit one another.