 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interdisciplinary Outlook on Large Language Models for Scientific Research
Nov 03, 2023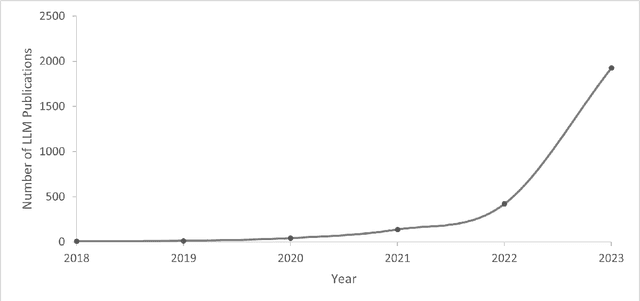
In this paper, we describe the capabilities and constraints of Large Language Models (LLMs) within disparate academic disciplines, aiming to delineate their strengths and limitations with precision. We examine how LLMs augment scientific inquiry, offering concrete examples such as accelerating literature review by summarizing vast numbers of publications, enhancing code development through automated syntax correction, and refining the scientific writing process. Simultaneously, we articulate the challenges LLMs face, including their reliance on extensive and sometimes biased datasets, and the potential ethical dilemmas stemming from their use. Our critical discussion extends to the varying impacts of LLMs across fields, from the natural sciences, where they help model complex biological sequences, to the social sciences, where they can parse large-scale qualitative data. We conclude by offering a nuanced perspective on how LLMs can be both a boon and a boundary to scientific progress.
Stochastic Deep Koopman Model for Quality Propagation Analysis in Multistage Manufacturing Systems
Sep 18, 2023



The modeling of multistage manufacturing systems (MMSs) has attracted increased attention from both academia and industry. Recent advancements in deep learning methods provide an opportunity to accomplish this task with reduced cost and expertise. This study introduces a stochastic deep Koopman (SDK) framework to model the complex behavior of MMSs. Specifically, we present a novel application of Koopman operators to propagate critical quality information extracted by variational autoencoders. Through this framework, we can effectively capture the general nonlinear evolution of product quality using a transferred linear representation, thus enhancing the interpretability of the data-driven model. To evaluate the performance of the SDK framework, we carried out a comparative study on an open-source dataset. The main findings of this paper are as follows. Our results indicate that SDK surpasses other popular data-driven models in accuracy when predicting stagewise product quality within the MMS. Furthermore, the unique linear propagation property in the stochastic latent space of SDK enables traceability for quality evolution throughout the process, thereby facilitating the design of root cause analysis schemes. Notably, the proposed framework requires minimal knowledge of the underlying physics of production lines. It serves as a virtual metrology tool that can be applied to various MMSs, contributing to the ultimate goal of Zero Defect Manufacturing.
Shapley-based Explainable AI for Clustering Applications in Fault Diagnosis and Prognosis
Mar 25, 2023Data-driven artificial intelligence models require explainability in intelligent manufacturing to streamline adoption and trust in modern industry. However, recently developed explainable artificial intelligence (XAI) techniques that estimate feature contributions on a model-agnostic level such as SHapley Additive exPlanations (SHAP) have not yet been evaluated for semi-supervised fault diagnosis and prognosis problems characterized by class imbalance and weakly labeled datasets. This paper explores the potential of utilizing Shapley values for a new clustering framework compatible with semi-supervised learning problems, loosening the strict supervision requirement of current XAI techniques. This broad methodology is validated on two case studies: a heatmap image dataset obtained from a semiconductor manufacturing process featuring class imbalance, and a benchmark dataset utilized in the 2021 Prognostics and Health Management (PHM) Data Challenge. Semi-supervised clustering based on Shapley values significantly improves upon clustering quality compared to the fully unsupervised case, deriving information-dense and meaningful clusters that relate to underlying fault diagnosis model predictions. These clusters can also be characterized by high-precision decision rules in terms of original feature values, as demonstrated in the second case study. The rules, limited to 1-2 terms utilizing original feature scales, describe 12 out of the 16 derived equipment failure clusters with precision exceeding 0.85, showcasing the promising utility of the explainable clustering framework for intelligent manufacturing applications.
Fault Prognosis of Turbofan Engines: Eventual Failure Prediction and Remaining Useful Life Estimation
Mar 23, 2023



In the era of industrial big data, prognostics and health management is essential to improve the prediction of future failures to minimize inventory, maintenance, and human costs. Used for the 2021 PHM Data Challenge, the new Commercial Modular Aero-Propulsion System Simulation dataset from NASA is an open-source benchmark containing simulated turbofan engine units flown under realistic flight conditions. Deep learning approaches implemented previously for this application attempt to predict the remaining useful life of the engine units, but have not utilized labeled failure mode information, impeding practical usage and explainability. To address these limitations, a new prognostics approach is formulated with a customized loss function to simultaneously predict the current health state, the eventual failing component(s), and the remaining useful life. The proposed method incorporates principal component analysis to orthogonalize statistical time-domain features, which are inputs into supervised regressors such as random forests, extreme random forests, XGBoost, and artificial neural networks. The highest performing algorithm, ANN-Flux, achieves AUROC and AUPR scores exceeding 0.95 for each classification. In addition, ANN-Flux reduces the remaining useful life RMSE by 38% for the same test split of the dataset compared to past work, with significantly less computational cost.