 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Koopman-based Control of Quality Variation in Multistage Manufacturing Systems
Jul 24, 2024This paper presents a modeling-control synthesis to address the quality control challenges in multistage manufacturing systems (MMSs). A new feedforward control scheme is developed to minimize the quality variations caused by process disturbances in MMSs. Notably, the control framework leverages a stochastic deep Koopman (SDK) model to capture the quality propagation mechanism in the MMSs, highlighted by its ability to transform the nonlinear propagation dynamics into a linear one. Two roll-to-roll case studies are presented to validate the proposed method and demonstrate its effectiveness. The overall method is suitable for nonlinear MMSs and does not require extensive expert knowledge.
Stochastic Deep Koopman Model for Quality Propagation Analysis in Multistage Manufacturing Systems
Sep 18, 2023



The modeling of multistage manufacturing systems (MMSs) has attracted increased attention from both academia and industry. Recent advancements in deep learning methods provide an opportunity to accomplish this task with reduced cost and expertise. This study introduces a stochastic deep Koopman (SDK) framework to model the complex behavior of MMSs. Specifically, we present a novel application of Koopman operators to propagate critical quality information extracted by variational autoencoders. Through this framework, we can effectively capture the general nonlinear evolution of product quality using a transferred linear representation, thus enhancing the interpretability of the data-driven model. To evaluate the performance of the SDK framework, we carried out a comparative study on an open-source dataset. The main findings of this paper are as follows. Our results indicate that SDK surpasses other popular data-driven models in accuracy when predicting stagewise product quality within the MMS. Furthermore, the unique linear propagation property in the stochastic latent space of SDK enables traceability for quality evolution throughout the process, thereby facilitating the design of root cause analysis schemes. Notably, the proposed framework requires minimal knowledge of the underlying physics of production lines. It serves as a virtual metrology tool that can be applied to various MMSs, contributing to the ultimate goal of Zero Defect Manufacturing.
Targeted collapse regularized autoencoder for anomaly detection: black hole at the center
Jun 22, 2023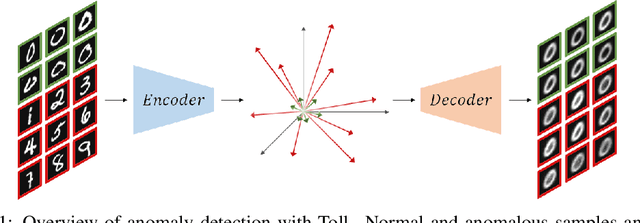
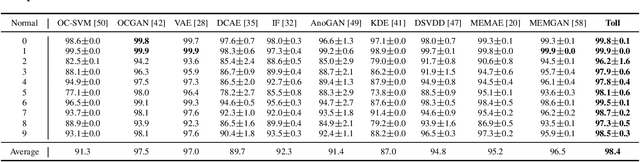

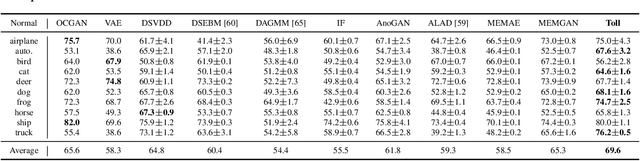
Autoencoders have been extensively used in the development of recent anomaly detection techniques. The premise of their application is based on the notion that after training the autoencoder on normal training data, anomalous inputs will exhibit a significant reconstruction error. Consequently, this enables a clear differentiation between normal and anomalous samples. In practice, however, it is observed that autoencoders can generalize beyond the normal class and achieve a small reconstruction error on some of the anomalous samples. To improve the performance, various techniques propose additional components and more sophisticated training procedures. In this work, we propose a remarkably straightforward alternative: instead of adding neural network components, involved computations, and cumbersome training, we complement the reconstruction loss with a computationally light term that regulates the norm of representations in the latent space. The simplicity of our approach minimizes the requirement for hyperparameter tuning and customization for new applications which, paired with its permissive data modality constraint, enhances the potential for successful adoption across a broad range of applications. We test the method on various visual and tabular benchmarks and demonstrate that the technique matches and frequently outperforms alternatives. We also provide a theoretical analysis and numerical simulations that help demonstrate the underlying process that unfolds during training and how it can help with anomaly detection. This mitigates the black-box nature of autoencoder-based anomaly detection algorithms and offers an avenue for further investigation of advantages, fail cases, and potential new directions.
A Novel Two-level Causal Inference Framework for On-road Vehicle Quality Issues Diagnosis
Mar 31, 2023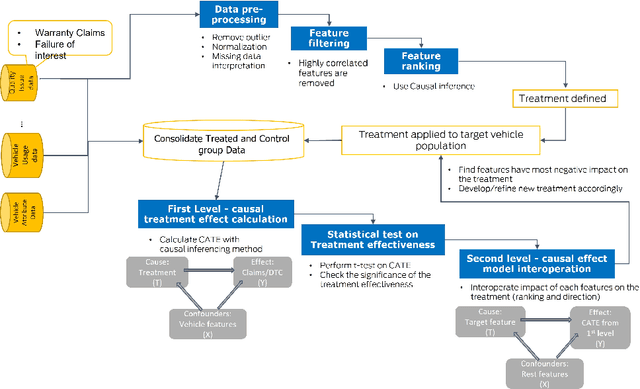

In the automotive industry, the full cycle of managing in-use vehicle quality issues can take weeks to investigate. The process involves isolating root causes, defining and implementing appropriate treatments, and refining treatments if needed. The main pain-point is the lack of a systematic method to identify causal relationships, evaluate treatment effectiveness, and direct the next actionable treatment if the current treatment was deemed ineffective. This paper will show how we leverage causal Machine Learning (ML) to speed up such processes. A real-word data set collected from on-road vehicles will be used to demonstrate the proposed framework. Open challenges for vehicle quality applications will also be discussed.
Towards Accurate and Robust Classification in Continuously Transitioning Industrial Sprays with Mixup
Jul 20, 2022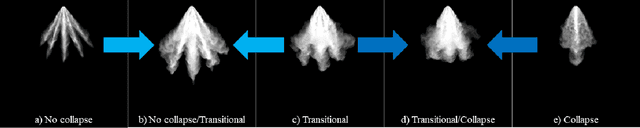
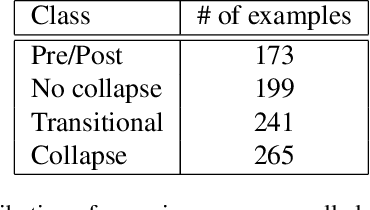
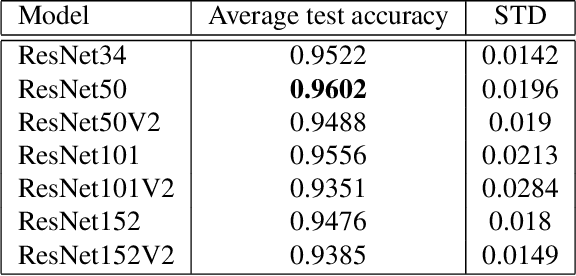
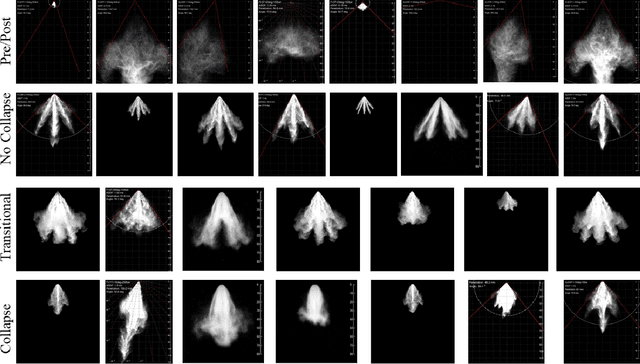
Image classification with deep neural networks has seen a surge of technological breakthroughs with promising applications in areas such as face recognition, medical imaging, and autonomous driving. In engineering problems, however, such as high-speed imaging of engine fuel injector sprays or body paint sprays, deep neural networks face a fundamental challenge related to the availability of adequate and diverse data. Typically, only thousands or sometimes even hundreds of samples are available for training. In addition, the transition between different spray classes is a continuum and requires a high level of domain expertise to label the images accurately. In this work, we used Mixup as an approach to systematically deal with the data scarcity and ambiguous class boundaries found in industrial spray applications. We show that data augmentation can mitigate the over-fitting problem of large neural networks on small data sets, to a certain level, but cannot fundamentally resolve the issue. We discuss how a convex linear interpolation of different classes naturally aligns with the continuous transition between different classes in our application. Our experiments demonstrate Mixup as a simple yet effective method to train an accurate and robust deep neural network classifier with only a few hundred samples.