 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted collapse regularized autoencoder for anomaly detection: black hole at the center
Paper and Code
Jun 22, 2023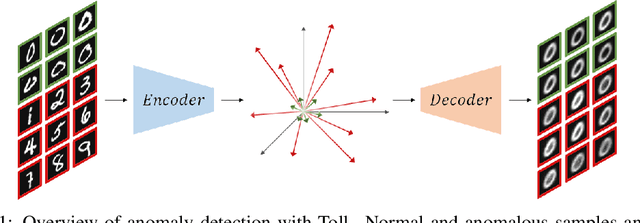
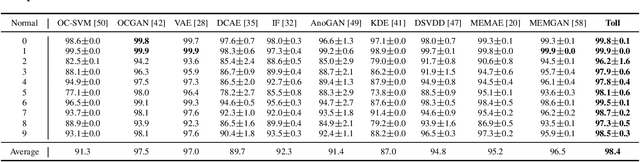

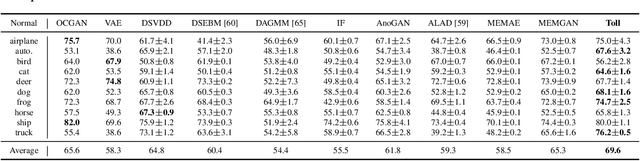
Autoencoders have been extensively used in the development of recent anomaly detection techniques. The premise of their application is based on the notion that after training the autoencoder on normal training data, anomalous inputs will exhibit a significant reconstruction error. Consequently, this enables a clear differentiation between normal and anomalous samples. In practice, however, it is observed that autoencoders can generalize beyond the normal class and achieve a small reconstruction error on some of the anomalous samples. To improve the performance, various techniques propose additional components and more sophisticated training procedures. In this work, we propose a remarkably straightforward alternative: instead of adding neural network components, involved computations, and cumbersome training, we complement the reconstruction loss with a computationally light term that regulates the norm of representations in the latent space. The simplicity of our approach minimizes the requirement for hyperparameter tuning and customization for new applications which, paired with its permissive data modality constraint, enhances the potential for successful adoption across a broad range of applications. We test the method on various visual and tabular benchmarks and demonstrate that the technique matches and frequently outperforms alternatives. We also provide a theoretical analysis and numerical simulations that help demonstrate the underlying process that unfolds during training and how it can help with anomaly detection. This mitigates the black-box nature of autoencoder-based anomaly detection algorithms and offers an avenue for further investigation of advantages, fail cases, and potential new directions.