 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Infrastructure Surveying: A Framework for Geometric Measurements and Compliance Assessment Using Point Cloud Data
May 09, 2025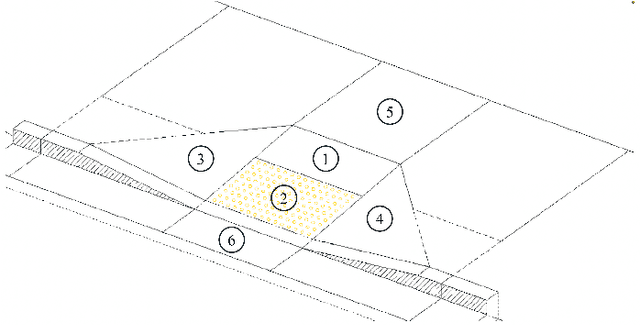
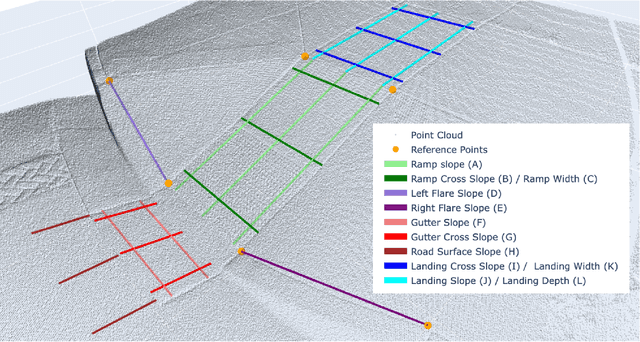
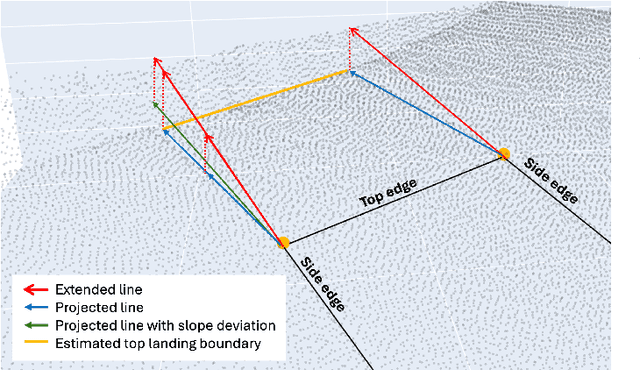
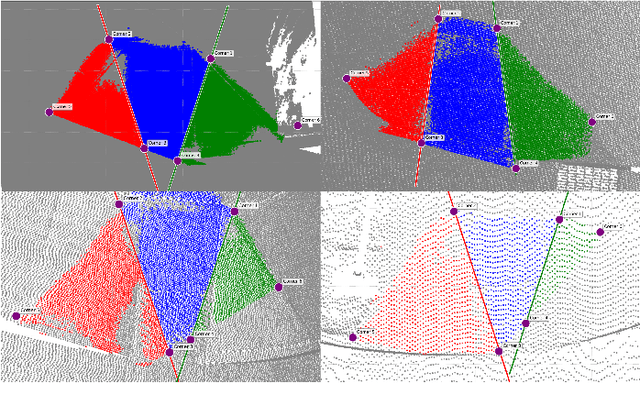
Automation can play a prominent role in improving efficiency, accuracy, and scalability in infrastructure surveying and assessing construction and compliance standards. This paper presents a framework for automation of geometric measurements and compliance assessment using point cloud data. The proposed approach integrates deep learning-based detection and segmentation, in conjunction with geometric and signal processing techniques, to automate surveying tasks. As a proof of concept, we apply this framework to automatically evaluate the compliance of curb ramps with the Americans with Disabilities Act (ADA), demonstrating the utility of point cloud data in survey automation. The method leverages a newly collected, large annotated dataset of curb ramps, made publicly available as part of this work, to facilitate robust model training and evaluation. Experimental results, including comparison with manual field measurements of several ramps, validate the accuracy and reliability of the proposed method, highlighting its potential to significantly reduce manual effort and improve consistency in infrastructure assessment. Beyond ADA compliance, the proposed framework lays the groundwork for broader applications in infrastructure surveying and automated construction evaluation, promoting wider adoption of point cloud data in these domains. The annotated database, manual ramp survey data, and developed algorithms are publicly available on the project's GitHub page: https://github.com/Soltanilara/SurveyAutomation.
Hierarchical end-to-end autonomous navigation through few-shot waypoint detection
Sep 23, 2024



Human navigation is facilitated through the association of actions with landmarks, tapping into our ability to recognize salient features in our environment. Consequently, navigational instructions for humans can be extremely concise, such as short verbal descriptions, indicating a small memory requirement and no reliance on complex and overly accurate navigation tools. Conversely, current autonomous navigation schemes rely on accurate positioning devices and algorithms as well as extensive streams of sensory data collected from the environment. Inspired by this human capability and motivated by the associated technological gap, in this work we propose a hierarchical end-to-end meta-learning scheme that enables a mobile robot to navigate in a previously unknown environment upon presentation of only a few sample images of a set of landmarks along with their corresponding high-level navigation actions. This dramatically simplifies the wayfinding process and enables easy adoption to new environments. For few-shot waypoint detection, we implement a metric-based few-shot learning technique through distribution embedding. Waypoint detection triggers the multi-task low-level maneuver controller module to execute the corresponding high-level navigation action. We demonstrate the effectiveness of the scheme using a small-scale autonomous vehicle on novel indoor navigation tasks in several previously unseen environments.
* Appeared at the 40th Anniversary of the IEEE International Conference on Robotics and Automation (ICRA@40), 23-26 September, 2024, Rotterdam, The Netherlands. 9 pages, 5 figures
Targeted collapse regularized autoencoder for anomaly detection: black hole at the center
Jun 22, 2023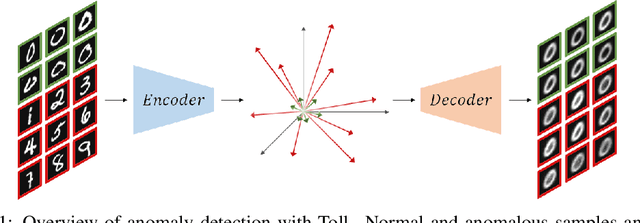
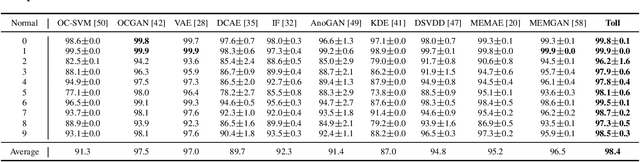

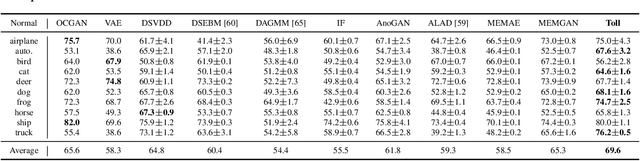
Autoencoders have been extensively used in the development of recent anomaly detection techniques. The premise of their application is based on the notion that after training the autoencoder on normal training data, anomalous inputs will exhibit a significant reconstruction error. Consequently, this enables a clear differentiation between normal and anomalous samples. In practice, however, it is observed that autoencoders can generalize beyond the normal class and achieve a small reconstruction error on some of the anomalous samples. To improve the performance, various techniques propose additional components and more sophisticated training procedures. In this work, we propose a remarkably straightforward alternative: instead of adding neural network components, involved computations, and cumbersome training, we complement the reconstruction loss with a computationally light term that regulates the norm of representations in the latent space. The simplicity of our approach minimizes the requirement for hyperparameter tuning and customization for new applications which, paired with its permissive data modality constraint, enhances the potential for successful adoption across a broad range of applications. We test the method on various visual and tabular benchmarks and demonstrate that the technique matches and frequently outperforms alternatives. We also provide a theoretical analysis and numerical simulations that help demonstrate the underlying process that unfolds during training and how it can help with anomaly detection. This mitigates the black-box nature of autoencoder-based anomaly detection algorithms and offers an avenue for further investigation of advantages, fail cases, and potential new directions.
One-Shot Learning of Visual Path Navigation for Autonomous Vehicles
Jun 15, 2023



Autonomous driving presents many challenges due to the large number of scenarios the autonomous vehicle (AV) may encounter. End-to-end deep learning models are comparatively simplistic models that can handle a broad set of scenarios. However, end-to-end models require large amounts of diverse data to perform well. This paper presents a novel deep neural network that performs image-to-steering path navigation that helps with the data problem by adding one-shot learning to the system. Presented with a previously unseen path, the vehicle can drive the path autonomously after being shown the path once and without model retraining. In fact, the full path is not needed and images of the road junctions is sufficient. In-vehicle testing and offline testing are used to verify the performance of the proposed navigation and to compare different candidate architectures.