 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical end-to-end autonomous navigation through few-shot waypoint detection
Sep 23, 2024



Human navigation is facilitated through the association of actions with landmarks, tapping into our ability to recognize salient features in our environment. Consequently, navigational instructions for humans can be extremely concise, such as short verbal descriptions, indicating a small memory requirement and no reliance on complex and overly accurate navigation tools. Conversely, current autonomous navigation schemes rely on accurate positioning devices and algorithms as well as extensive streams of sensory data collected from the environment. Inspired by this human capability and motivated by the associated technological gap, in this work we propose a hierarchical end-to-end meta-learning scheme that enables a mobile robot to navigate in a previously unknown environment upon presentation of only a few sample images of a set of landmarks along with their corresponding high-level navigation actions. This dramatically simplifies the wayfinding process and enables easy adoption to new environments. For few-shot waypoint detection, we implement a metric-based few-shot learning technique through distribution embedding. Waypoint detection triggers the multi-task low-level maneuver controller module to execute the corresponding high-level navigation action. We demonstrate the effectiveness of the scheme using a small-scale autonomous vehicle on novel indoor navigation tasks in several previously unseen environments.
* Appeared at the 40th Anniversary of the IEEE International Conference on Robotics and Automation (ICRA@40), 23-26 September, 2024, Rotterdam, The Netherlands. 9 pages, 5 figures
One-Shot Learning of Visual Path Navigation for Autonomous Vehicles
Jun 15, 2023



Autonomous driving presents many challenges due to the large number of scenarios the autonomous vehicle (AV) may encounter. End-to-end deep learning models are comparatively simplistic models that can handle a broad set of scenarios. However, end-to-end models require large amounts of diverse data to perform well. This paper presents a novel deep neural network that performs image-to-steering path navigation that helps with the data problem by adding one-shot learning to the system. Presented with a previously unseen path, the vehicle can drive the path autonomously after being shown the path once and without model retraining. In fact, the full path is not needed and images of the road junctions is sufficient. In-vehicle testing and offline testing are used to verify the performance of the proposed navigation and to compare different candidate architectures.
A Follow-the-Leader Strategy using Hierarchical Deep Neural Networks with Grouped Convolutions
Nov 04, 2020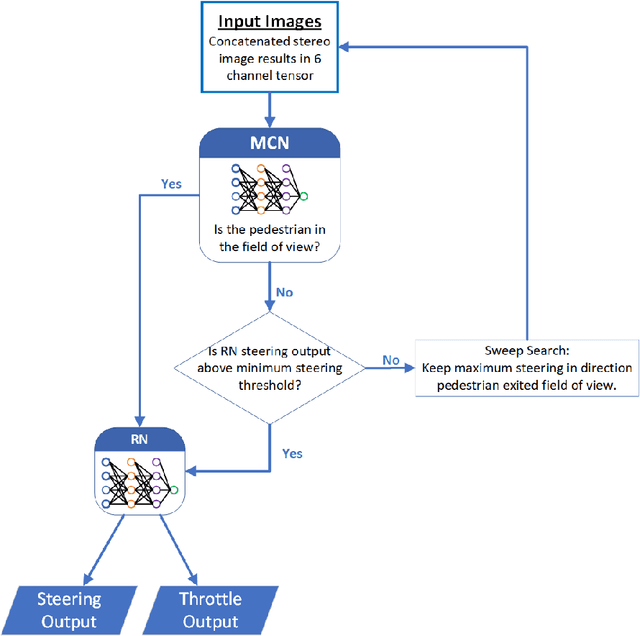
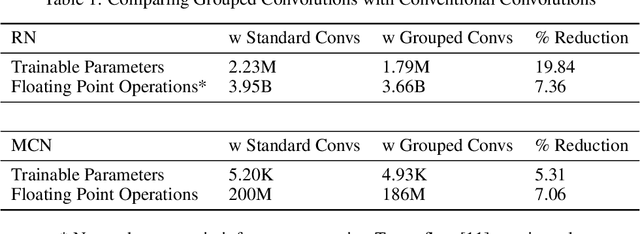
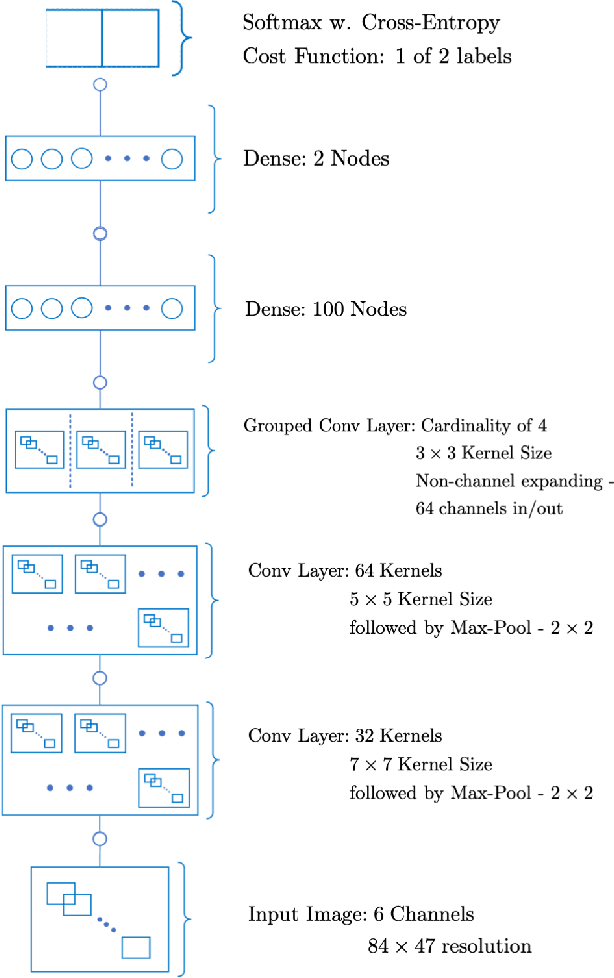

The task of following-the-leader is implemented using a hierarchical Deep Neural Network (DNN) end-to-end driving model to match the direction and speed of a target pedestrian. The model uses a classifier DNN to determine if the pedestrian is within the field of view of the camera sensor. If the pedestrian is present, the image stream from the camera is fed to a regression DNN which simultaneously adjusts the autonomous vehicle's steering and throttle to keep cadence with the pedestrian. If the pedestrian is not visible, the vehicle uses a straightforward exploratory search strategy to reacquire the tracking objective. The classifier and regression DNNs incorporate grouped convolutions to boost model performance as well as to significantly reduce parameter count and compute latency. The models are trained on the Intelligence Processing Unit (IPU) to leverage its fine-grain compute capabilities in order to minimize time-to-train. The results indicate very robust tracking behavior on the part of the autonomous vehicle in terms of its steering and throttle profiles, which required minimal data collection to produce. The throughput in terms of processing training samples has been boosted by the use of the IPU in conjunction with grouped convolutions by a factor ${\sim}3.5$ for training of the classifier and a factor of ${\sim}7$ for the regression network. A recording of the vehicle tracking a pedestrian has been produced and is available on the web.
Hierarchical Sequence to Sequence Voice Conversion with Limited Data
Jul 15, 2019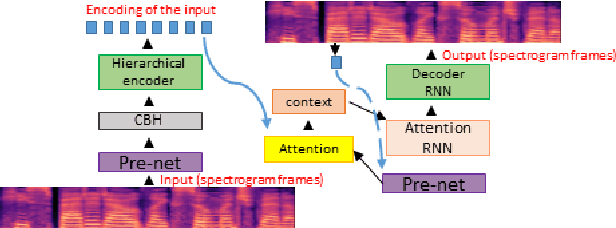

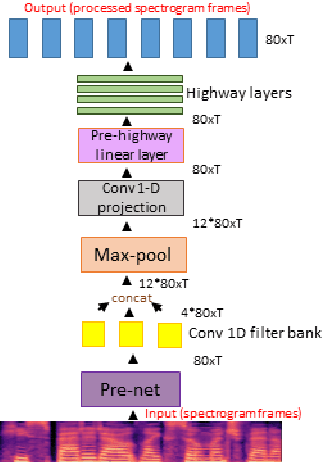
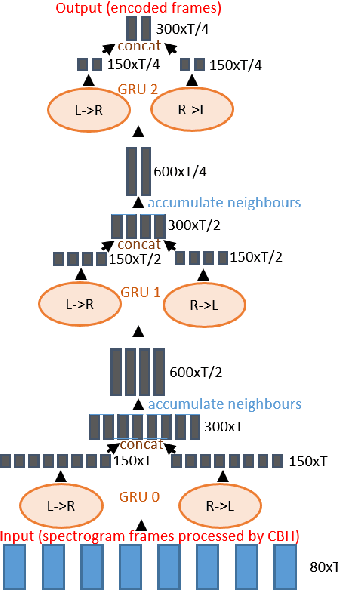
We present a voice conversion solution using recurrent sequence to sequence modeling for DNNs. Our solution takes advantage of recent advances in attention based modeling in the fields of Neural Machine Translation (NMT), Text-to-Speech (TTS) and Automatic Speech Recognition (ASR). The problem consists of converting between voices in a parallel setting when {\it $<$source,target$>$} audio pairs are available. Our seq2seq architecture makes use of a hierarchical encoder to summarize input audio frames. On the decoder side, we use an attention based architecture used in recent TTS works. Since there is a dearth of large multispeaker voice conversion databases needed for training DNNs, we resort to training the network with a large single speaker dataset as an autoencoder. This is then adapted for the smaller multispeaker voice conversion datasets available for voice conversion. In contrast with other voice conversion works that use $F_0$, duration and linguistic features, our system uses mel spectrograms as the audio representation. Output mel frames are converted back to audio using a wavenet vocoder.
Hierarchical Multi-task Deep Neural Network Architecture for End-to-End Driving
Feb 09, 2019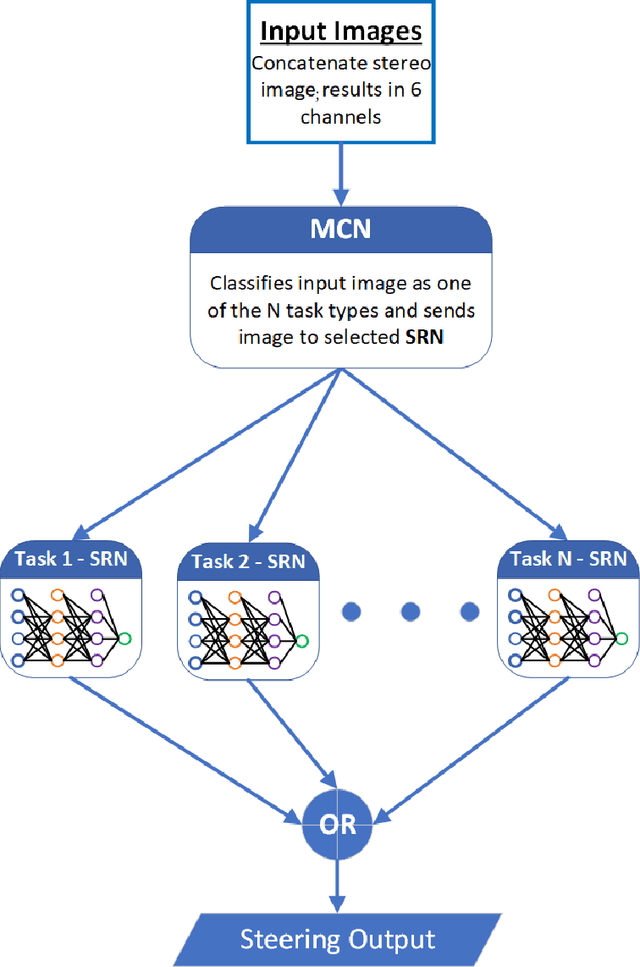
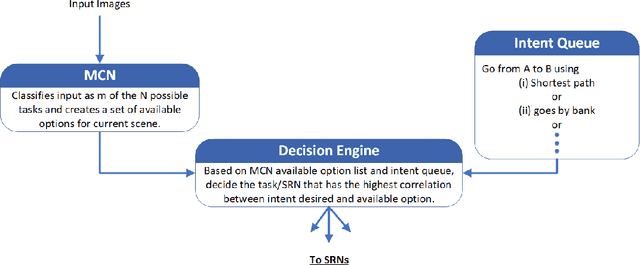

A novel hierarchical Deep Neural Network (DNN) model is presented to address the task of end-to-end driving. The model consists of a master classifier network which determines the driving task required from an input stereo image and directs said image to one of a set of subservient network regression models that perform inference and output a steering command. These subservient networks are designed and trained for a specific driving task: straightaway, swerve maneuver, tight turn, gradual turn, and chicane. Using this modular network strategy allows for two primary advantages: an overall reduction in the amount of data required to train the complete system, and for model tailoring where more complex models can be used for more challenging tasks while simplified networks can handle more mundane tasks. It is this latter facet of the model that makes the approach attractive to a number of applications beyond the current vehicle steering strategy.