 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient data-driven encoding of scene motion using Eccentricity
Mar 03, 2021
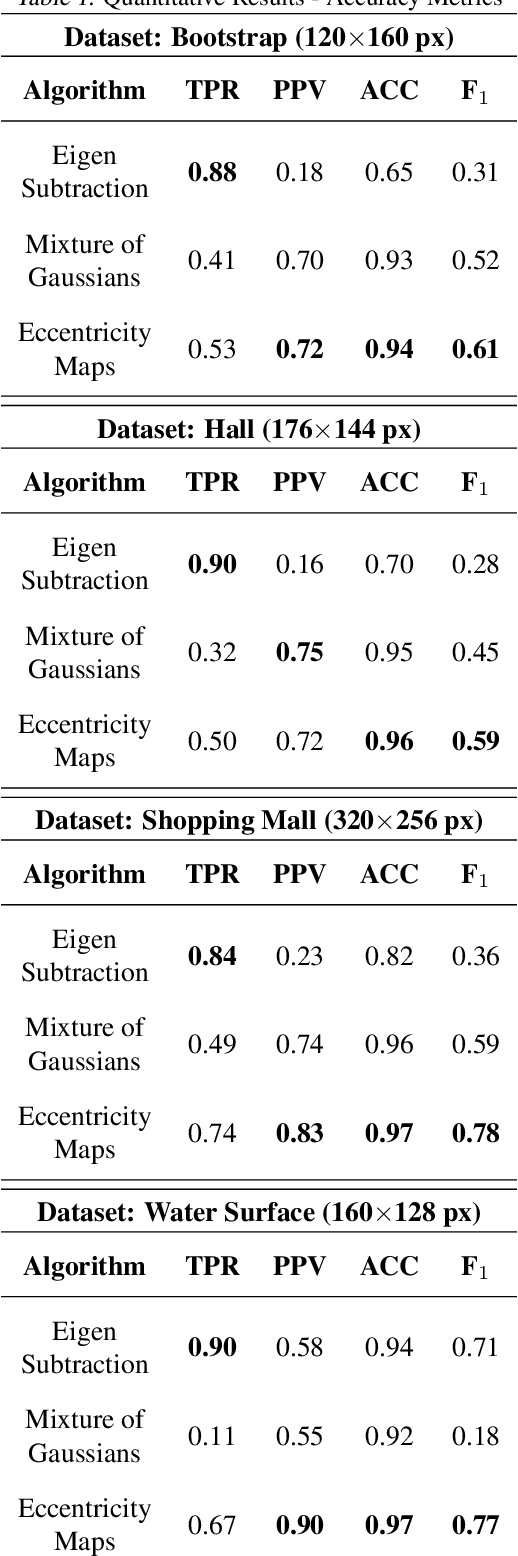

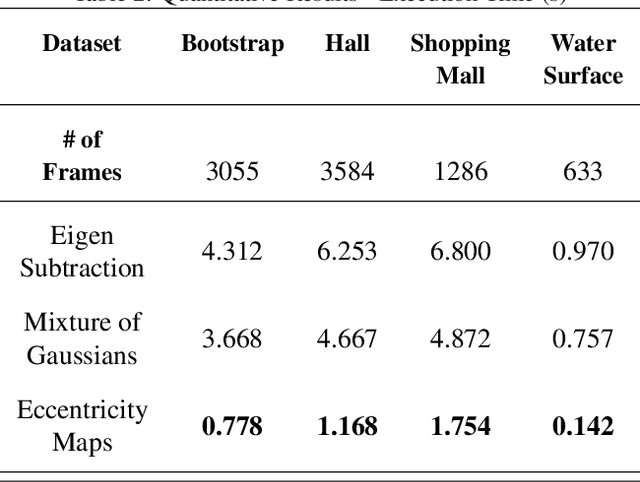
This paper presents a novel approach of representing dynamic visual scenes with static maps generated from video/image streams. Such representation allows easy visual assessment of motion in dynamic environments. These maps are 2D matrices calculated recursively, in a pixel-wise manner, that is based on the recently introduced concept of Eccentricity data analysis. Eccentricity works as a metric of a discrepancy between a particular pixel of an image and its normality model, calculated in terms of mean and variance of past readings of the same spatial region of the image. While Eccentricity maps carry temporal information about the scene, actual images do not need to be stored nor processed in batches. Rather, all the calculations are done recursively, based on a small amount of statistical information stored in memory, thus resulting in a very computationally efficient (processor- and memory-wise) method. The list of potential applications includes video-based activity recognition, intent recognition, object tracking, video description, and so on.
Hierarchical Sequence to Sequence Voice Conversion with Limited Data
Jul 15, 2019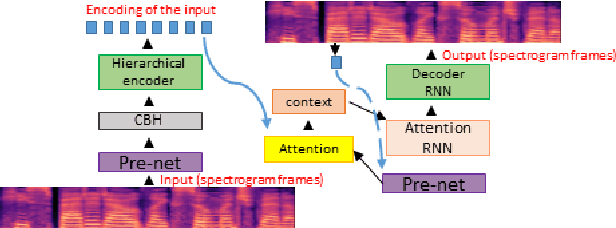

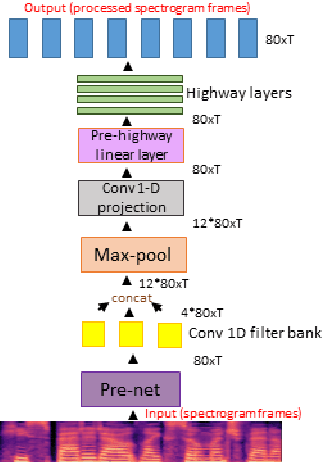
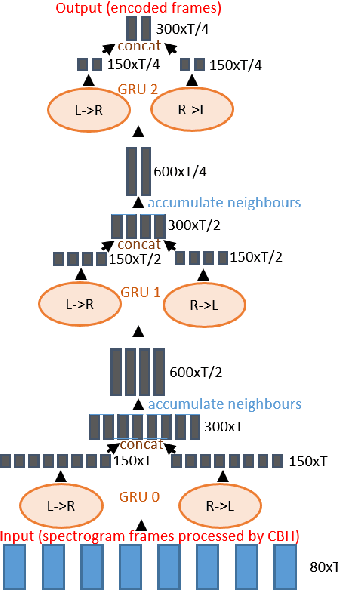
We present a voice conversion solution using recurrent sequence to sequence modeling for DNNs. Our solution takes advantage of recent advances in attention based modeling in the fields of Neural Machine Translation (NMT), Text-to-Speech (TTS) and Automatic Speech Recognition (ASR). The problem consists of converting between voices in a parallel setting when {\it $<$source,target$>$} audio pairs are available. Our seq2seq architecture makes use of a hierarchical encoder to summarize input audio frames. On the decoder side, we use an attention based architecture used in recent TTS works. Since there is a dearth of large multispeaker voice conversion databases needed for training DNNs, we resort to training the network with a large single speaker dataset as an autoencoder. This is then adapted for the smaller multispeaker voice conversion datasets available for voice conversion. In contrast with other voice conversion works that use $F_0$, duration and linguistic features, our system uses mel spectrograms as the audio representation. Output mel frames are converted back to audio using a wavenet vocoder.
Motion Guided LIDAR-camera Autocalibration and Accelerated Depth Super Resolution
Mar 28, 2018
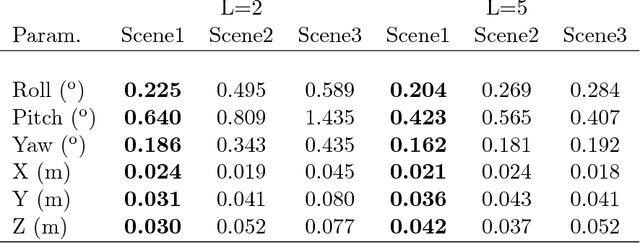
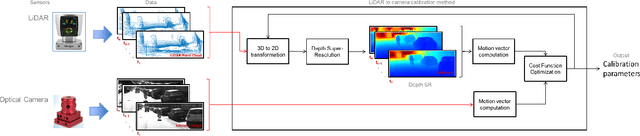

In this work we propose a novel motion guided method for automatic and targetless calibration of a LiDAR and camera and use the LiDAR points projected on the image for real-time super-resolution depth estimation. The calibration parameters are estimated by optimizing a cost function that penalizes the difference in the motion vectors obtained from LiDAR and camera data separately. For super-resolution, we propose a simple, yet effective and time efficient formulation that minimizes depth gradients subject to an equality constraint involving measured LiDAR data. We perform experiments on real data obtained in urban environments and demonstrate that the proposed calibration technique is robust and the real-time depth super-resolution reconstruction outperforms the quality of state of the art approaches.