 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOCAL: A Cost-Aware Video Dataset for Active Learning
Nov 17, 2023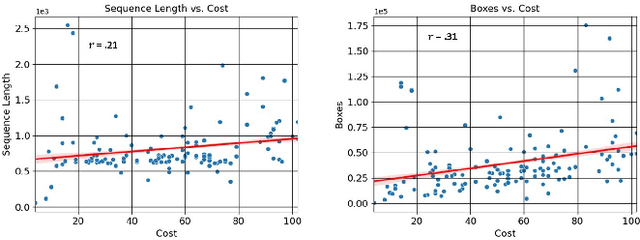
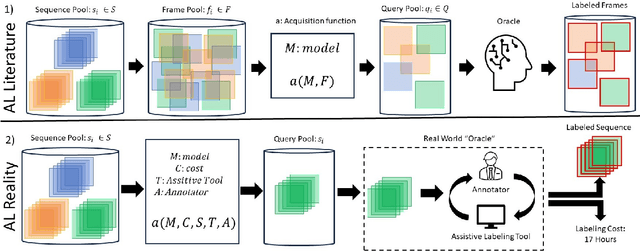
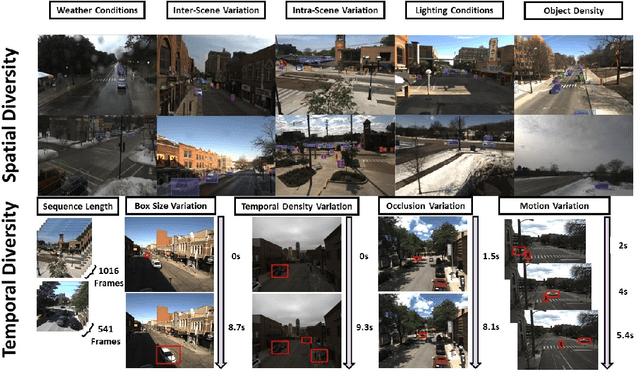
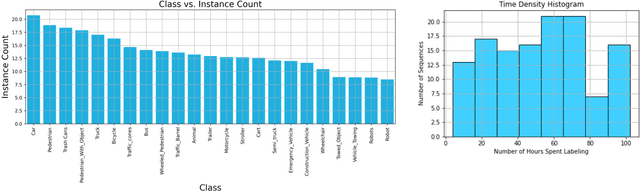
In this paper, we introduce the FOCAL (Ford-OLIVES Collaboration on Active Learning) dataset which enables the study of the impact of annotation-cost within a video active learning setting. Annotation-cost refers to the time it takes an annotator to label and quality-assure a given video sequence. A practical motivation for active learning research is to minimize annotation-cost by selectively labeling informative samples that will maximize performance within a given budget constraint. However, previous work in video active learning lacks real-time annotation labels for accurately assessing cost minimization and instead operates under the assumption that annotation-cost scales linearly with the amount of data to annotate. This assumption does not take into account a variety of real-world confounding factors that contribute to a nonlinear cost such as the effect of an assistive labeling tool and the variety of interactions within a scene such as occluded objects, weather, and motion of objects. FOCAL addresses this discrepancy by providing real annotation-cost labels for 126 video sequences across 69 unique city scenes with a variety of weather, lighting, and seasonal conditions. We also introduce a set of conformal active learning algorithms that take advantage of the sequential structure of video data in order to achieve a better trade-off between annotation-cost and performance while also reducing floating point operations (FLOPS) overhead by at least 77.67%. We show how these approaches better reflect how annotations on videos are done in practice through a sequence selection framework. We further demonstrate the advantage of these approaches by introducing two performance-cost metrics and show that the best conformal active learning method is cheaper than the best traditional active learning method by 113 hours.
Deep Feature Tracker: A Novel Application for Deep Convolutional Neural Networks
Jul 30, 2021

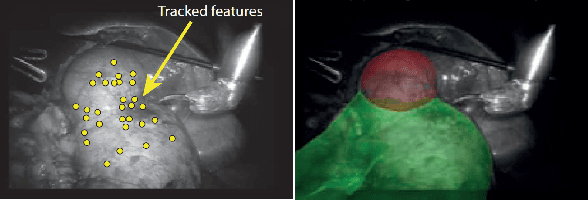

Feature tracking is the building block of many applications such as visual odometry, augmented reality, and target tracking. Unfortunately, the state-of-the-art vision-based tracking algorithms fail in surgical images due to the challenges imposed by the nature of such environments. In this paper, we proposed a novel and unified deep learning-based approach that can learn how to track features reliably as well as learn how to detect such reliable features for tracking purposes. The proposed network dubbed as Deep-PT, consists of a tracker network which is a convolutional neural network simulating cross-correlation in terms of deep learning and two fully connected networks that operate on the output of intermediate layers of the tracker to detect features and predict trackability of the detected points. The ability to detect features based on the capabilities of the tracker distinguishes the proposed method from previous algorithms used in this area and improves the robustness of the algorithms against dynamics of the scene. The network is trained using multiple datasets due to the lack of specialized dataset for feature tracking datasets and extensive comparisons are conducted to compare the accuracy of Deep-PT against recent pixel tracking algorithms. As the experiments suggest, the proposed deep architecture deliberately learns what to track and how to track and outperforms the state-of-the-art methods.
Efficient data-driven encoding of scene motion using Eccentricity
Mar 03, 2021

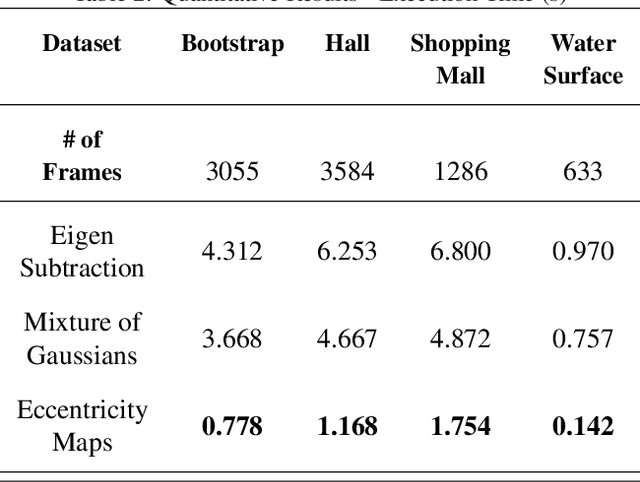
This paper presents a novel approach of representing dynamic visual scenes with static maps generated from video/image streams. Such representation allows easy visual assessment of motion in dynamic environments. These maps are 2D matrices calculated recursively, in a pixel-wise manner, that is based on the recently introduced concept of Eccentricity data analysis. Eccentricity works as a metric of a discrepancy between a particular pixel of an image and its normality model, calculated in terms of mean and variance of past readings of the same spatial region of the image. While Eccentricity maps carry temporal information about the scene, actual images do not need to be stored nor processed in batches. Rather, all the calculations are done recursively, based on a small amount of statistical information stored in memory, thus resulting in a very computationally efficient (processor- and memory-wise) method. The list of potential applications includes video-based activity recognition, intent recognition, object tracking, video description, and so on.
Deep Learning Architectures for Face Recognition in Video Surveillance
Jun 27, 2018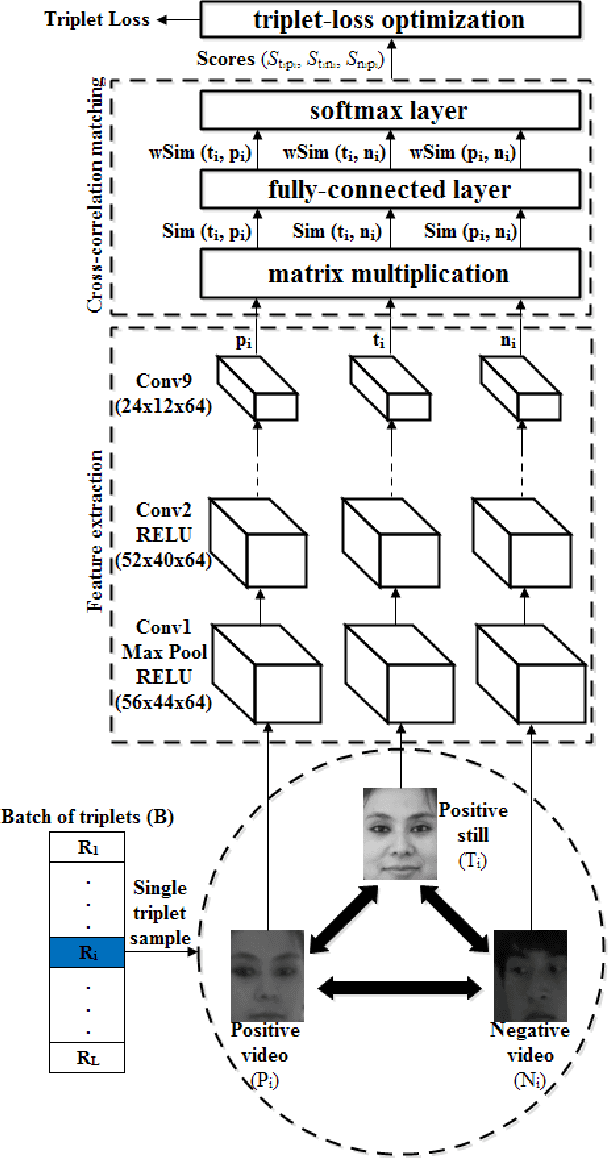
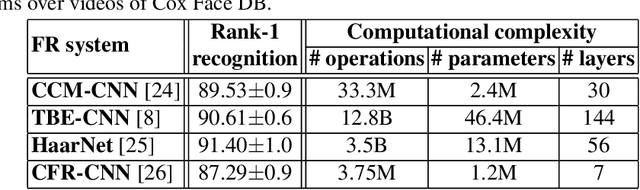
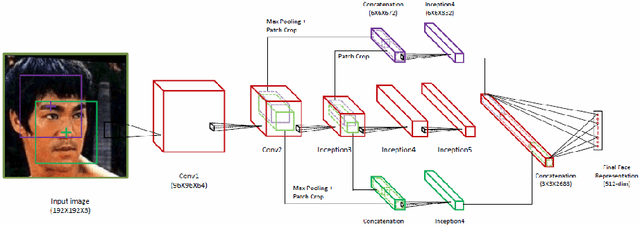
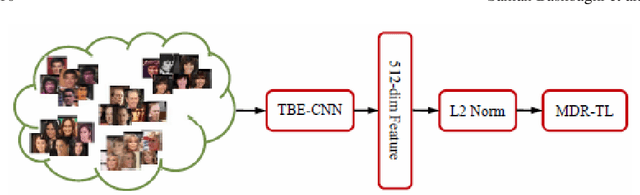
Face recognition (FR) systems for video surveillance (VS) applications attempt to accurately detect the presence of target individuals over a distributed network of cameras. In video-based FR systems, facial models of target individuals are designed a priori during enrollment using a limited number of reference still images or video data. These facial models are not typically representative of faces being observed during operations due to large variations in illumination, pose, scale, occlusion, blur, and to camera inter-operability. Specifically, in still-to-video FR application, a single high-quality reference still image captured with still camera under controlled conditions is employed to generate a facial model to be matched later against lower-quality faces captured with video cameras under uncontrolled conditions. Current video-based FR systems can perform well on controlled scenarios, while their performance is not satisfactory in uncontrolled scenarios mainly because of the differences between the source (enrollment) and the target (operational) domains. Most of the efforts in this area have been toward the design of robust video-based FR systems in unconstrained surveillance environments. This chapter presents an overview of recent advances in still-to-video FR scenario through deep convolutional neural networks (CNNs). In particular, deep learning architectures proposed in the literature based on triplet-loss function (e.g., cross-correlation matching CNN, trunk-branch ensemble CNN and HaarNet) and supervised autoencoders (e.g., canonical face representation CNN) are reviewed and compared in terms of accuracy and computational complexity.
Scalable Deep Traffic Flow Neural Networks for Urban Traffic Congestion Prediction
Mar 03, 2017
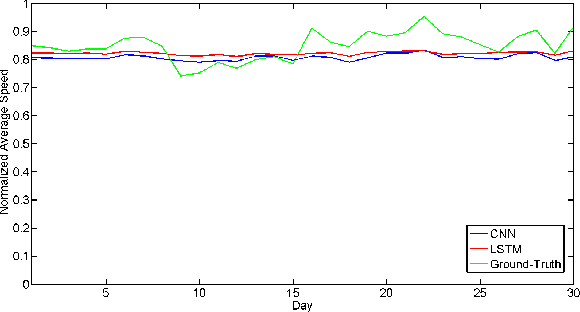
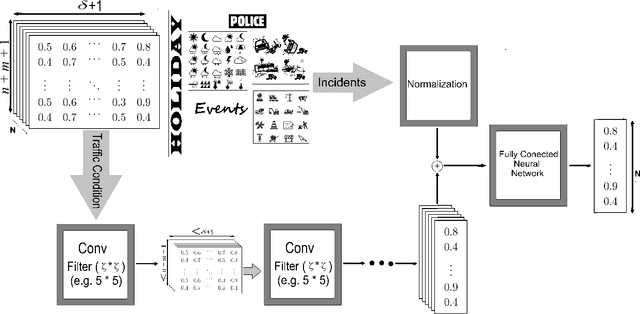
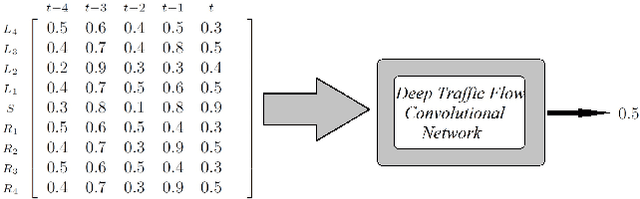
Tracking congestion throughout the network road is a critical component of Intelligent transportation network management systems. Understanding how the traffic flows and short-term prediction of congestion occurrence due to rush-hour or incidents can be beneficial to such systems to effectively manage and direct the traffic to the most appropriate detours. Many of the current traffic flow prediction systems are designed by utilizing a central processing component where the prediction is carried out through aggregation of the information gathered from all measuring stations. However, centralized systems are not scalable and fail provide real-time feedback to the system whereas in a decentralized scheme, each node is responsible to predict its own short-term congestion based on the local current measurements in neighboring nodes. We propose a decentralized deep learning-based method where each node accurately predicts its own congestion state in real-time based on the congestion state of the neighboring stations. Moreover, historical data from the deployment site is not required, which makes the proposed method more suitable for newly installed stations. In order to achieve higher performance, we introduce a regularized Euclidean loss function that favors high congestion samples over low congestion samples to avoid the impact of the unbalanced training dataset. A novel dataset for this purpose is designed based on the traffic data obtained from traffic control stations in northern California. Extensive experiments conducted on the designed benchmark reflect a successful congestion prediction.