 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBALD-SAM: Disagreement-based Active Prompting in Interactive Segmentation
Mar 11, 2026The Segment Anything Model (SAM) has revolutionized interactive segmentation through spatial prompting. While existing work primarily focuses on automating prompts in various settings, real-world annotation workflows involve iterative refinement where annotators observe model outputs and strategically place prompts to resolve ambiguities. Current pipelines typically rely on the annotator's visual assessment of the predicted mask quality. We postulate that a principled approach for automated interactive prompting is to use a model-derived criterion to identify the most informative region for the next prompt. In this work, we establish active prompting: a spatial active learning approach where locations within images constitute an unlabeled pool and prompts serve as queries to prioritize information-rich regions, increasing the utility of each interaction. We further present BALD-SAM: a principled framework adapting Bayesian Active Learning by Disagreement (BALD) to spatial prompt selection by quantifying epistemic uncertainty. To do so, we freeze the entire model and apply Bayesian uncertainty modeling only to a small learned prediction head, making intractable uncertainty estimation practical for large multi-million parameter foundation models. Across 16 datasets spanning natural, medical, underwater, and seismic domains, BALD-SAM demonstrates strong cross-domain performance, ranking first or second on 14 of 16 benchmarks. We validate these gains through a comprehensive ablation suite covering 3 SAM backbones and 35 Laplace posterior configurations, amounting to 38 distinct ablation settings. Beyond strong average performance, BALD-SAM surpasses human prompting and, in several categories, even oracle prompting, while consistently outperforming one-shot baselines in final segmentation quality, particularly on thin and structurally complex objects.
Gradient based Severity Labeling for Biomarker Classification in OCT
Feb 23, 2026In this paper, we propose a novel selection strategy for contrastive learning for medical images. On natural images, contrastive learning uses augmentations to select positive and negative pairs for the contrastive loss. However, in the medical domain, arbitrary augmentations have the potential to distort small localized regions that contain the biomarkers we are interested in detecting. A more intuitive approach is to select samples with similar disease severity characteristics, since these samples are more likely to have similar structures related to the progression of a disease. To enable this, we introduce a method that generates disease severity labels for unlabeled OCT scans on the basis of gradient responses from an anomaly detection algorithm. These labels are used to train a supervised contrastive learning setup to improve biomarker classification accuracy by as much as 6% above self-supervised baselines for key indicators of Diabetic Retinopathy.
Countering Multi-modal Representation Collapse through Rank-targeted Fusion
Nov 09, 2025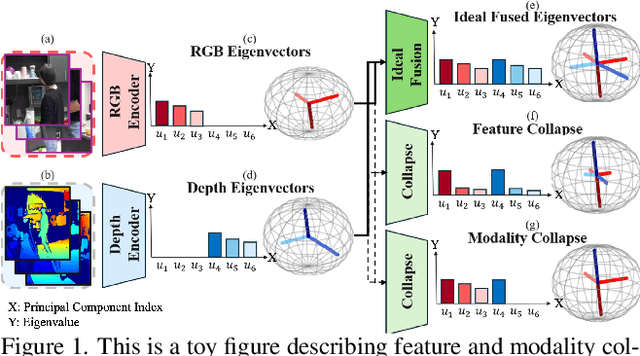
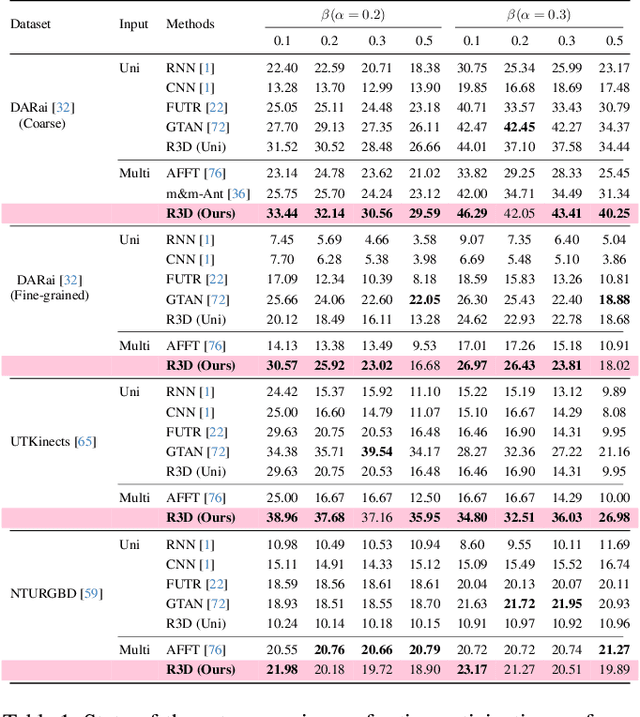
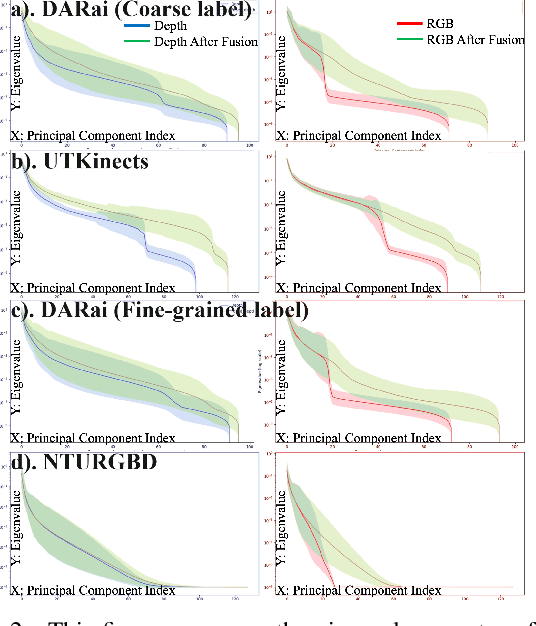
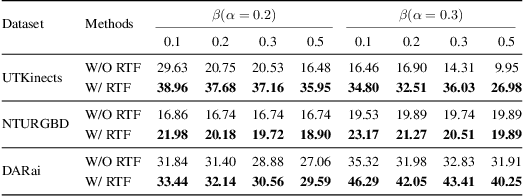
Multi-modal fusion methods often suffer from two types of representation collapse: feature collapse where individual dimensions lose their discriminative power (as measured by eigenspectra), and modality collapse where one dominant modality overwhelms the other. Applications like human action anticipation that require fusing multifarious sensor data are hindered by both feature and modality collapse. However, existing methods attempt to counter feature collapse and modality collapse separately. This is because there is no unifying framework that efficiently addresses feature and modality collapse in conjunction. In this paper, we posit the utility of effective rank as an informative measure that can be utilized to quantify and counter both the representation collapses. We propose \textit{Rank-enhancing Token Fuser}, a theoretically grounded fusion framework that selectively blends less informative features from one modality with complementary features from another modality. We show that our method increases the effective rank of the fused representation. To address modality collapse, we evaluate modality combinations that mutually increase each others' effective rank. We show that depth maintains representational balance when fused with RGB, avoiding modality collapse. We validate our method on action anticipation, where we present \texttt{R3D}, a depth-informed fusion framework. Extensive experiments on NTURGBD, UTKinect, and DARai demonstrate that our approach significantly outperforms prior state-of-the-art methods by up to 3.74\%. Our code is available at: \href{https://github.com/olivesgatech/R3D}{https://github.com/olivesgatech/R3D}.
AdaDim: Dimensionality Adaptation for SSL Representational Dynamics
May 18, 2025A key factor in effective Self-Supervised learning (SSL) is preventing dimensional collapse, which is where higher-dimensional representation spaces span a lower-dimensional subspace. Therefore, SSL optimization strategies involve guiding a model to produce representations ($R$) with a higher dimensionality. Dimensionality is either optimized through a dimension-contrastive approach that encourages feature decorrelation or through a sample-contrastive method that promotes a uniform spread of sample representations. Both families of SSL algorithms also utilize a projection head that maps $R$ into a lower-dimensional embedding space $Z$. Recent work has characterized the projection head as a filter of irrelevant features from the SSL objective by reducing mutual information, $I(R;Z)$. Therefore, the current literature's view is that a good SSL representation space should have a high $H(R)$ and a low $I(R;Z)$. However, this view of the problem is lacking in terms of an understanding of the underlying training dynamics that influences both terms, as well as how the values of $H(R)$ and $I(R;Z)$ arrived at the end of training reflect the downstream performance of an SSL model. We address both gaps in the literature by demonstrating that increases in $H(R)$ due to feature decorrelation at the start of training lead to a higher $I(R;Z)$, while increases in $H(R)$ due to samples distributing uniformly in a high-dimensional space at the end of training cause $I(R;Z)$ to plateau or decrease. Furthermore, our analysis shows that the best performing SSL models do not have the highest $H(R)$ nor the lowest $I(R;Z)$, but arrive at an optimal intermediate point for both. We develop a method called AdaDim to exploit these observed training dynamics by adaptively weighting between losses based on feature decorrelation and uniform sample spread.
A Large-scale Benchmark on Geological Fault Delineation Models: Domain Shift, Training Dynamics, Generalizability, Evaluation and Inferential Behavior
May 13, 2025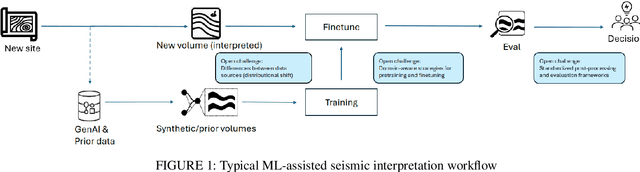
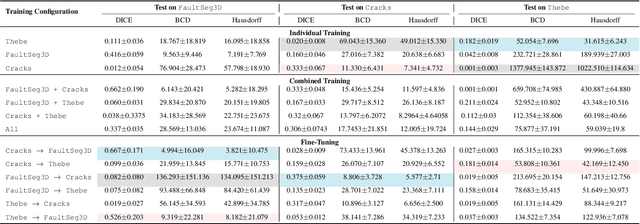
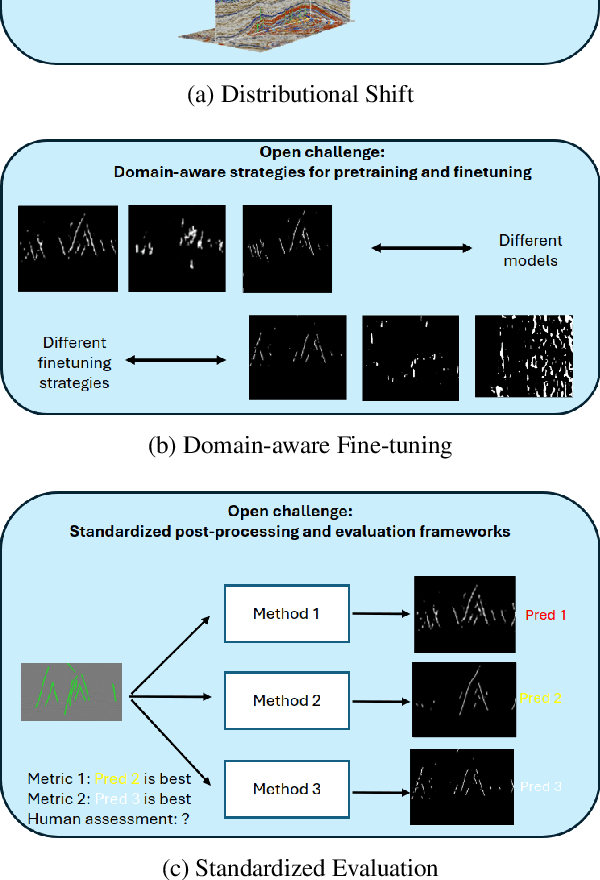
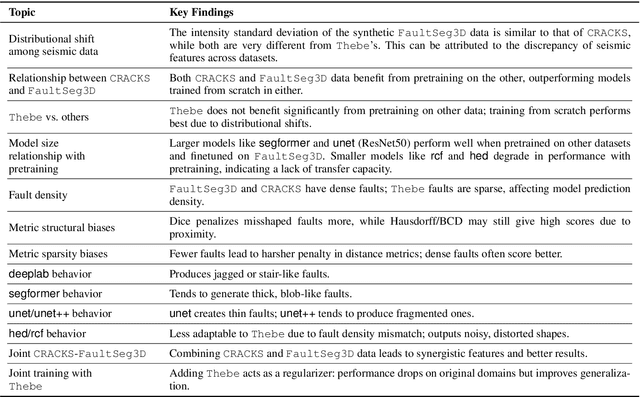
Machine learning has taken a critical role in seismic interpretation workflows, especially in fault delineation tasks. However, despite the recent proliferation of pretrained models and synthetic datasets, the field still lacks a systematic understanding of the generalizability limits of these models across seismic data representing a variety of geologic, acquisition and processing settings. Distributional shifts between different data sources, limitations in fine-tuning strategies and labeled data accessibility, and inconsistent evaluation protocols all represent major roadblocks in the deployment of reliable and robust models in real-world exploration settings. In this paper, we present the first large-scale benchmarking study explicitly designed to provide answers and guidelines for domain shift strategies in seismic interpretation. Our benchmark encompasses over $200$ models trained and evaluated on three heterogeneous datasets (synthetic and real data) including FaultSeg3D, CRACKS, and Thebe. We systematically assess pretraining, fine-tuning, and joint training strategies under varying degrees of domain shift. Our analysis highlights the fragility of current fine-tuning practices, the emergence of catastrophic forgetting, and the challenges of interpreting performance in a systematic manner. We establish a robust experimental baseline to provide insights into the tradeoffs inherent to current fault delineation workflows, and shed light on directions for developing more generalizable, interpretable and effective machine learning models for seismic interpretation. The insights and analyses reported provide a set of guidelines on the deployment of fault delineation models within seismic interpretation workflows.
Hierarchical and Multimodal Data for Daily Activity Understanding
Apr 24, 2025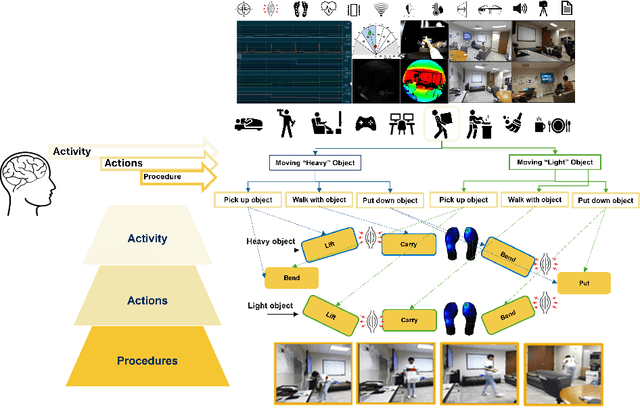


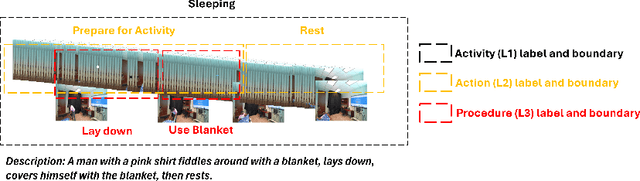
Daily Activity Recordings for Artificial Intelligence (DARai, pronounced "Dahr-ree") is a multimodal, hierarchically annotated dataset constructed to understand human activities in real-world settings. DARai consists of continuous scripted and unscripted recordings of 50 participants in 10 different environments, totaling over 200 hours of data from 20 sensors including multiple camera views, depth and radar sensors, wearable inertial measurement units (IMUs), electromyography (EMG), insole pressure sensors, biomonitor sensors, and gaze tracker. To capture the complexity in human activities, DARai is annotated at three levels of hierarchy: (i) high-level activities (L1) that are independent tasks, (ii) lower-level actions (L2) that are patterns shared between activities, and (iii) fine-grained procedures (L3) that detail the exact execution steps for actions. The dataset annotations and recordings are designed so that 22.7% of L2 actions are shared between L1 activities and 14.2% of L3 procedures are shared between L2 actions. The overlap and unscripted nature of DARai allows counterfactual activities in the dataset. Experiments with various machine learning models showcase the value of DARai in uncovering important challenges in human-centered applications. Specifically, we conduct unimodal and multimodal sensor fusion experiments for recognition, temporal localization, and future action anticipation across all hierarchical annotation levels. To highlight the limitations of individual sensors, we also conduct domain-variant experiments that are enabled by DARai's multi-sensor and counterfactual activity design setup. The code, documentation, and dataset are available at the dedicated DARai website: https://alregib.ece.gatech.edu/software-and-datasets/darai-daily-activity-recordings-for-artificial-intelligence-and-machine-learning/
Targeting Negative Flips in Active Learning using Validation Sets
Nov 16, 2024The performance of active learning algorithms can be improved in two ways. The often used and intuitive way is by reducing the overall error rate within the test set. The second way is to ensure that correct predictions are not forgotten when the training set is increased in between rounds. The former is measured by the accuracy of the model and the latter is captured in negative flips between rounds. Negative flips are samples that are correctly predicted when trained with the previous/smaller dataset and incorrectly predicted after additional samples are labeled. In this paper, we discuss improving the performance of active learning algorithms both in terms of prediction accuracy and negative flips. The first observation we make in this paper is that negative flips and overall error rates are decoupled and reducing one does not necessarily imply that the other is reduced. Our observation is important as current active learning algorithms do not consider negative flips directly and implicitly assume the opposite. The second observation is that performing targeted active learning on subsets of the unlabeled pool has a significant impact on the behavior of the active learning algorithm and influences both negative flips and prediction accuracy. We then develop ROSE - a plug-in algorithm that utilizes a small labeled validation set to restrict arbitrary active learning acquisition functions to negative flips within the unlabeled pool. We show that integrating a validation set results in a significant performance boost in terms of accuracy, negative flip rate reduction, or both.
HEX: Hierarchical Emergence Exploitation in Self-Supervised Algorithms
Oct 30, 2024
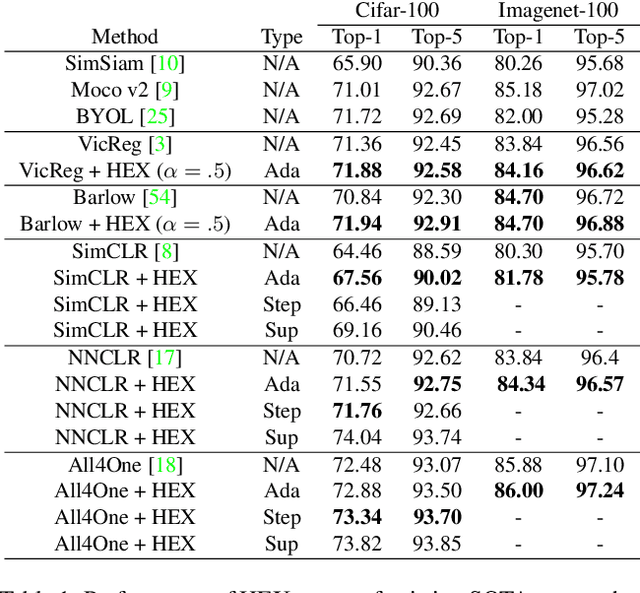

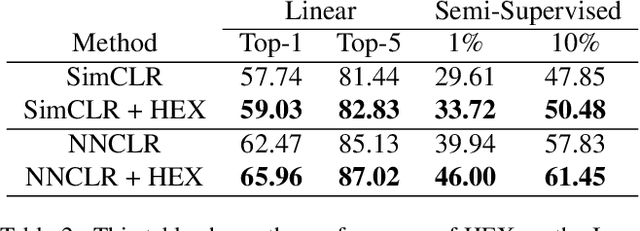
In this paper, we propose an algorithm that can be used on top of a wide variety of self-supervised (SSL) approaches to take advantage of hierarchical structures that emerge during training. SSL approaches typically work through some invariance term to ensure consistency between similar samples and a regularization term to prevent global dimensional collapse. Dimensional collapse refers to data representations spanning a lower-dimensional subspace. Recent work has demonstrated that the representation space of these algorithms gradually reflects a semantic hierarchical structure as training progresses. Data samples of the same hierarchical grouping tend to exhibit greater dimensional collapse locally compared to the dataset as a whole due to sharing features in common with each other. Ideally, SSL algorithms would take advantage of this hierarchical emergence to have an additional regularization term to account for this local dimensional collapse effect. However, the construction of existing SSL algorithms does not account for this property. To address this, we propose an adaptive algorithm that performs a weighted decomposition of the denominator of the InfoNCE loss into two terms: local hierarchical and global collapse regularization respectively. This decomposition is based on an adaptive threshold that gradually lowers to reflect the emerging hierarchical structure of the representation space throughout training. It is based on an analysis of the cosine similarity distribution of samples in a batch. We demonstrate that this hierarchical emergence exploitation (HEX) approach can be integrated across a wide variety of SSL algorithms. Empirically, we show performance improvements of up to 5.6% relative improvement over baseline SSL approaches on classification accuracy on Imagenet with 100 epochs of training.
Benchmarking Human and Automated Prompting in the Segment Anything Model
Oct 29, 2024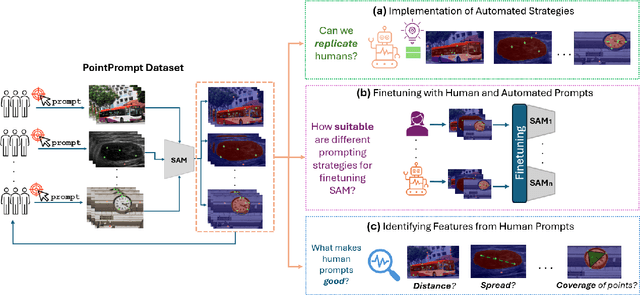

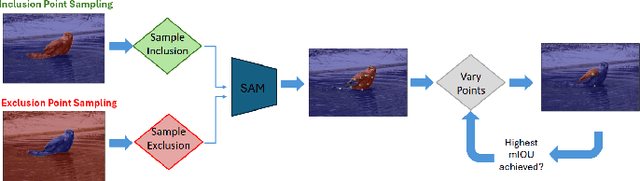
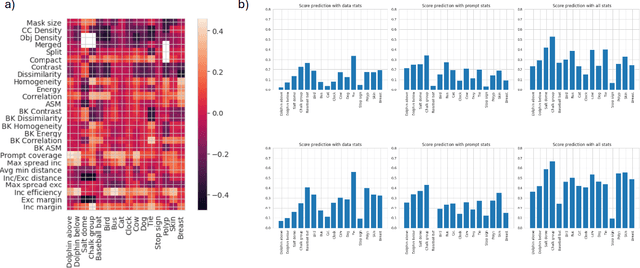
The remarkable capabilities of the Segment Anything Model (SAM) for tackling image segmentation tasks in an intuitive and interactive manner has sparked interest in the design of effective visual prompts. Such interest has led to the creation of automated point prompt selection strategies, typically motivated from a feature extraction perspective. However, there is still very little understanding of how appropriate these automated visual prompting strategies are, particularly when compared to humans, across diverse image domains. Additionally, the performance benefits of including such automated visual prompting strategies within the finetuning process of SAM also remains unexplored, as does the effect of interpretable factors like distance between the prompt points on segmentation performance. To bridge these gaps, we leverage a recently released visual prompting dataset, PointPrompt, and introduce a number of benchmarking tasks that provide an array of opportunities to improve the understanding of the way human prompts differ from automated ones and what underlying factors make for effective visual prompts. We demonstrate that the resulting segmentation scores obtained by humans are approximately 29% higher than those given by automated strategies and identify potential features that are indicative of prompting performance with $R^2$ scores over 0.5. Additionally, we demonstrate that performance when using automated methods can be improved by up to 68% via a finetuning approach. Overall, our experiments not only showcase the existing gap between human prompts and automated methods, but also highlight potential avenues through which this gap can be leveraged to improve effective visual prompt design. Further details along with the dataset links and codes are available at https://github.com/olivesgatech/PointPrompt
Ophthalmic Biomarker Detection: Highlights from the IEEE Video and Image Processing Cup 2023 Student Competition
Aug 20, 2024



The VIP Cup offers a unique experience to undergraduates, allowing students to work together to solve challenging, real-world problems with video and image processing techniques. In this iteration of the VIP Cup, we challenged students to balance personalization and generalization when performing biomarker detection in 3D optical coherence tomography (OCT) images. Balancing personalization and generalization is an important challenge to tackle, as the variation within OCT scans of patients between visits can be minimal while the difference in manifestation of the same disease across different patients may be substantial. The domain difference between OCT scans can arise due to pathology manifestation across patients, clinical labels, and the visit along the treatment process when the scan is taken. Hence, we provided a multimodal OCT dataset to allow teams to effectively target this challenge. Overall, this competition gave undergraduates an opportunity to learn about how artificial intelligence can be a powerful tool for the medical field, as well as the unique challenges one faces when applying machine learning to biomedical data.