 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Human and Automated Prompting in the Segment Anything Model
Paper and Code
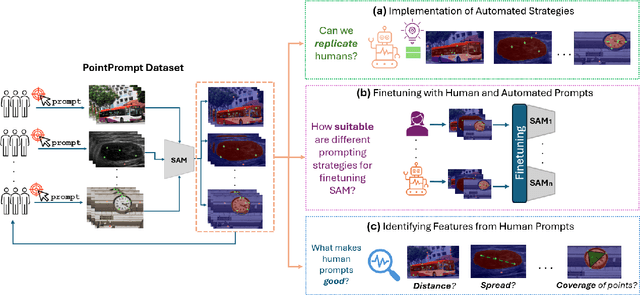

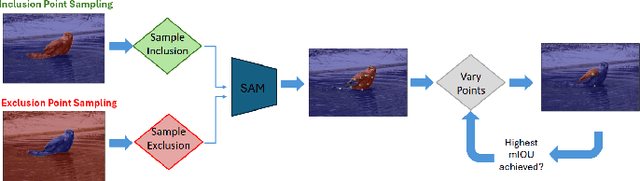
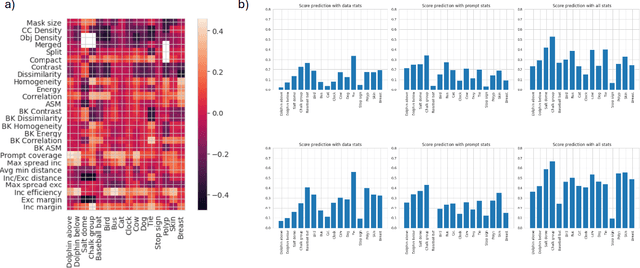
The remarkable capabilities of the Segment Anything Model (SAM) for tackling image segmentation tasks in an intuitive and interactive manner has sparked interest in the design of effective visual prompts. Such interest has led to the creation of automated point prompt selection strategies, typically motivated from a feature extraction perspective. However, there is still very little understanding of how appropriate these automated visual prompting strategies are, particularly when compared to humans, across diverse image domains. Additionally, the performance benefits of including such automated visual prompting strategies within the finetuning process of SAM also remains unexplored, as does the effect of interpretable factors like distance between the prompt points on segmentation performance. To bridge these gaps, we leverage a recently released visual prompting dataset, PointPrompt, and introduce a number of benchmarking tasks that provide an array of opportunities to improve the understanding of the way human prompts differ from automated ones and what underlying factors make for effective visual prompts. We demonstrate that the resulting segmentation scores obtained by humans are approximately 29% higher than those given by automated strategies and identify potential features that are indicative of prompting performance with $R^2$ scores over 0.5. Additionally, we demonstrate that performance when using automated methods can be improved by up to 68% via a finetuning approach. Overall, our experiments not only showcase the existing gap between human prompts and automated methods, but also highlight potential avenues through which this gap can be leveraged to improve effective visual prompt design. Further details along with the dataset links and codes are available at https://github.com/olivesgatech/PointPrompt