 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Human and Automated Prompting in the Segment Anything Model
Oct 29, 2024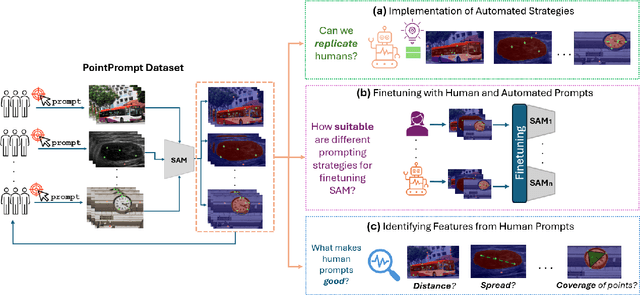

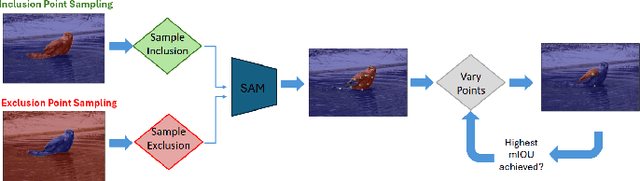
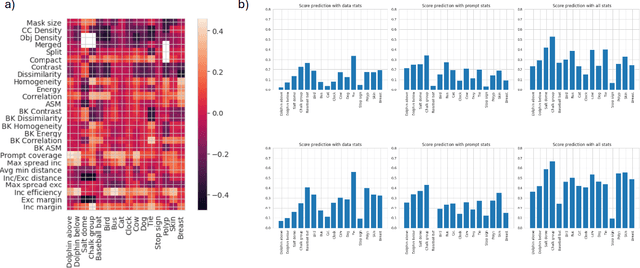
The remarkable capabilities of the Segment Anything Model (SAM) for tackling image segmentation tasks in an intuitive and interactive manner has sparked interest in the design of effective visual prompts. Such interest has led to the creation of automated point prompt selection strategies, typically motivated from a feature extraction perspective. However, there is still very little understanding of how appropriate these automated visual prompting strategies are, particularly when compared to humans, across diverse image domains. Additionally, the performance benefits of including such automated visual prompting strategies within the finetuning process of SAM also remains unexplored, as does the effect of interpretable factors like distance between the prompt points on segmentation performance. To bridge these gaps, we leverage a recently released visual prompting dataset, PointPrompt, and introduce a number of benchmarking tasks that provide an array of opportunities to improve the understanding of the way human prompts differ from automated ones and what underlying factors make for effective visual prompts. We demonstrate that the resulting segmentation scores obtained by humans are approximately 29% higher than those given by automated strategies and identify potential features that are indicative of prompting performance with $R^2$ scores over 0.5. Additionally, we demonstrate that performance when using automated methods can be improved by up to 68% via a finetuning approach. Overall, our experiments not only showcase the existing gap between human prompts and automated methods, but also highlight potential avenues through which this gap can be leveraged to improve effective visual prompt design. Further details along with the dataset links and codes are available at https://github.com/olivesgatech/PointPrompt
Ophthalmic Biomarker Detection: Highlights from the IEEE Video and Image Processing Cup 2023 Student Competition
Aug 20, 2024



The VIP Cup offers a unique experience to undergraduates, allowing students to work together to solve challenging, real-world problems with video and image processing techniques. In this iteration of the VIP Cup, we challenged students to balance personalization and generalization when performing biomarker detection in 3D optical coherence tomography (OCT) images. Balancing personalization and generalization is an important challenge to tackle, as the variation within OCT scans of patients between visits can be minimal while the difference in manifestation of the same disease across different patients may be substantial. The domain difference between OCT scans can arise due to pathology manifestation across patients, clinical labels, and the visit along the treatment process when the scan is taken. Hence, we provided a multimodal OCT dataset to allow teams to effectively target this challenge. Overall, this competition gave undergraduates an opportunity to learn about how artificial intelligence can be a powerful tool for the medical field, as well as the unique challenges one faces when applying machine learning to biomedical data.
Clinical Trial Active Learning
Jul 20, 2023This paper presents a novel approach to active learning that takes into account the non-independent and identically distributed (non-i.i.d.) structure of a clinical trial setting. There exists two types of clinical trials: retrospective and prospective. Retrospective clinical trials analyze data after treatment has been performed; prospective clinical trials collect data as treatment is ongoing. Typically, active learning approaches assume the dataset is i.i.d. when selecting training samples; however, in the case of clinical trials, treatment results in a dependency between the data collected at the current and past visits. Thus, we propose prospective active learning to overcome the limitations present in traditional active learning methods and apply it to disease detection in optical coherence tomography (OCT) images, where we condition on the time an image was collected to enforce the i.i.d. assumption. We compare our proposed method to the traditional active learning paradigm, which we refer to as retrospective in nature. We demonstrate that prospective active learning outperforms retrospective active learning in two different types of test settings.