 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Aware Self-Supervised Learning for Segmentation of Small and Sparse Structures
Jan 26, 2026Self-supervised learning (SSL) has emerged as a powerful strategy for representation learning under limited annotation regimes, yet its effectiveness remains highly sensitive to many factors, especially the nature of the target task. In segmentation, existing pipelines are typically tuned to large, homogeneous regions, but their performance drops when objects are small, sparse, or locally irregular. In this work, we propose a scale-aware SSL adaptation that integrates small-window cropping into the augmentation pipeline, zooming in on fine-scale structures during pretraining. We evaluate this approach across two domains with markedly different data modalities: seismic imaging, where the goal is to segment sparse faults, and neuroimaging, where the task is to delineate small cellular structures. In both settings, our method yields consistent improvements over standard and state-of-the-art baselines under label constraints, improving accuracy by up to 13% for fault segmentation and 5% for cell delineation. In contrast, large-scale features such as seismic facies or tissue regions see little benefit, underscoring that the value of SSL depends critically on the scale of the target objects. Our findings highlight the need to align SSL design with object size and sparsity, offering a general principle for buil ding more effective representation learning pipelines across scientific imaging domains.
A Large-scale Benchmark on Geological Fault Delineation Models: Domain Shift, Training Dynamics, Generalizability, Evaluation and Inferential Behavior
May 13, 2025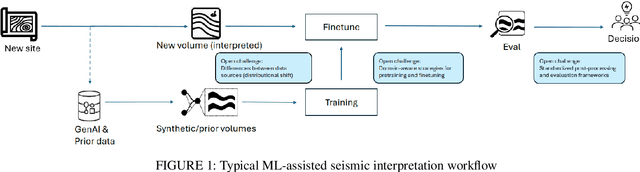
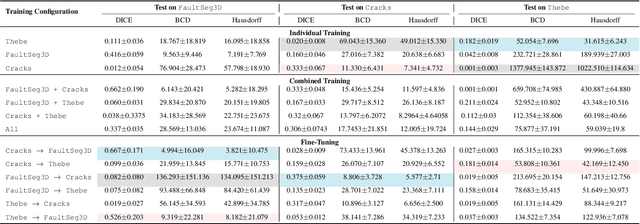
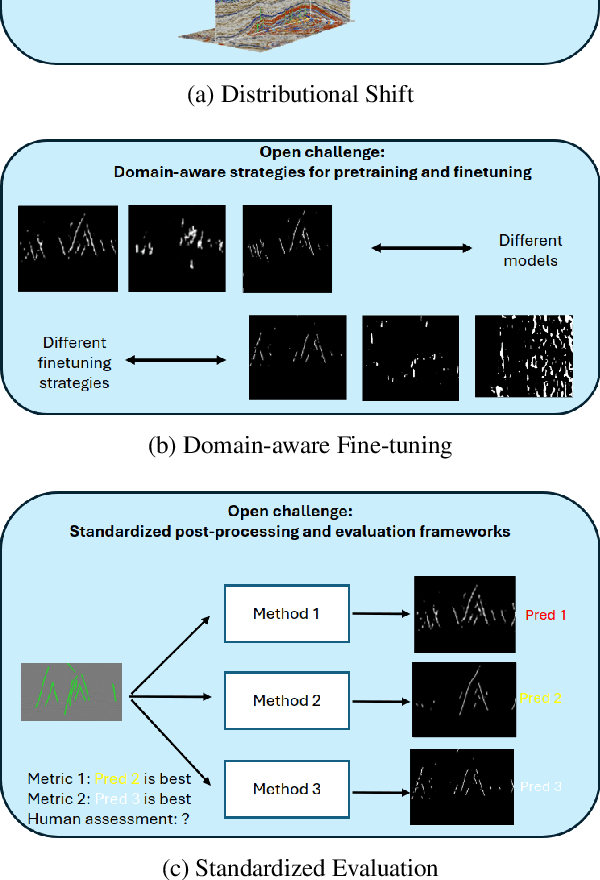
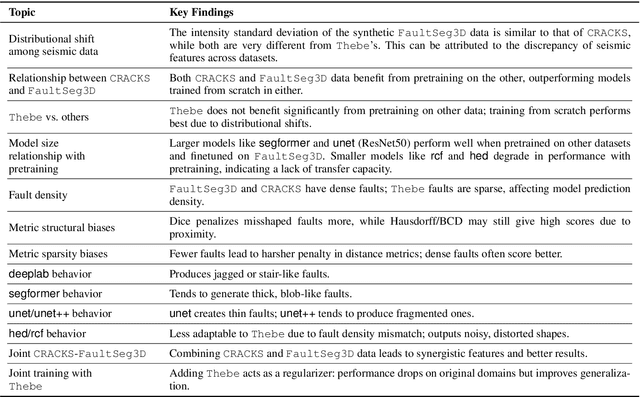
Machine learning has taken a critical role in seismic interpretation workflows, especially in fault delineation tasks. However, despite the recent proliferation of pretrained models and synthetic datasets, the field still lacks a systematic understanding of the generalizability limits of these models across seismic data representing a variety of geologic, acquisition and processing settings. Distributional shifts between different data sources, limitations in fine-tuning strategies and labeled data accessibility, and inconsistent evaluation protocols all represent major roadblocks in the deployment of reliable and robust models in real-world exploration settings. In this paper, we present the first large-scale benchmarking study explicitly designed to provide answers and guidelines for domain shift strategies in seismic interpretation. Our benchmark encompasses over $200$ models trained and evaluated on three heterogeneous datasets (synthetic and real data) including FaultSeg3D, CRACKS, and Thebe. We systematically assess pretraining, fine-tuning, and joint training strategies under varying degrees of domain shift. Our analysis highlights the fragility of current fine-tuning practices, the emergence of catastrophic forgetting, and the challenges of interpreting performance in a systematic manner. We establish a robust experimental baseline to provide insights into the tradeoffs inherent to current fault delineation workflows, and shed light on directions for developing more generalizable, interpretable and effective machine learning models for seismic interpretation. The insights and analyses reported provide a set of guidelines on the deployment of fault delineation models within seismic interpretation workflows.
Benchmarking Human and Automated Prompting in the Segment Anything Model
Oct 29, 2024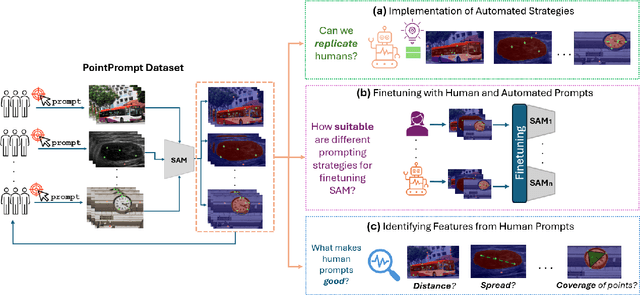

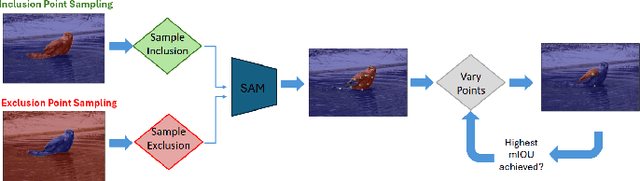
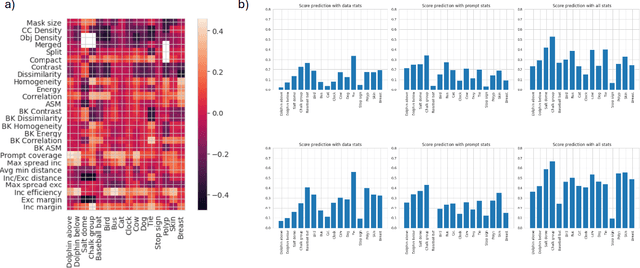
The remarkable capabilities of the Segment Anything Model (SAM) for tackling image segmentation tasks in an intuitive and interactive manner has sparked interest in the design of effective visual prompts. Such interest has led to the creation of automated point prompt selection strategies, typically motivated from a feature extraction perspective. However, there is still very little understanding of how appropriate these automated visual prompting strategies are, particularly when compared to humans, across diverse image domains. Additionally, the performance benefits of including such automated visual prompting strategies within the finetuning process of SAM also remains unexplored, as does the effect of interpretable factors like distance between the prompt points on segmentation performance. To bridge these gaps, we leverage a recently released visual prompting dataset, PointPrompt, and introduce a number of benchmarking tasks that provide an array of opportunities to improve the understanding of the way human prompts differ from automated ones and what underlying factors make for effective visual prompts. We demonstrate that the resulting segmentation scores obtained by humans are approximately 29% higher than those given by automated strategies and identify potential features that are indicative of prompting performance with $R^2$ scores over 0.5. Additionally, we demonstrate that performance when using automated methods can be improved by up to 68% via a finetuning approach. Overall, our experiments not only showcase the existing gap between human prompts and automated methods, but also highlight potential avenues through which this gap can be leveraged to improve effective visual prompt design. Further details along with the dataset links and codes are available at https://github.com/olivesgatech/PointPrompt
CRACKS: Crowdsourcing Resources for Analysis and Categorization of Key Subsurface faults
Aug 20, 2024



Crowdsourcing annotations has created a paradigm shift in the availability of labeled data for machine learning. Availability of large datasets has accelerated progress in common knowledge applications involving visual and language data. However, specialized applications that require expert labels lag in data availability. One such application is fault segmentation in subsurface imaging. Detecting, tracking, and analyzing faults has broad societal implications in predicting fluid flows, earthquakes, and storing excess atmospheric CO$_2$. However, delineating faults with current practices is a labor-intensive activity that requires precise analysis of subsurface imaging data by geophysicists. In this paper, we propose the $\texttt{CRACKS}$ dataset to detect and segment faults in subsurface images by utilizing crowdsourced resources. We leverage Amazon Mechanical Turk to obtain fault delineations from sections of the Netherlands North Sea subsurface images from (i) $26$ novices who have no exposure to subsurface data and were shown a video describing and labeling faults, (ii) $8$ practitioners who have previously interacted and worked on subsurface data, (iii) one geophysicist to label $7636$ faults in the region. Note that all novices, practitioners, and the expert segment faults on the same subsurface volume with disagreements between and among the novices and practitioners. Additionally, each fault annotation is equipped with the confidence level of the annotator. The paper provides benchmarks on detecting and segmenting the expert labels, given the novice and practitioner labels. Additional details along with the dataset links and codes are available at $\href{https://alregib.ece.gatech.edu/cracks-crowdsourcing-resources-for-analysis-and-categorization-of-key-subsurface-faults/}{link}$.
MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jan 01, 2023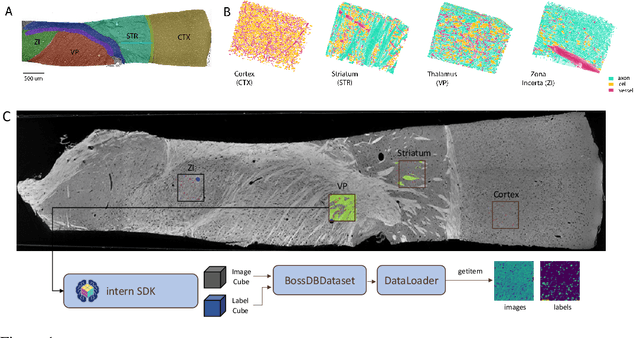
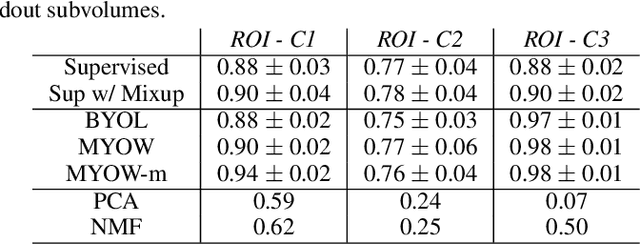

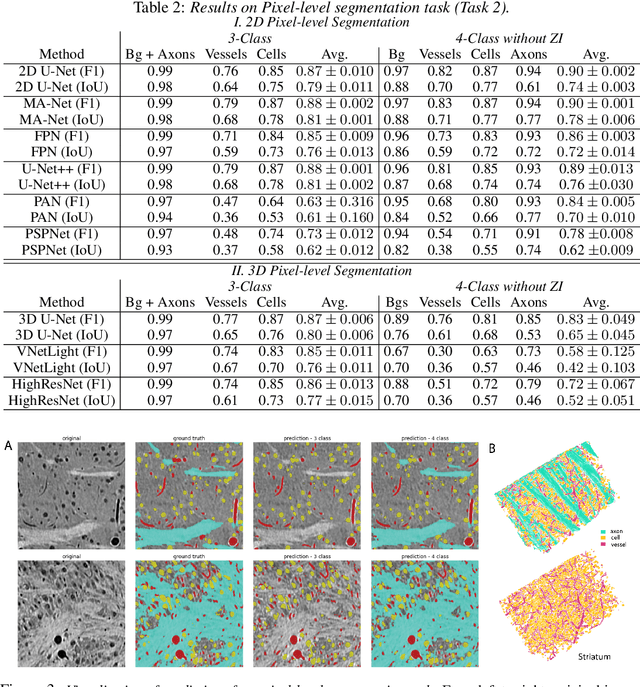
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple attributes of a single image and perform well on a variety of downstream tasks. Datasets, code, and pre-trained baseline models are provided at: https://mtneuro.github.io/ .